PLUS模型教程2:数据前期准备和土地利用数量预测
1
数据准备
想要模拟未来土地利用数据,需要一些数据,主要包括:2期土地利用数据(3期也行),众多你挑选的驱动因素数据。这些数据都有一定的要求:
(1) 所有数据必须是tif格式数据,且必须投影坐标系一致;
(2) 土地利用数据必须行列号一致!!(但我自己做我会把驱动因素也统一);
(3) 土地利用数据据分类编号必须从1开始;
(4) 所有文件夹和数据命名格式需要为字母开头,不能以中文或数字开头;
(5) 模型安装包和相关数据必须是全英文路径。
好的,让我们先准备一下土地数据,我们所用的土地数据来源于Globeland 30 全球地表覆被数据库 (http://www.globallandcover.com),大家可以在网上申请,公开数据。选择的研究区是昆明市。
2
数据处理
(1) 如何对齐行列号
当用行政区矢量范围去掩膜1期土地利用栅格数据的时候,掩膜出来的土地利用栅格数据就应该作为基准,是所有栅格数据的范围,未来所有栅格数据都应该按照这个土地利用栅格数据进行掩膜。此外,务必每次掩膜中过程在环境中设置捕捉栅格!!捕捉的栅格应该都步骤到我们的基准栅格数据(我们的基准栅格数据是2020年的土地利用)。然后可以在图层-(右键)属性-源里查看行列号是否一致。Arcgis命名过程中,请键盘打一下后缀名.tif。


(2) 重分类,将土地利用数据分类编号从1开始
使用重分类工具!从1开始!

然后图就做好了:

(3) 驱动因素选择和处理
这次咱们选择8个驱动因素,主要是高程、坡度、降水、气温、GDP、人口密度、距道路距离、距铁路距离。都是公开数据集,都能在网上下到的。DEM数据来源于地理空间数据云,年降水量、年均温、GDP来源于中科院资源环境数据中心,人口密度数据来源于Wordpop,道路和铁路数据来源于全国地理信息资源目录服务系统。

(4) 选择驱动因素的问题与反思:
① 驱动因素是越多越好吗?是否存在多重共线性问题?
驱动因素应该并不是越多越好,合适的才是最好的。但是使用了随机森林模型算法的话,驱动因素多放一些也没有关系,因为随机森林模型可以很好的处理因子间空间自相关和多重共线性。
② 驱动因素是否应该归一化处理?
不需要,因为PLUS模型自动归一化
③ 是否有判断驱动因素组合最佳的方法?
模拟出的结果精度越高,说明组合越合理。
由于这方面我着实是不大了解,只能大概说一下我看过文献中有关驱动因素组合的内容。如有错误请大家指出!也欢迎大家补充选择驱动因素组合的方式。
在TerrSet(也就是IDRISI Selval)的CA-Markov模型中,确实有判断驱动因素解释力的方式,克莱默V值。在欧定华老师(2020)的《景观生态安全格局规划理论、方法与应用》的案例研究中表明:景观格局变化潜力模拟平均准确率开始随组合驱动因子的个数增多而增加,当组合驱动因子个数达到一定数量时,模拟准确率呈下降趋势,组合驱动因子个数越多,其模拟准确性不一定更高。因此,欧定华老师选择驱动因素解释力高的因子进行不断组合,利用MLP-ANN对准确率进行测试,最终选择最佳组合。
参考文献:欧定华,夏建国,姚兴柱, 等. 景观生态安全格局规划理论、方法与应用[M].北京: 科学出版社, 2020
3
初始PLUS模型软件
我们所使用的PLUS模型是版本1.3.5。请注意!模型安装包和相关数据必须是全英文路径!

由于PLUS模型对土地利用数据和限制发展区域数据有格式要求,需要利用Data Processing进行数据转化。注意:只是对土地利用数据有要求!!其他驱动因素数据不需要转化!
PLUS包括了三个东西:这个模块是核心部分,当然,在上一次教程中我们大概说了一下主要是做些什么东西的。

Validation:是指精度验证,以证明科学性。PLUS里可以直接计算Kappa系数和Fom系数。
Demand Prediction:是土地需求预测。
在大概了解模型什么样之后,结合上一期的内容,PLUS的过程呼之欲出:
土地需求预测—在用地扩张分析策略中获取土地发展概率—将各种参数设定在基于多类随机斑块种子的CA模型中运行。
4
土地利用数量预测
(1) 实际操作部分Markov-chain方法
最最最常见的Markov-chain方法PLUS模型已经集成在里面了,我们此次也是细说这个PLUS模型的Markov-chain。
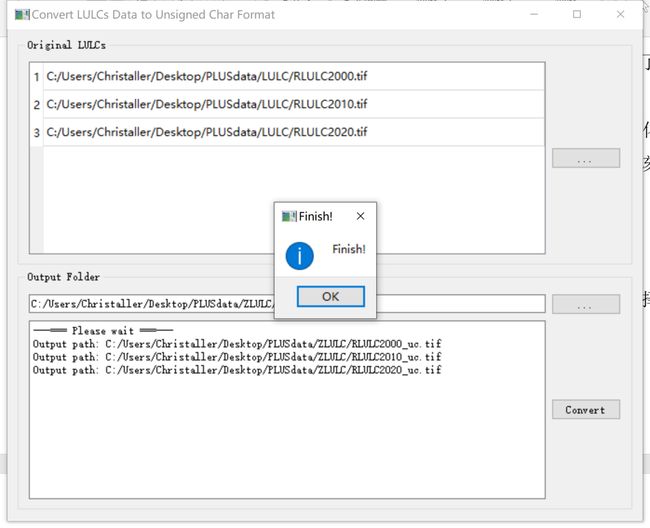
第1步:土地数据需要转化。点击Data Processing进行数据转化,当出现Finish说明转化成功,数据会带有“_uc”的后缀。之后的在PLUS过程中都应该运用该数据。
第2步:未来土地利用数据预测。点击Demand Prediction选择Markov-chain,输入土地利用数据并确定好时间,就能预测相等时间间隔后的未来土地利用数据。我们用2010—2020的转移概率矩阵预测2030年的土地数据。在这个过程中,需要将2030年的土地数据记录下来,PLUS模型将结果保存在Parameterfile文件夹中的MakovChain.csv中。当然最好需要将2010、2020的土地数据也记录下来,统一到Excel表中,今后会比较好分析。此处计算的单位为栅格的像元数量。


推荐参考文献:(即同时使用Markov和PLUS模型的研究):
Shi M, Wu H, Fan X, et al. Trade-Offs and Synergies of Multiple Ecosystem Services for Different Land Use Scenarios in the Yili River Valley, China[J]. Sustainability, 2021, 13(3): 1577.
李琛,高彬嫔,吴映梅,郑可君,武燕.基于PLUS模型的山区城镇景观生态风险动态模拟[J/OL].浙江农林大学学报,2021. http://kns.cnki.net/kcms/detail/33.1370.S.20211109.1427.002.html.
关于Markov的多情景设置。Markov的多情景设置多是进行转移概率的调整,但这里也有将Markov多情景设置权重化了的文献:
孙定钊,梁友嘉.基于改进Markov-CA模型的黄土高原土地利用多情景模拟[J].地球信息科学学报,2021,23(05):825-836.
(2) 关于Markov-chain方法的思考和关于多情景的设定
马尔科夫模型是一种基于转移概率的数学统计模型,是根据当前的状态和发展趋向预测未来的常用方法。事实上,土地利用变化特征也有较为明显的马尔科夫特征。但并不意味着马尔科夫模型就是完美的,模型事实上并未考虑社会经济发展对土地利用的情况,也没有考虑不同生产部门对土地的需求,且若是不同时段内发展土地变化速度有较大差异,预测的结果也有很大的差异。
有幸参加了中国地理学会山地分会2021年学术年会(公众号后台回复山地学会,获取汇报内容),在进行交流过程中,四川师范大学的彭立老师给我们提的建议是基于Markov-chain方法设定多种情景是很主观的,相比而言,系统动力学和线性规划方法可能会更客观一些。但是,以上两种方法均需要收集不少时间序列社会经济数据进行分析,而Markov-chain方法可以用较少的数据也进行预测。
(3) 其余常见土地数量预测方法
其余的方法我也不是很懂,在这儿只能推荐一些我看过的文献,起抛砖引玉的作用。感兴趣的同学可以深入学习研究。
① 系统动力学方法
推荐参考文献:
Liu X, Liang X, Li X, et al. A future land use simulation model (FLUS) for simulating multiple land use scenarios by coupling human and natural effects[J]. Landscape and Urban Planning, 2017, 168: 94-116.
曹祺文,顾朝林,管卫华.基于土地利用的中国城镇化SD模型与模拟[J].自然资源学报,2021,36(04):1062-1084.
② 线性规划方法
Liang X, Guan Q, Clarke K C, et al. Understanding the drivers of sustainable land expansion using a patch-generating land use simulation (PLUS) model: A case study in Wuhan, China[J]. Computers, Environment and Urban Systems, 2021, 85: 101569.
Li C, Wu Y, Gao B, et al. Multi-scenario simulation of ecosystem service value for optimization of land use in the Sichuan-Yunnan ecological barrier, China[J]. Ecological Indicators, 2021, 132: 108328.
曹帅,金晓斌,杨绪红,孙瑞,刘晶,韩博,徐伟义,周寅康.耦合MOP与GeoSOS-FLUS模型的县级土地利用结构与布局复合优化[J].自然资源学报,2019,34(06):1171-1185.
其实还有众多的预测方法,由于自身知识量和阅读不足,其他的方法并未涉及。