链式存储【C语言单链表】
文章目录
-
- 单链表
-
- 单链表的结构
- 需要的头文件
- 申请节点
- 单链表尾插
- 单链表头插
- 单链表尾删
- 单链表头删
- 单链表查找
-
- 单链表在(pos之前/pos之后)插入数据
- 单链表删除(pos/pos之后)数据
- 单链表销毁
- 单链表的缺点
-
- 结尾
单链表
开局迫害下顺序表:
第一、顺序表因为地址是连续的,所以当扩容空间给小了,会出现频繁扩容的问题,而realloc有可能会异地扩容,时间开销就会比较大。当空间给大用不完时还有空间浪费的问题。
第二、假设使用顺序表时,有一次入了100个数据,那么顺序表至少会被占用100个空间的大小,但有一次100个数据里我有99个不用了,删掉了99个数据,只保留了1个数据。那后面99个数据的地址空间依然不会被销毁,有点占着茅坑不拉翔的意思,面对这种情况造成的空间浪费问题就非常恶心。
那么为了解决顺序表的空间浪费的问题,有人就想:如果我用一个数据开一块空间,当我不想使用了就把它释放了,这不就没有空间浪费了吗?本着这种思想,链表就诞生了,链表有8种类型的结构,其中链表中结构最简单的就属单链表了,那么这篇文章的主角就是讲单链表。
单链表的结构
单链表是由数据和一个后继指针两个成员组成的结构体。数据主要用来存放某个数据类型的数据,由于malloc的节点不一定是连续的,而是随机的在堆区找一块空闲的空间,所以链表需要用一个后继指针来存放链表下一个数据位置的地址,从而才能找到下一个节点。每个数据我们都可以称为一个节点(结点)。为了知道链表从哪里开始我们还需要用到一个头结点,有头结点记录链表开始位置就可以找到其他的结点。(下图黑猫警长的鼩鼱(qú jīng))橘猫抓住了一只鼩鼱就揪出了一群鼩鼱。
在逻辑结构上,单链表就类似于现实生活的火车一样,每节车厢都是由车厢之间的车钩连接着一样,如果车钩断了就不能去到下一节车厢。

单链表结构体。
// 为了方便修改数据类型,对类型重命名
typedef int SLTDateType;
typedef struct SListNode
{
SLTDateType data;
struct SListNode* next;
}SListNode;
需要的头文件
#include申请节点
因为尾插和头插都需要malloc结点,干脆将它封装成一个函数使用更加方便。怎么实现全在码里:
// 申请一个结点
SListNode* BuySListNode(SLTDataType x)
{
SListNode* newnode = (SListNode*)malloc(sizeof(SListNode));
// 申请失败
assert(newnode);
// 数据初始化
newnode->data = x;
newnode->next = NULL;
return newnode;
}
单链表尾插
单链表不需要初始化,当想插入元素时直接传一个SListNode类型的空指针就可以了。
注意:因为SListNode传的是链表的头结点,要改变头指针的指向时要用到二级指针。
有些C语言的书上函数参数会这么写:
void SListPushBack(SListNode*& pplist, SLTDateType x)
球球了,这是C++的写法,这里的 & 不是取地址,不是取地址,不是取地址,谢谢!!!是C++的引用,引用是对plist这个指针取的一个别名,就相当于这个指针的一个小名,这里也不多讲,了解下就行,C语言是不存在这种写法的。

C语言正确的传参应该是传二级指针,其实传二级指针也只是为了能改变头结点的指向。其他情况,后继节点都可以通过头结点找到他们的位置,而不需要二级指针。
当个头结点为空时,表示一个结点都没有,此时对二级指针解一次引用就能找到头结点指针地址位置,对它修改才能影响实参。
当头结点不为空,说明链表至少有一个结点,找到链表的尾部后进行插入数据,插入完成。
动画演示

尾插代码
void SListPushBack(SListNode** pplist, SLTDataType x)
{
// 取结点
SListNode* newnode = BuySListNode(x);
// 一个结点都没有
if (*pplist == NULL)
{
// 传二级的原因
*pplist = newnode;
}
else
{
// 头结点的正常情况
SListNode* tail = *pplist;
while (tail->next)
{
tail = tail->next;
}
tail->next = newnode;
}
}
尾插时间复杂度
因为每次尾插都要找到最后一个结点的位置,也就是遍历链表,那么尾插的时间复杂度就是O(N),如果结构体定义了一个尾指针记录下尾的位置,时间复杂度就是O(1)。定义尾指针也只是解决尾插的问题,不能解决尾删的问题。
单链表头插
单链表头插十分方便,申请一个新的结点,将后继指针连接当前头结点,再将头结点给新的结点,头插就算完了。
动画演示

// 单链表的头插
void SListPushFront(SListNode** pplist, SLTDataType x)
{
SListNode* newnode = BuySListNode(x);
newnode->next = *pplist;
*pplist = newnode;
}
头插时间复杂度
链表头插一步到位,妥妥的O(1)。
单链表尾删
因为了链表地址的不连续,使单链表尾删不太方便,只能去遍历链表。
但是你以为单纯的遍历链表就完了吗?没有 ! !
尾插要注意的几个小点
第一、当把最后一个结点给删除,是将原来向操作系统申请的空间还给了操作系统,但是这块空间依然存在。这会导致当把最后一个结点free掉之后,它的前一个结点的后继指针依然指向这块不合法的空间,下一次遍历链表时会有非法访问的问题。
所以在删除结点时,应该记录下最后一个结点的前一个结点,在删除最后一个结点时,还要将前一个结点的后继指针置空。
第二、遍历链表要找最后一个元素,需要一个前结点指针记录前一个结点位置,刚开始前结点不知道初始化什么,所以会将它先置空。
到这里问题就来了,如果链表只有一个元素,去遍历最后一个结点的条件必须是tail的下一个结点next不为空,当找到tail的next停下时,tail会停在最后一个结点才能把最后一个结点删除。因为链表只有一个结点时循环压根不会进去,前结点还是空指针,这时候对prev的next置空就造成了对空指针的非法访问。所以要对只有一个结点进行一个单独的处理。
动画演示

尾删代码
// 单链表的尾删
void SListPopBack(SListNode** pplist)
{
if (*pplist == NULL)
{
// 没有结点
return;
}
else if ((*pplist)->next == NULL)
{
//只有一个节点
free(*pplist);
*pplist = NULL;
}
else
{
// 一个以上结点
SListNode* tail = *pplist;
SListNode* prev = NULL;
while (tail->next)
{
prev = tail;
tail = tail->next;
}
free(tail);
prev->next = NULL;
}
}
尾删时间复杂度
单链表尾删数据要找前结点只能去遍历链表,这也是为什么说即使有尾指针也没有办法去解决尾删的问题,遍历链表时间复杂度是O(N)。
单链表头删
单链表头删和后插一样舒服,把头结点给下一个就ok了,不用担心只有一个结点,就算只有一个结点头结点的下一个结点是空,一样把头结点给空刚好全部删完。
就是要注意如果链表已经是空了,就不能再删了,否则会对空指针解引用。
动画演示

头删代码
// 单链表头删
void SListPopFront(SListNode** pplist)
{
if (*pplist == NULL)
{
return;
}
SListNode* next = (*pplist)->next;
free(*pplist);
*pplist = next;
}
单链表查找
查找就没啥好说的了,遍历链表一个一个比较数据,数据相等返回结点,找不到返回空指针就行。查找也可以在找到之后直接对数据进行修改,所以修改也可以不独立成一个函数。
动画演示
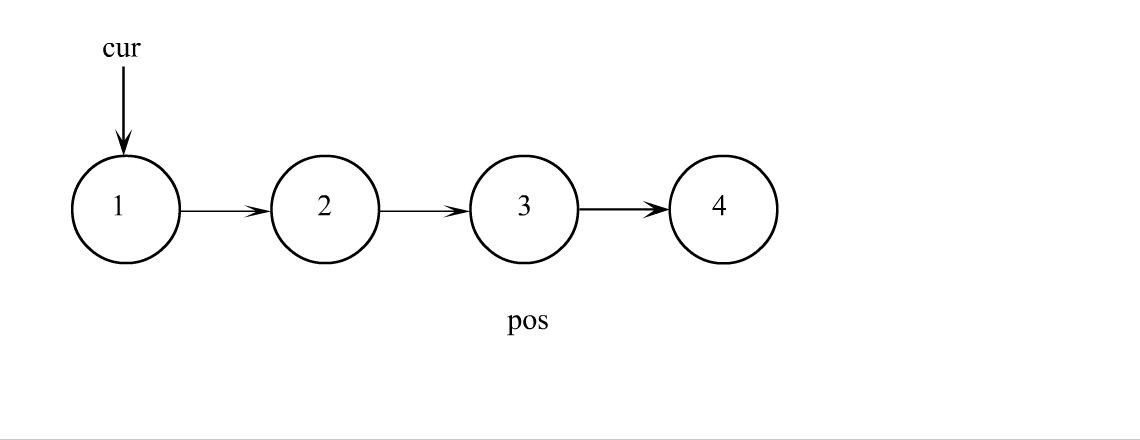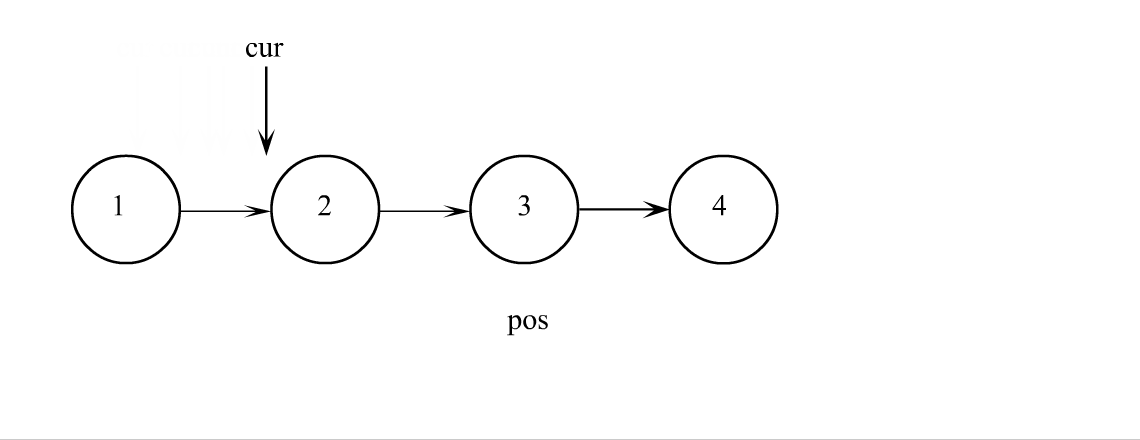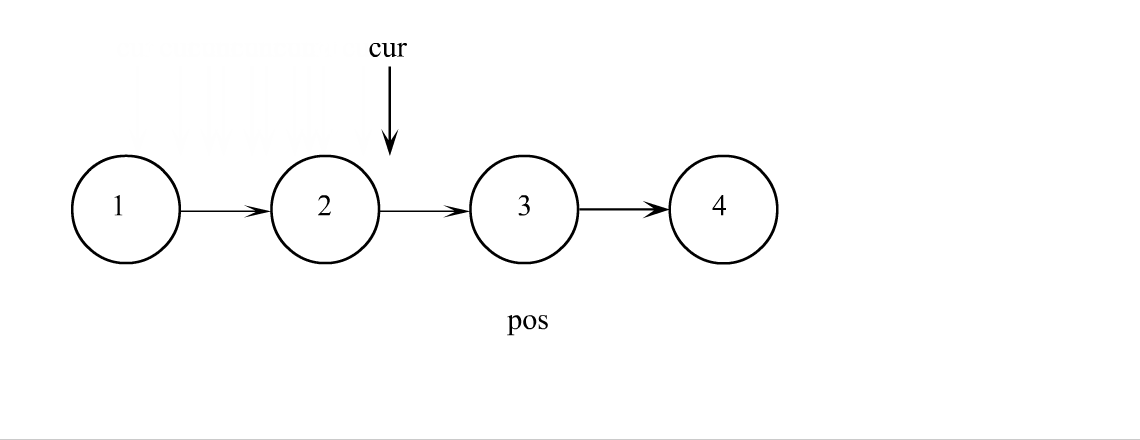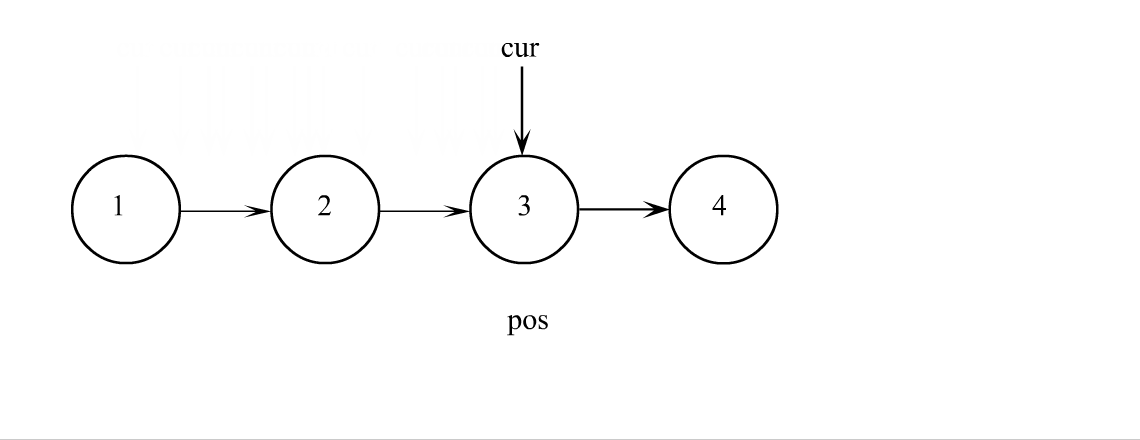
查找代码
// 单链表查找
SListNode* SListFind(SListNode* plist, SLTDataType x)
{
SListNode* cur = plist;
while (cur)
{
if (cur->data == x)
{
// 数据相等返回结点
return cur;
}
cur = cur->next;
}
// 找不到
return NULL;
}
单链表在(pos之前/pos之后)插入数据
C++库里的单链表提供的就是InsertAfter,那么为什么不在pos之前插入?
如果要在pos之前插入数据。因为单链表只能向后查找,所以想要在pos前面插入数据就必须记录一个前结点,才能让前结点的后继指针指向的是新结点,让链表连接起来。要找到前结点就还要再去遍历一次链表。
还会带来两个问题:
第一、如果pos是尾结点,在pos之前插入还需要遍历链表,如果在后面插入就不会有这个问题。
第二、如果pos是头结点,要在pos之前插入就相当于一次头插,头插要改变头指针还要传二级指针,事情就麻烦起来了。
所以在pos之后插入肯定是在pos之前插入是要优的。
pos之前插入
void SListInsertAfter(SListNode** pplist, SListNode* pos, SLTDataType x)
{
assert(pplist);
assert(pos);
if (*pplist == pos)
{
// 头插
SListPushFront(pplist, x);
}
else
{
// prev找pos
SListNode* prev = *pplist;
while (prev->next != pos)
{
prev = prev->next;
}
SListNode* newnode = BuySListNode(x);
SListNode* next = prev->next;
prev->next = newnode;
newnode->next = next;
}
}
InsertAfter主要配合于Find函数,在pos之后插入也会比较舒服,不必考虑找不到前结点找不到的问题,可以直接传结点。
方式一、先用指针记录下pos结点的next,然后连接链表,这种方式优势在于不用考虑先后的顺序问题。
方式二、必须先让newnode的next先指向pos的next,才能保证能找到之后的结点,才能让pos连接newnode。
动画演示
pos之后插入
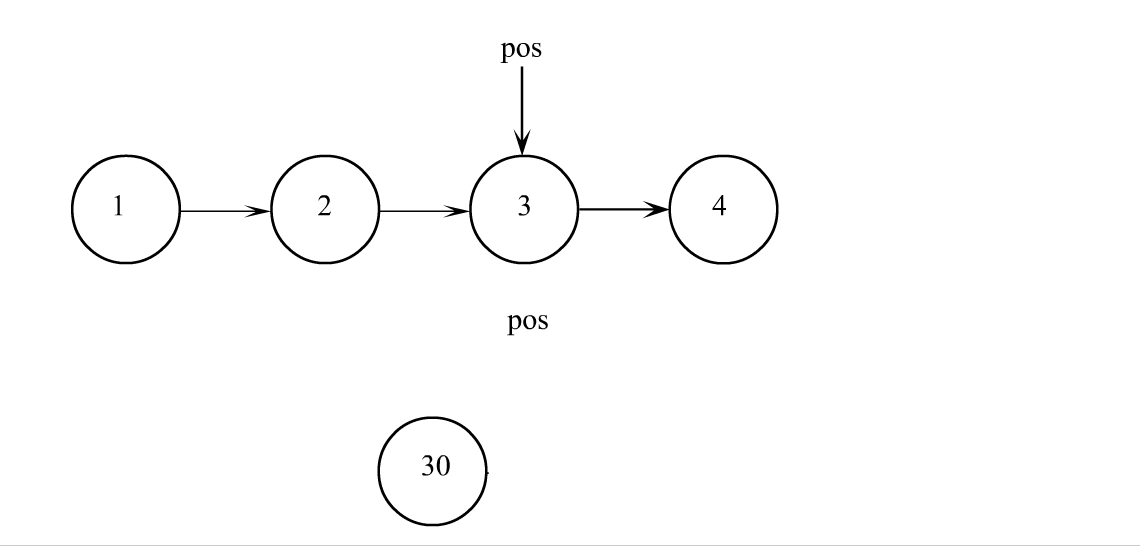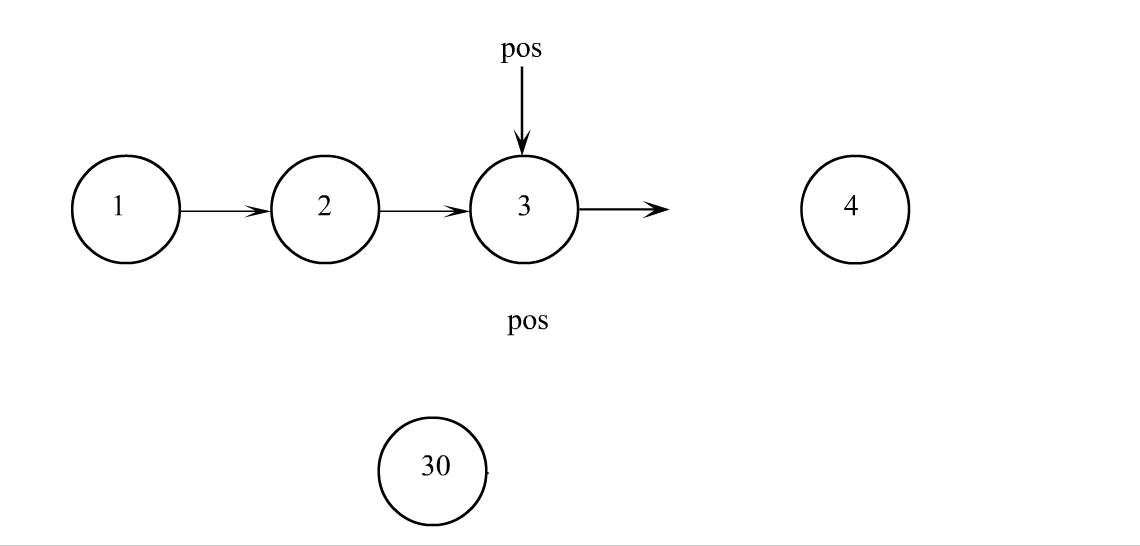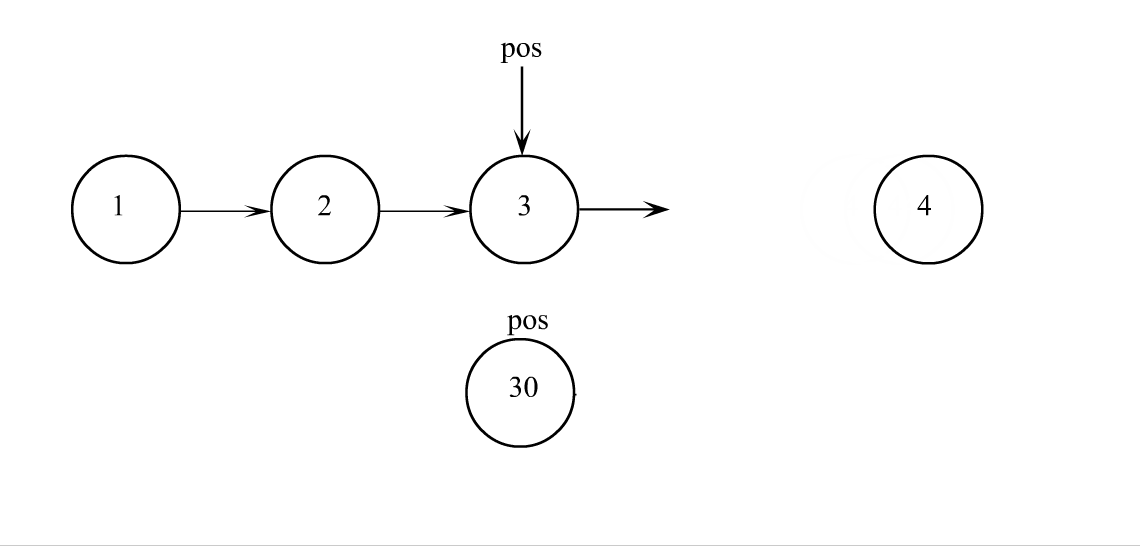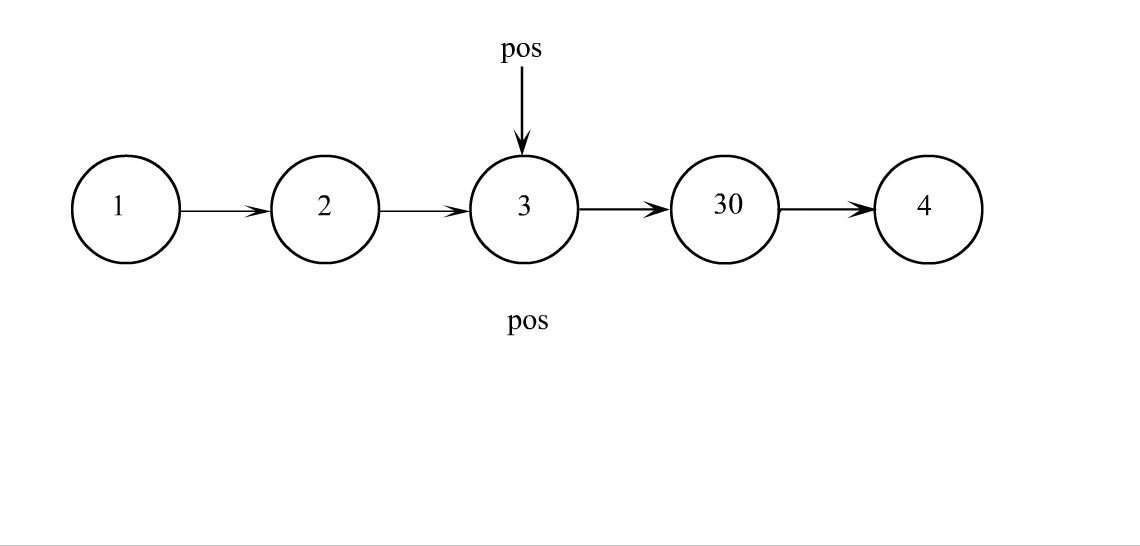
// 单链表在pos位置之后插入x
void SListInsertAfter(SListNode* pos, SLTDataType x)
{
assert(pos);
SListNode* newnode = BuySListNode(x);
// 先记录下个结点位置
SListNode* next = pos->next;
pos->next = newnode;
newnode->next = next;
// 注意顺序
// newnode->next = pos->next;
//pos->next = newnode;
}
两种方式时间复杂度
向前插入要找prev前结点指针,所以要遍历,时间复杂度O(N)。
向后插入直接向结点之后插入结点,时间复杂度O(1)。
单链表删除(pos/pos之后)数据
同样的,为什么不直接删除pos位置,还要这么麻烦删除pos之后的数据。
其实就和前面的InsertAfter一样,如果要删除pos位置还需要找前结点。如果pos是头结点就相当于一次头删,还要传二级指针。
删除pos
// 删除pos位置
void SListErase(SListNode** pplist, SListNode* pos, SLTDataType x)
{
assert(pplist);
assert(pos);
if (*pplist == pos)
{
// 头删
SListPopFront(pplist);
}
else
{
SListNode* prev = *pplist;
while (prev->next != pos)
{
prev = prev->next;
}
SListNode* newnode = BuySListNode(x);
SListNode* next = prev->next;
prev->next = newnode;
newnode->next = next;
}
}
相比要删除pos,删除pos之后的数据写起来就比较,不需要在遍历链表,也不用考虑头结点的情况,虽然有些怪怪的,找pos却要删pos后面的数据
动画演示

删除pos之后
// 单链表删除pos位置之后的值
void SListEraseAfter(SListNode* pos)
{
assert(pos);
SListNode* next = pos->next;
pos->next = next->next;
free(next);
}
两种方式时间复杂度
删除pos位置要找前结点,所以是O(N)。
删除pos之后不需要找前结点,直接删除连接删除结点的后继指针,所以是O(1)。
单链表销毁
不同于顺序表,顺序表是由系统一次性开好的,可以直接free掉整个数组,链表是一个一个开辟出来的,也就需要一个结点一个结点的释放。
可以传二级指针,在函数将头结点置空,也可以传一级指针,在函数外置空头结点。
链表销毁
// 单链表的销毁
void SListDestory(SListNode** pplist)
{
SListNode* cur = *pplist;
while (cur)
{
SListNode* next = cur->next;
free(cur);
cur = next;
}
*pplist = NULL;
}
单链表的缺点
既然都说了顺序表的缺点那也说下单链表的缺点吧
第一、单链表的地址不是连续,不适合用来做排序,排序顺序表数组有先天性的优势。
第二、单链表结构简单,这既是它的优点也是缺点,因为结构太过于简单,单链表只有后继结点,导致单链表只能向后查找,如果要向前查找不方便,双向链表有前结点可以解决这个问题。
结尾
ps.画图太累了,而且我还不太会用这个新的软件,所以pos之前插入和删除pos的图就都不画了,自己理解一下吧~~