langchain系列1- langchain-ChatGLM
源码阅读
1 服务启动
(demo.queue(concurrency_count=3).launch(server_name='0.0.0.0',
server_port=7860,
show_api=False,
share=False,
inbrowser=False))
这部分代码使用了 Gradio 库提供的两个函数:queue 和 launch。
在这里,demo 是一个 Interface 类的实例对象,queue 函数用于设置应用程序的并发请求数量。concurrency_count 参数用于指定并发请求数量,以获得更快的处理速度和更好的性能。例如,在这里设置为 3,则表示该应用程序最多可以同时处理三个请求。当超过这个数量时,新请求将被放入队列中等待处理。如果您在开发期间遇到了应用性能的问题,可以根据实际情况适当调整并发请求数量来提高性能。
在队列设置完毕后,launch 函数用于启动 Gradio 应用程序。其中 server_name 和 server_port 参数指定了应用程序的服务器地址和端口号。如果您想要在本地运行应用程序,可以使用默认设置,即将 server_name 设置为 '0.0.0.0',server_port 设置为 7860。show_api 参数用于显示自动生成的 API 文档,share 参数用于共享应用程序链接,inbrowser 参数用于在浏览器中打开应用程序。最后,launch 函数启动应用程序并显示在浏览器中。
2 无状态
大语言模型是无状态的,它并不保存上次交互的内容,chatGPT能够和人正常对话,因为它做了一层包装,把历史记录传回给了模型。
3,本地直接加载模型,和通过api服务的方式对接模型
llm_model_dict = {
"chatglm-6b-int4-qe": {
"name": "chatglm-6b-int4-qe",
"pretrained_model_name": "THUDM/chatglm-6b-int4-qe",
"local_model_path": None,
"provides": "ChatGLM"
},
"chatglm-6b-int4": {
"name": "chatglm-6b-int4",
"pretrained_model_name": "THUDM/chatglm-6b-int4",
"local_model_path": None,
"provides": "ChatGLM"
},
"chatglm-6b-int8": {
"name": "chatglm-6b-int8",
"pretrained_model_name": "THUDM/chatglm-6b-int8",
"local_model_path": None,
"provides": "ChatGLM"
},
"chatglm-6b": {
"name": "chatglm-6b",
"pretrained_model_name": "THUDM/chatglm-6b",
"local_model_path": "/chatglm-6b",
"provides": "ChatGLM"
},
"chatyuan": {
"name": "chatyuan",
"pretrained_model_name": "ClueAI/ChatYuan-large-v2",
"local_model_path": None,
"provides": None
},
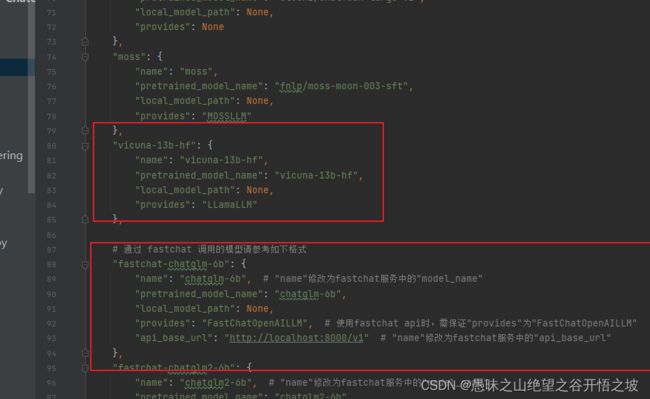
"moss": {
"name": "moss",
"pretrained_model_name": "fnlp/moss-moon-003-sft",
"local_model_path": None,
"provides": "MOSSLLM"
},
"vicuna-13b-hf": {
"name": "vicuna-13b-hf",
"pretrained_model_name": "vicuna-13b-hf",
"local_model_path": None,
"provides": "LLamaLLM"
},
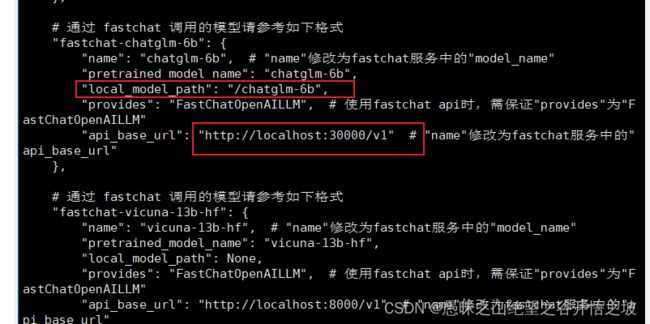
# 通过 fastchat 调用的模型请参考如下格式
"fastchat-chatglm-6b": {
"name": "chatglm-6b", # "name"修改为fastchat服务中的"model_name"
"pretrained_model_name": "chatglm-6b",
"local_model_path": "/chatglm-6b",
"provides": "FastChatOpenAILLM", # 使用fastchat api时,需保证"provides"为"FastChatOpenAILLM"
"api_base_url": "http://localhost:30000/v1" # "name"修改为fastchat服务中的"api_base_url"
},
# 通过 fastchat 调用的模型请参考如下格式
"fastchat-vicuna-13b-hf": {
"name": "vicuna-13b-hf", # "name"修改为fastchat服务中的"model_name"
"pretrained_model_name": "vicuna-13b-hf",
"local_model_path": None,
"provides": "FastChatOpenAILLM", # 使用fastchat api时,需保证"provides"为"FastChatOpenAILLM"
"api_base_url": "http://localhost:8000/v1" # "name"修改为fastchat服务中的"api_base_url"
},
}
config配置
一键部署启动服务的脚本,start_service.sh
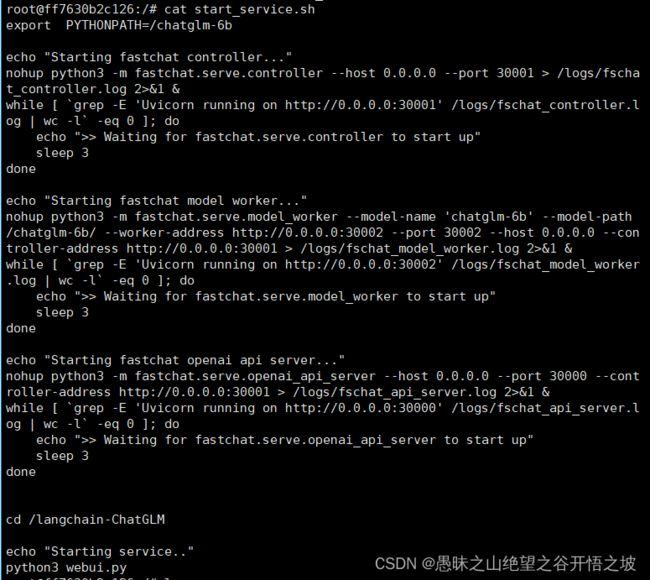
export PYTHONPATH=/chatglm-6b
echo "Starting fastchat controller..."
nohup python3 -m fastchat.serve.controller --host 0.0.0.0 --port 30001 > /logs/fschat_controller.log 2>&1 &
while [ `grep -E 'Uvicorn running on http://0.0.0.0:30001' /logs/fschat_controller.log | wc -l` -eq 0 ]; do
echo ">> Waiting for fastchat.serve.controller to start up"
sleep 3
done
echo "Starting fastchat model worker..."
nohup python3 -m fastchat.serve.model_worker --model-name 'chatglm-6b' --model-path /chatglm-6b/ --worker-address http://0.0.0.0:30002 --port 30002 --host 0.0.0.0 --controller-address http://0.0.0.0:30001 > /logs/fschat_model_worker.log 2>&1 &
while [ `grep -E 'Uvicorn running on http://0.0.0.0:30002' /logs/fschat_model_worker.log | wc -l` -eq 0 ]; do
echo ">> Waiting for fastchat.serve.model_worker to start up"
sleep 3
done
echo "Starting fastchat openai api server..."
nohup python3 -m fastchat.serve.openai_api_server --host 0.0.0.0 --port 30000 --controller-address http://0.0.0.0:30001 > /logs/fschat_api_server.log 2>&1 &
while [ `grep -E 'Uvicorn running on http://0.0.0.0:30000' /logs/fschat_api_server.log | wc -l` -eq 0 ]; do
echo ">> Waiting for fastchat.serve.openai_api_server to start up"
sleep 3
done
cd /langchain-ChatGLM
echo "Starting service.."
python3 webui.py
解释wc
Linux wc命令用于计算字数。
利用wc指令我们可以计算文件的Byte数、字数、或是列数,若不指定文件名称、或是所给予的文件名为"-",则wc指令会从标准输入设备读取数据。
语法
wc [-clw][--help][--version][文件...]
参数:
-c或--bytes或--chars 只显示Bytes数。
-l或--lines 显示行数。
-w或--words 只显示字数。
--help 在线帮助。
--version 显示版本信息。
实例
在默认的情况下,wc将计算指定文件的行数、字数,以及字节数。使用的命令为:
wc testfile
$ wc testfile # testfile文件的统计信息
3 92 598 testfile # testfile文件的行数为3、单词数92、字节数598
grep
Linux grep (global regular expression) 命令用于查找文件里符合条件的字符串或正则表达式。
grep 指令用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设 grep 指令会把含有范本样式的那一列显示出来。若不指定任何文件名称,或是所给予的文件名为 -,则 grep 指令会从标准输入设备读取数据。
语法
grep [options] pattern [files]
linux指令:https://www.runoob.com/linux/linux-command-manual.html
解释
需要启动三个进程,主要是为了构建一个完整的聊天机器人应用程序,这个程序需要由多个服务组成,每个服务负责不同的职责。
具体来说,这三个进程分别为:
-
快速聊天控制器:这个进程是整个聊天机器人应用的核心,处理来自不同客户端的请求,并将它们交给模型工作器进行处理。通过将控制器与模型解耦,可以轻松添加其他模型和功能,从而实现更多的自然语言处理应用。
-
快速聊天模型工作器: 这个进程负责文本生成,它将从快速聊天控制器接收请求,为请求生成自然语言响应,并将响应发送回控制器。模型工作者实际上是对训练模型进行了封装,提供了一个简单的接口,用于生成文本响应。
-
快速聊天 OpenAI Api 服务器: 这个进程是用来管理第三方服务的,例如 OpenAI API,可以发送 HTTP 请求,将文本请求发送到 OpenAI API,并将响应作为自然语言回答。可以通过 API 服务器将多个快速聊天模型工人和其他命令行工具集成到一个应用程序中。
总之,这三个进程协作工作,为快速构建复杂的聊天机器人应用程序提供了便利。它们共同实现了聊天机器人的听、思考和说的完整过程,同时提供了管理聊天机器人的脚手架,如调度、监控、日志记录和 Web 前端等。
指令
-
-E表示在 grep 命令中使用扩展正则表达式。它允许 grep 支持更多的正则表达式语法,例如|表示或,()表示分组等。换句话说,使用-E参数可以使 grep 命令更加强大和灵活。 -
wc -l的作用是计算文件中的行数。wc 命令(Word Count)可以统计文件的行数、单词数和字符数。命令中的-l参数表示只计算行数,不包括单词数和字符数。因此,这个命令的输出是日志文件中符合条件的行数。
综上所述,这行命令的作用是搜索日志文件 /logs/fschat_api_server.log,查找包含字符串 'Uvicorn running on http://0.0.0.0:30000' 的行数,如果找到的行数为 0,则表示启动 fastchat OpenAI API 服务器失败,需要等待。
gradio
with gr.Row():
num_boxes = gr.Slider(0, 5, 2, step=1, label="Number of boxes")
num_segments = gr.Slider(0, 5, 1, step=1, label="Number of segments")
with gr.Row():
img_input = gr.Image()
img_output = gr.AnnotatedImage().style(
color_map={"banana": "#a89a00", "carrot": "#ffae00"}
)
这段代码主要是使用了 Gradio 中的两个图像处理控件: img_input 用于展示输入图像,img_output 用于展示输出图像,并且增加了两个滑块,用于控制图像的变化,分别为 num_boxes 和 num_segments,两个滑块的初始值分别为 2 和 1。
具体来看:
1、使用 gr.Row() 创建了一个行对象,并使用 gr.Slider() 创建了两个滑块。
num_boxes = gr.Slider(0, 5, 2, step=1, label="Number of boxes")
num_segments = gr.Slider(0, 5, 1, step=1, label="Number of segments")
第一个滑块用于控制生成图像中的盒子数量,取值范围为 0-5,初始值为 2,步长为 1。第二个滑块用于控制生成图像中每个盒子的分段数量,取值范围同样为 0-5,初始值为 1,步长为1。
2、使用 gr.Row() 创建了另一个行对象,并使用 gr.Image() 和 gr.AnnotatedImage() 控件分别存放输入图像和输出图像。
img_input = gr.Image()
img_output = gr.AnnotatedImage().style(
color_map={"banana": "#a89a00", "carrot": "#ffae00"}
)
其中 img_input 控件用于展示待处理的原始图像,img_output 控件用于展示经过模型处理后的图像,并通过 style 方法设置了颜色映射(color_map)为“banana”和“carrot”,分别对应标注中的两种不同类型的水果。
3、最后将这些控件和滑块添加到 Gradio 应用程序中,即可实现交互式地控制和展示输入和输出图像。
with gr.Row()是干嘛的,一定需要吗
with gr.Row() 是一个 Gradio 中的 UI 布局控件,用于在 Gradio 应用程序中创建一个水平的布局行控件,可以把多个控件按照顺序排列在同一行上。
在这个例子中,应该是使用 with gr.Row() 创建了一个行对象,并在其中添加了 num_boxes 和 num_segments 两个滑块控件。这些控件会被顺序排列在该行上,从而使用户能够快速地在同一个位置上操作这两个控件,与其它控件分开。
需要注意的是,with gr.Row() 并不是必须的,如果以其他控件为起点建立分组效果和另一种布局方式也可以起到提供水平排列效果的作用。只要按照所需的排列方式来设置前端界面即可。
with gr.Blocks() as demo:
with gr.Column(variant="panel"):
with gr.Row(variant="compact"):
text = gr.Textbox(
label="Enter your prompt",
show_label=False,
max_lines=1,
placeholder="Enter your prompt",
).style(
container=False,
)
btn = gr.Button("Generate image").style(full_width=False)
gallery = gr.Gallery(
label="Generated images", show_label=False, elem_id="gallery"
).style(columns=[2], rows=[2], object_fit="contain", height="auto")
btn.click(fake_gan, None, gallery)这里面的colum和row是必须的吗
columns 和 rows 是 gr.Gallery() 控件中一个可选的风格参数,用于设置生成的图片在前端展示时的排版布局,分别表示列数和行数。在该例子中,设置 columns=[2] 和 rows=[2],使得生成的四张图片被分成了两行两列的排版,据此达到了更为美观的布局效果。
这些参数是可选的,如果不指定这些参数时,Gradio 会根据控件默认的显示布局自动调整宽度和高度,而这种自适应的展示方式可能会出现不同浏览器之间不一致的情况。因此,如果需要精确定制 Gallery 控件的布局,可以通过设置 columns 和 rows 参数来实现。
with gr.Tab("对话"):
with gr.Row():
with gr.Column(scale=10):
chatbot = gr.Chatbot([[None, init_message], [None, model_status.value]],这里面的tab有什么用
with gr.Tab() 是 Gradio 中的界面控件,用于创建具有标签页视图的容器,允许将内容组织成多个可切换的选项卡,从而使得应用程序的交互界面更加整洁、有条理,并且易于用户进行探索。
在给出的代码中,使用 with gr.Tab("对话") 创建了一个标签页控件,标签页的标题为“对话”,并将 chatbot 对话机器人放入标签页中,从而实现了一个简单而直观的对话系统,并且使得用户可以探索不同的任务和功能。
当然,Gradio 也提供了一些其他的布局控件,例如 gr.Group() 和 gr.Panel() 等,可以根据应用程序的需要选择不同的布局方式和组件。
输入可以和函数保持一致,输出就不需要了
定义的组件,主要就两大类,显示的组件和触控的组件,以什么方式显示,以什么方式触控
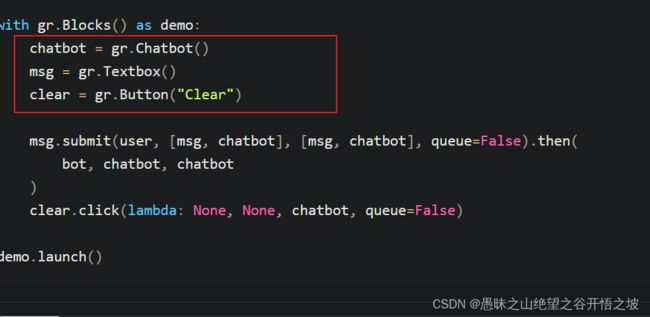
先定义显示,后定义按钮,submit相当于回车键输入
gradio中,gr.State() 函数的作用
这段代码创建了两个 Gradio 状态对象 history 和 past_key_values,用于存储聊天历史记录和键值对数据。这些状态对象是通过执行 gr.State() 函数来创建的,其参数 [] 和 None 分别作为初始值。
在后续的程序中,这两个状态对象被用来在处理函数之间进行共享数据,以便实现不同处理函数之间的数据交换。例如,在 predict() 函数中,我们可以使用 history.value 和 past_key_values.value 来访问和更新这些状态对象中存储的数据。
需要注意的是,与 FastAPI 中状态对象的作用类似,Gradio 中状态对象也可以用于在请求处理之间共享数据。不同之处在于,Gradio 的状态对象主要用于跨用户会话和跨模型调用共享数据,而 FastAPI 的状态对象主要用于跨处理函数共享数据。此外,Gradio 中的状态对象实际上是一个类实例,常用的属性包括 value(状态对象的值)、clear()(清空状态对象)等。
gr.State() 是 Gradio 框架中用于创建状态存储对象的工具函数,它可以帮助我们在不同的函数之间共享数据,实现灵活的界面交互和数据交换。具体而言,gr.State() 函数可以帮助我们创建一个存储状态数据的对象,并将其传递给处理函数。这个状态对象可以在不同的请求调用之间保持持久性,以便存储和访问数据。
通常情况下,在 Gradio 中,我们会使用 gr.State() 函数来创建一些常用的状态对象,如历史记录、键值对、用户会话等。这些状态对象可以在不同的接口函数之间传递数据,并且可以在整个应用程序的生命周期内保持持久状态。
常见的 Gradio 状态对象的使用示例如下:
history = gr.State([])
past_key_values = gr.State(None)
def my_interface():
# some code ...
history.value.append(user_input)
past_key_values.value = key_values
在上面的示例中,我们定义了两个状态对象 history 和 past_key_values,分别用于存储历史记录和键值对数据。在后续的接口函数中,我们可以通过引用这些状态对象,并访问其 value 属性,实现状态数据的存储和读取。例如,在上面的代码中,我们使用 history.value.append() 和 past_key_values.value 来更新和访问这些状态对象中存储的数据。
需要注意的是,与 FastAPI 中的状态对象类似,Gradio 中的状态对象在不同的接口函数之间共享数据时需要注意线程安全、数据同步等问题。此外,Gradio 的状态对象实际上是一个类实例,常用的属性包括 value(状态对象的值)、clear()(清空状态对象)等。
gradio中,scale的理解
with gr.Row(scale=1):
user_input = gr.Textbox(show_label=False, placeholder="Input...", lines=5).style(
container=False)
with gr.Row(min_width=32, scale=3):
submitBtn = gr.Button("Submit", variant="primary")这里面的1和3是什么意思
在这段代码中,scale 参数用于控制一个元素在其父容器中所占的相对比例。
具体来说,代码中 Row 是一个容器对象,用于水平排列多个列容器或其他元素。在这个容器中,我们又创建了两个 Row 容器对象,分别用于放置 Textbox 和 Button 元素。
在第一个 Row 容器中,我们指定了 scale=1,表示该容器在其父容器中占据 1 份。在这个容器内部,我们放置了一个 Textbox 元素,并将其样式设置为 container=False,以避免出现不必要的包装元素。换句话说,这个 Row 容器只包含一个 Textbox 元素,并占据了父容器的 1/4(即 25%)宽度。
在第二个 Row 容器中,我们指定了 min_width=32,scale=3,表示该容器在其父容器中占据 3 份,且至少需要 32 像素宽度。在这个容器内部,我们放置了一个 Button 元素,用于向 Chatbot 提交用户的输入。换句话说,这个 Row 容器只包含一个 Button 元素,并占据了父容器的 3/4(即 75%)宽度。
综上,这里的 scale=1 和 scale=3 分别表示各自元素在其父容器中所占的相对比例,用于实现灵活的布局效果。