【python】使用Selenium获取(2023博客之星)的参赛文章
文章目录
- 前言
-
- 导入模块
- 设置ChromeDriver路径和创建WebDriver对象
- 打开网页
- 找到结果元素
- 创建一个空列表用于存储数据
- 获取当前日期和时间
- 创建一个新的 Excel 文件
- 写入标题行
- 遍历结果元素并提取数据
- 输出data列表
- 创建一个空的DataFrame来存储数据
- 遍历链接并爬取数据
- 关闭浏览器驱动
- 保存结果到一个新的 Excel 文件
- 完整代码如下
-
- 运行效果
- 结束语

前言
2023博客之星活动已经过了半年之久,出于好奇,想看看目前为止到底有多少人参与了, 由于小助手每次只发单独赛道的, 因此无法窥其全貌,进行对比, 因此写了这个脚本,来分析一下, 看到结果之后, 很想放弃啊, 太卷了.
导入模块
from selenium import webdriver
import json
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException
import time
from datetime import datetime
import pandas as pd
from openpyxl import Workbook, load_workbook
- 这一部分代码导入了所需的模块,其中包括selenium、json、time、datetime、pandas和openpyxl。
设置ChromeDriver路径和创建WebDriver对象
driver_path = ''
driver = webdriver.Chrome(driver_path)
- 这部分代码设置了ChromeDriver的路径,并创建了一个Chrome WebDriver对象,用于操作浏览器。
打开网页
url = 'https://bbs.csdn.net/forums/blogstar2023?typeId=3092730&spm=1001.2014.3001.9616'
driver.get(url)
time.sleep(5)
- 这部分代码通过get()方法打开了指定的网页,并使用time.sleep()方法等待5秒钟以确保页面加载完成。
找到结果元素
results = driver.find_element(By.CLASS_NAME, "user-tabs").find_elements(By.CLASS_NAME, "tab-list-item")
- 这部分代码通过find_element()方法定位Class名字为"user-tabs"的元素,并通过find_elements()方法查找其下所有Class名字为"tab-list-item"的元素,将结果保存在results变量中。
创建一个空列表用于存储数据
data = []
- 这部分代码创建了一个空列表data,用于存储数据。
获取当前日期和时间
current_datetime = datetime.now()
current_date = current_datetime.date()
- 这部分代码获取了当前的日期。
创建一个新的 Excel 文件
result_workbook = Workbook()
result_sheet = result_workbook.active
- 这部分代码使用openpyxl库的Workbook函数创建了一个新的Excel文件和一个工作表,并使用active属性获取默认的工作表。
写入标题行
result_sheet.append(['排名',"用户名","总原力值","当月获得原力值","2023年获得原力值","2023年高质量博文数"])
- 这部分代码使用append()方法将标题写入工作表的第一行。
遍历结果元素并提取数据
for result in results:
time.sleep(5)
title = result.find_element(By.CLASS_NAME, 'content-wrapper').find_element(By.CLASS_NAME, 'long-text-title').text
link = result.find_element(By.CLASS_NAME, 'content-wrapper').find_element(By.CLASS_NAME, 'align-items-center').get_attribute("href")
if str(current_date) in title:
item = {
'title': title, # 标题
'link': link
}
data.append(item)
else:
print(f'不是今天的不做处理. 标题{title}')
- 这部分代码使用for循环遍历结果元素列表,并使用find_element()方法提取每个元素中的标题和链接信息。如果标题包含当前日期,则将标题和链接以字典的形式存储在data列表中。否则,输出一条消息。
输出data列表
print(data)
- 这部分代码输出data列表,显示提取的数据。
创建一个空的DataFrame来存储数据
df = pd.DataFrame(columns=["Link", "Content"])
- 这部分代码使用pandas的DataFrame函数创建了一个空的DataFrame,用于存储数据。
遍历链接并爬取数据
for item in data:
print(item['link'])
driver.get(item['link'])
time.sleep(5)
table_element = driver.find_element(By.CLASS_NAME, 'markdown_views').find_element(By.TAG_NAME, 'table')
rows = table_element.find_elements(By.TAG_NAME, 'tr')
for row in rows:
row_data = []
columns = row.find_elements(By.TAG_NAME, 'td')
for column in columns:
cell_data = column.text
row_data.append(cell_data)
print(cell_data)
result_sheet.append(row_data)
- 这部分代码使用for循环遍历data列表中的每个元素,获取其链接并导航到该链接。然后从页面中找到标签为table的元素,并遍历表格的行和列,将单元格中的数据保存在row_data列表中,然后将row_data添加到result_sheet工作表中。
关闭浏览器驱动
driver.quit()
- 这部分代码关闭了浏览器驱动,释放资源。
保存结果到一个新的 Excel 文件
result_workbook.save('博客之星.xlsx')
- 这部分代码使用save()方法将result_workbook保存为名为"博客之星.xlsx"的Excel文件。
完整代码如下
from selenium import webdriver
import json
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException
import time
from datetime import datetime
import pandas as pd
from openpyxl import Workbook, load_workbook
# 设置ChromeDriver的路径
driver_path = ''
# 创建Chrome WebDriver对象
driver = webdriver.Chrome(driver_path)
# 打开网页
url = 'https://bbs.csdn.net/forums/blogstar2023?typeId=3092730&spm=1001.2014.3001.9616'
driver.get(url)
time.sleep(5)
# 找到结果元素
results = driver.find_element(By.CLASS_NAME, "user-tabs").find_elements(By.CLASS_NAME, "tab-list-item")
# 创建一个空列表用于存储数据
data = []
# 获取当前日期和时间
current_datetime = datetime.now()
# 提取当前日期
current_date = current_datetime.date()
# 创建一个新的 Excel 文件
result_workbook = Workbook()
result_sheet = result_workbook.active
# 写入标题行
result_sheet.append(['排名',"用户名","总原力值","当月获得原力值","2023年获得原力值","2023年高质量博文数"])
# 遍历结果元素并提取数据
for result in results:
time.sleep(5)
title = result.find_element(By.CLASS_NAME, 'content-wrapper').find_element(By.CLASS_NAME, 'long-text-title').text
link = result.find_element(By.CLASS_NAME, 'content-wrapper').find_element(By.CLASS_NAME, 'align-items-center').get_attribute("href")
if str(current_date) in title:
# 将提取的数据存储为字典格式
item = {
'title': title, # 标题
'link': link
}
# 将字典添加到数据列表中
data.append(item)
else:
print(f'不是今天的不做处理. 标题{title}')
print(data)
# 创建一个空的DataFrame来存储数据
df = pd.DataFrame(columns=["Link", "Content"])
# 遍历链接并爬取数据
for item in data:
print(item['link'])
# 导航到链接
driver.get(item['link'])
time.sleep(5)
table_element = driver.find_element(By.CLASS_NAME, 'markdown_views').find_element(By.TAG_NAME, 'table')
rows = table_element.find_elements(By.TAG_NAME, 'tr') # 获取所有行
for row in rows:
row_data = []
columns = row.find_elements(By.TAG_NAME, 'td') # 获取每行中的所有列
for column in columns:
cell_data = column.text
row_data.append(cell_data)
print(cell_data)
result_sheet.append(row_data)
# 关闭浏览器驱动
driver.quit()
# 保存结果到一个新的 Excel 文件
result_workbook.save('博客之星.xlsx')
运行效果
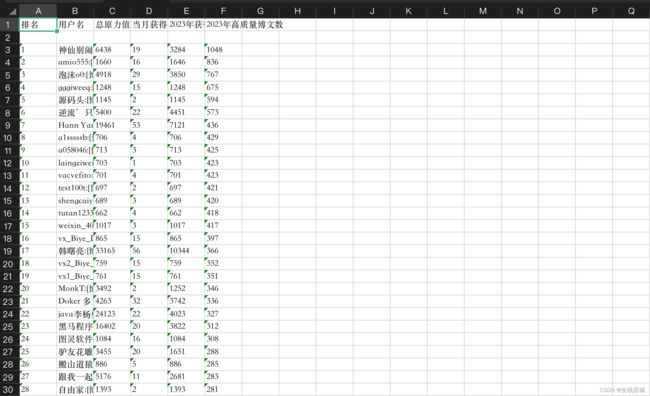
结束语
太难了, 卷不起啊!!!