LEARNING TO EXPLORE USING ACTIVE NEURAL SLAM 论文阅读
论文信息
题目:LEARNING TO EXPLORE USING ACTIVE NEURAL SLAM
作者:Devendra Singh Chaplot, Dhiraj Gandhi
项目地址:https://devendrachaplot.github.io/projects/Neural-SLAM
代码地址:https://github.com/devendrachaplot/Neural-SLAM
来源:LCLR
时间:2022
Abstract
这项工作提出了一种模块化和分层的方法来学习探索 3D 环境的策略,称为“Active Neural SLAM”。
我们的方法结合了经典方法和基于学习的方法的优势,通过使用带有学习 SLAM 模块的分析路径规划器以及全局和本地策略。
学习的使用提供了输入模式(在 SLAM 模块中)方面的灵活性,利用了世界的结构规律(在全局策略中),并为状态估计中的错误(在本地策略中)提供了鲁棒性。
所提出的模型还可以轻松转移到 PointGoal 任务,并且是 CVPR 2019 Habitat PointGoal 导航挑战赛的获胜作品。
Introduction
虽然使用学习进行探索是有充分动机的,但将探索问题转化为端到端学习问题有其自身的缺点。以端到端的方式纯粹从数据中学习映射、状态估计和路径规划可能会非常困难。因此,Chen 等人(2019)过去用于探索的端到端学习工作依赖于模仿学习和数百万帧经验的使用,但仍然比根本不需要任何训练的经典方法表现更差。
在本文中,我们研究了利用学习进行探索的替代方案,该方案保留了学习必须提供的优势,但没有成熟的端到端学习的缺点。我们的关键概念见解是,使用learning为了对室内环境的结构规律的利用、对状态估计误差的鲁棒性、对输入模式的灵活性。这些发生在不同的时间尺度上,因此可以被分解出来。
我们提出的探索架构由学习神经 SLAM 模块、全局策略和本地策略组成,它们通过地图和分析路径规划器连接。
学习神经 SLAM 模块可生成自由空间地图,并根据输入 RGB 图像和运动传感器估计代理姿势。
全局策略使用代理姿势来占据这个自由空间地图,并利用学习来利用现实世界环境布局中的结构规律来产生长期目标。
这些长期目标用于生成本地政策的短期目标(使用几何路径规划器)。
本地策略使用学习将原始 RGB 图像直接映射到代理应执行的操作。
在 SLAM 模块中使用学习提供了输入模态方面的灵活性,学习的全局策略可以利用现实环境布局中的规律性,而学习的本地策略可以使用视觉反馈来表现出更稳健的行为。
Related Work
Navigation Approaches
经典的导航方法将问题分为两部分:地图绘制和路径规划。
Exploration in Navigation
虽然许多工作专注于被动地图构建、路径规划和目标驱动的策略学习,但一小部分工作解决了主动 SLAM 的问题,即如何主动控制相机来构建地图。
Hierachical and Modular Policies(分层和策略学习)
分层强化学习(Dayan 和 Hinton,1993;Sutton 等,1999;Barto 和 Mahadevan,2003)是一个活跃的研究领域,旨在自动发现层次结构以加速学习。然而,这已被证明具有挑战性,因此大多数工作都诉诸于使用手动定义层次结构。例如,在导航方面,Bansal 等人(2019) 和 Kaufmann 等人 (2019) 设计了用于导航的模块化策略,将学习策略与低级反馈控制器连接起来。分层和模块化策略也已用于嵌入式问答(Das 等人,2018a;Gordon 等人,2018;Das 等人,2018b)。
Task Setup
Actuation and Noise Model(驱动和噪声模型)
我们用 (x, y, o) 表示代理的姿势,假设智能体从 p 0 = ( 0 , 0 , 0 ) p_0 = (0, 0, 0) p0=(0,0,0)开始。现在,假设代理采取行动。每个动作都作为机器人的控制命令来实现。
设相应的控制命令为 Δ u a = ( x a , y a , o a ) Δu_a = (x_a,y_a,o_a) Δua=(xa,ya,oa)。让智能体在动作后的姿势为 p 1 = ( x ∗ , y ∗ , o ∗ ) p_1 = (x^*, y^*, o^*) p1=(x∗,y∗,o∗)。驱动噪声 ( ϵ a c t \epsilon _{act} ϵact) 是动作后的实际代理姿势 ( p 1 p_1 p1) 与预期代理姿势 ( p 0 + Δ u p_0 + Δu p0+Δu) 之间的差异:
ϵ a c t = p 1 − ( p 0 + Δ u ) = ( x ∗ − x a , y ∗ − y a , o ∗ − o a ) \epsilon _{act} = p_1-(p_0+\Delta u)=(x^*-x_a,y^*-y_a,o^*-o_a) ϵact=p1−(p0+Δu)=(x∗−xa,y∗−ya,o∗−oa)
移动机器人通常具有估计机器人移动时的姿势的传感器。令传感器在动作后估计智能体的姿势为 p 1 ′ = ( x ′ , y ′ , o ′ ) p^{\prime}_1 = (x^{\prime}, y^{\prime}, o^{\prime}) p1′=(x′,y′,o′)。传感器噪声 ( ϵ s e n \epsilon _{sen} ϵsen) 由传感器姿态估计 ( p 1 ′ p^{\prime}_1 p1′) 和实际代理姿态 ( p 1 p_1 p1) 之间的差异给出;
ϵ s e n = p 1 ′ − p 1 = ( x ′ − x ∗ , y ′ − y ∗ , o ′ − o ∗ ) \epsilon _{sen} = p^{\prime}_1-p_1=(x^{\prime}-x^*,y^{\prime}-y^*,o^{\prime}-o^*) ϵsen=p1′−p1=(x′−x∗,y′−y∗,o′−o∗)
我们使用三个默认的导航动作:前进:向前移动25厘米,右转:原地顺时针旋转10度,左转:原地逆时针旋转10度。控制命令的实现为:
u F o r w a r d = ( 0.25 , 0 , 0 ) u_{Forward} = (0.25, 0, 0) uForward=(0.25,0,0) u R i g h t : ( 0 , 0 , − 10 ∗ π / 180 ) , u L e f t : ( 0 , 0 , 10 ∗ π / 180 ) u_{Right} : (0, 0, −10∗π/180) , u_{Left} : (0, 0, 10 ∗ π/180) uRight:(0,0,−10∗π/180),uLeft:(0,0,10∗π/180)
Methods
“Active Neural SLAM”。它由三个组件组成:神经 SLAM 模块、全局策略和局部策略,如图 1 所示。神经 SLAM 模块根据当前观察和先前的预测来预测环境地图和代理姿势。全局策略使用预测的地图和代理姿势来产生长期目标。使用路径规划将长期目标转换为短期目标。本地策略根据当前观察采取导航行动以实现短期目标。

Map Representation
Active Neural SLAM 模型内部维护空间图、 m t m_t mt 和智能体 x t x_t xt 的姿态。空间地图 m t m_t mt 是一个 2 × M × M 矩阵,其中 M × M 表示地图大小,该空间地图中的每个元素对应于物理世界中大小为 25cm2 (5cm × 5cm) 的单元。第一个通道中的每个元素表示相应位置处存在障碍物的概率,第二个通道中的每个元素表示正在探索的该位置的概率。当已知单元格是自由空间或障碍物时,就认为该单元格已被探索。空间图在步骤开始时用全零进行初始化, m 0 = [ 0 ] 2 × M × M m_0 = [0]^{2×M×M} m0=[0]2×M×M 。
位姿 x t ∈ R 3 x_t ∈ \mathbb{R}^3 xt∈R3 表示智能体的 x 和 y 坐标以及智能体在时间 t 时的方向。智能体在步骤开始时总是从地图中心面向东开始, x 0 = ( M / 2 , M / 2 , 0.0 ) x_0 = (M/2, M/2, 0.0) x0=(M/2,M/2,0.0)
Neural SLAM Module
Neural SLAM 模块 ( f S L A M f_{SLAM} fSLAM ) 接收当前 RGB 观测值 s t s_t st、当前和上一次传感器获取的智能体姿势 x t − 1 : t ′ x^{\prime}_{t−1:t} xt−1:t′、上一次智能体姿势和地图估计 x ^ t − 1 \hat{x}_{t−1} x^t−1、 m t − 1 m_{t−1} mt−1,并输出更新后的地图 m t m_t mt 和当前代理姿态估计 x ^ t \hat{x}_{t} x^t(见图 2): m t , x ^ t = f S L A M ( s t , x t − 1 : t ′ , x ^ t − 1 , m t − 1 ∣ θ S ) m_t, \hat{x}_t = f_{SLAM}(s_t, x^{\prime}_{t−1:t}, \hat{x}_{t−1}, m_{t−1}|θ_S) mt,x^t=fSLAM(st,xt−1:t′,x^t−1,mt−1∣θS),其中 θ S θ_S θS 表示可训练参数神经SLAM模块。
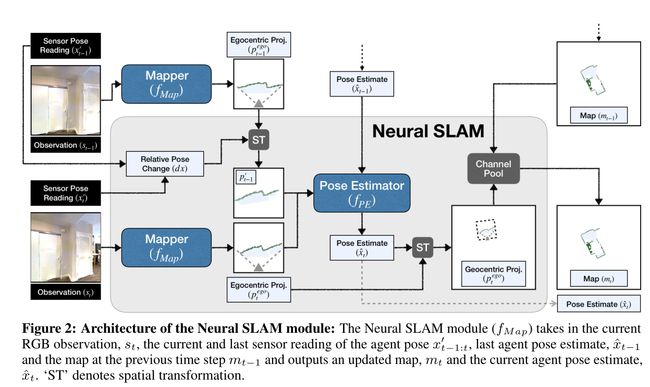
它由两个学习组件组成:映射器和姿势估计器。 Mapper( f M a p f_{Map} fMap)输出一个以自我为中心的自上而下的二维空间图, p t e g o ∈ [ 0 , 1 ] 2 × V × V p^{ego}_t ∈ [0, 1]^{2×V ×V} ptego∈[0,1]2×V×V(其中V是视野范围),预测当前观察中的障碍物和探索区域。姿势估计器 ( f P E f_{PE} fPE) 基于过去的姿势估计 ( x ^ t − 1 \hat{x}_{t-1} x^t−1) 和上一次两个以自我为中心的地图预测 ( p t − 1 : t e g o p^{ego} _{t−1:t} pt−1:tego) 来预测代理姿势 ( x ^ t \hat{x}_{t} x^t)。它本质上是将当前的以自我为中心的地图预测与变换到当前帧的最后以自我为中心的地图预测进行比较,以预测两个地图之间的姿态变化。根据姿势估计器给出的姿势估计,将来自映射器的自我中心地图转换为地心地图,然后与先前的空间地图( m t − 1 m_{t−1} mt−1)聚合以获得当前地图( m t m_t mt)。
Global Policy
Global Policy以 h t ∈ [ 0 , 1 ] 4 × M × M h_t ∈ [0, 1]^{4×M×M} ht∈[0,1]4×M×M为输入,其中ht的前两个通道是SLAM模块给出的空间图 m t m_t mt,第三个通道表示SLAM模块估计的当前代理的位置,第四个通道代表访问过的位置,即
∀ i , j ∈ 1 , 2 , . . . , m ∀i, j ∈ {1, 2,...,m} ∀i,j∈1,2,...,m:

在将 h t h_t ht 传递给全局策略模型之前,我们执行两次转换。第一个变换对来自 h t h_t ht 的智能体周围大小为 4 × G × G 的窗口进行子采样。第二个变换执行最大池化操作以从 h t h_t ht 获得大小为 4×G×G 的输出。这两个变换都堆叠起来形成大小为 8 × G × G 的张量,并作为输入传递到全局策略模型。全局策略使用卷积神经网络来预测 G × G 空间中的长期目标 g t l : g t l = π G ( h t ∣ θ G ) g^l_t:g^l_t = πG(h_t|θ_G) gtl:gtl=πG(ht∣θG),其中 θ G θ_G θG 是全局策略的参数。
Planner
Planner 将长期目标 ( g t l g^l_t gtl)、空间障碍图 ( m t m_t mt) 和 agnet 位姿估计 ( x ^ t \hat{x}_t x^t) 作为输入,计算短期目标 g t s g^s_t gts ,即 g t s = f P l a n ( g t l , m t , x ^ t g^s_t = f_{Plan}(g^l_t, m_t, \hat{x}_t gts=fPlan(gtl,mt,x^t) 。它使用基于当前空间地图 m t m_t mt 的快速行进方法(Sethian,1996)计算从当前代理位置到长期目标( g t l g^l_t gtl)的最短路径。未开发的区域被视为规划的自由空间。我们计算计划路径上的短期目标坐标(距智能体 ds(= 0.25m) 内的最远点)。
Local Policy
本地策略将当前 RGB 观测值 ( s t s_t st) 和短期目标 ( g t s g^s_t gts ) 作为输入,并输出导航操作 a t = π L ( s t , g t s ∣ θ L ) a_t = π_L(s_t, g^s_t |θ_L) at=πL(st,gts∣θL),其中 θ L θ_L θL 是本地策略的参数。短期目标坐标在传递给本地策略之前会转换为距智能体位置的相对距离和角度。本地策略是一个循环神经网络,由预训练的 ResNet18(He 等人,2016)作为视觉编码器组成。
Experiment


扩展
我们提出了一种模块化导航模型,该模型利用了经典和基于学习的导航方法的优势。我们表明,所提出的模型在 Exploration 和 PointGoal 任务上都优于先前的方法,并且显示出跨领域、目标和任务的强大泛化能力。未来,所提出的模型可以通过使用语义神经 SLAM 模块扩展到复杂的语义任务,例如语义目标导航和Ebmbodied问答,该模块创建捕获环境中对象的语义属性的多通道地图。该模型还可以与之前的定位工作相结合,在之前创建的地图中重新定位,以便在后续剧集中进行高效导航。