MyBatis操作数据库
目录
一、MyBatis
二、一个MyBatis查询
1、环境准备
(1)xml文件中添加MyBatis依赖
(2)准备springboot启动配置
(3)准备数据库对应的mybatis文件
2、插入操作->获取自增的主键
3、mybatis处理结果集
三、MyBatis表查询
1、MyBatis占位符
2、like查询
3、多表查询(关系映射)
(1)一对一表映射
(2)一对多表映射
四、动态SQL
1、
2、
3、
4、
5、
一、MyBatis
MyBayis支持自定义SQL、存储过程以及高级映射,几乎去除了所有的JDBC代码以及设置参数和获取结果集的工作。可以通过简单的xml或注释来配置和映射原始类型、接口为数据库中的记录。简单来说MyBatis是更简单完成程序和数据库交互的工具,更简单的进行操作和读取数据库中的数据。
回顾JDBC操作:
- 创建数据库连接池DataSource;
- 通过DataSource获取数据库连接Connection;
- 编写要执行的带占位符的SQL语句;
- 通过Connection及SQL创建操作命令的对象Statement;
- 替换占位符:指定要替换的数据库字段类型,占位索引及要替换的值;
- 使用Statement执行SQL语句;
- 查询操作:返回结果集ResultSet;更新操作:返回一个int值;
- 处理结果集;
- 释放资源。
存在以下几个问题:
(1)DataSource和Connection两者的关系?
- DataSource提供连接池的支持。连接池在初始化是创建一定数量的数据库连接,这些连接可以复用,每次使用完数据库连接,释放资源调用connection.close()都是将Connection对象回收。
- DataSource创建时,设置了url,账号,密码,不是连接数据库的;通过DataSource.getConnection()获取连接对象时,才通过Connection表示出建立的数据库连接这个概念。
(2)创建操作命令的对象Statement是,如何防止sql注入?
使用PreparedStatement(预编译的操作命令对象)。拼接字符串=>替换占位符。
(3)防止sql注入的原理是什么?
PreparedStatement防止会进行预编译,把替换的字符·中,单引号加上“/”zhuanyi
对于crud操作:
- 输入都是一个对象(根据属性来及逆行过滤/插入/修改),真实开发时,方法参数可以设计为int、String,其实也可以作为对象的属性;
- 输出:修改/插入/删除返回int;查询操作返回List/某个对象。
二、一个MyBatis查询
MyBatis也是一个ORM(Object Relational Mapping,对象关系映射)框架,在面向对象编程的语言中,将关系型数据库中的数据与对象建立起映射关系,进而自动完成数据与对象的互相转换:
- 将输入数据(传入的对象)+SQL映射成原生的SQL(输入替换占位符)
- 将结果集映射为返回对象(输出对象)
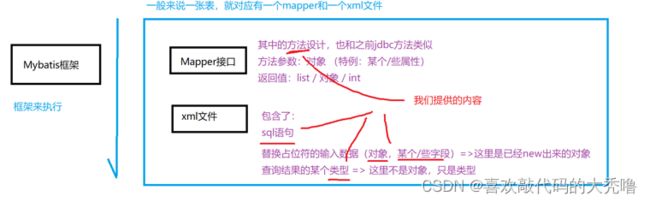
1、环境准备
(1)xml文件中添加MyBatis依赖
在Spring环境的基础上,需要添加MyBatis和数据库相关的依赖包(添加完成后刷新maven即可):
org.mybatis.spring.boot
mybatis-spring-boot-starter
2.1.3
com.alibaba
druid-spring-boot-starter
1.2.3
mysql
mysql-connector-java
runtime
(2)准备springboot启动配置
配置application.properties文件:
配置mybatis:数据库相关的信息:
#配置mybatis:数据库相关的信息(注意修改数据库名等信息)
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/test?characterEncoding=utf8&useSSL=false
spring.datasource.username=root
spring.datasource.password=123456配置mybatis的xml文件路径
#mybatis的xml文件路径(classpath:是spring框架中的写法,类加载的路径)
#表示类加载根路径下,mapper文件夹下,**Mapper.xml
mybatis.mapper-locations=classpath:mapper/**Mapper.xml(3)准备数据库对应的mybatis文件
实体类、mapper文件、xml文件(一张表,对应一套)。
以用户表user为例:
【1】添加实体类
【2】添加mapper接口
【3】添加UserMapper.xml文件
数据持久的实现,mybatis的固定的xml格式:
UserMapper.xml查询所有用户的具体实现:
上面的代码中:
- select/update/insert/delete标签是sql语句,id和接口方法名一致;
- resultType指定结果集转换对象的类型:如果是一行数据,设置为一个具体的类型,如果是多行数据,设置为List包裹的泛型类型。
2、插入操作->获取自增的主键
再很多场景下,都需要返回自增主键的值,如:

新增一个用户后:
(1)如果刷新页面=>新增的自增主键可以不返回,会重新请求用户列表的数据;
(2)如果不刷新页面=>必须返回自增主键的值。不刷新页面,列表多出来的一行用户,没有主键id,无法进行正常的删除、修改操作。
如何获取自增主键呢?
insert into userinfo(username,password,photo,state)
values(#{username},#{password},#{photo},1)
- useGeneratedKeys:MyBatis使用JDBC的getGeneratedKeys方法去除由数据库生成的主键(MySQL关系型数据库管理系统的自增字段),默认值:false;
- keyColumn:设置生成键值再表中的列名,在某些数据库中,当主键列不是表中的第一列时,必须进行设置。如果生成列不止一个,可以用逗号分隔开;
- keyProperty:值定能够为一识别对象的属性。如果生成列不止一个,可以用逗号分割多个属性名称。
3、mybatis处理结果集
类似于jdbc处理结果集的方式:
- 遍历:移动到下一行;
- 每一条数据对应一个对象:把每个字段设置到对象的属性。
结果集字段名=对象的属性名,设置该字段的值为对象的属性;如果结果集字段名带_下划线,对象属性也需要一样(可以在application.properties中配置为下划线自动转驼峰式)
如果查询的结果记得字段和对象的属性名不一致,就不能使用结果集类型(resultType),需要使用结果集映射(resultMap)
三、MyBatis表查询
1、MyBatis占位符
#{变量名}:
- 原理:先替换为jdbc占位符?,再执行jdbc的替换
- 作用:防止sql注入
${变量名}:
- 原理:拼接字符串;
- 可能存在sql注入
- 应用:再进行orderby排序时,占位符需要使用${},不能使用#{}(会由多余的单引号)
2、like查询
like查询不能使用#{}(会报错),也不能直接使用${}(存在sql注入),可以考虑使用mysql的聂志函数concat()来处理。
3、多表查询(关系映射)
(1)一对一表映射
先查看文章和用户的一对一关系(ArticleMapper.xml文件编写如下):
(2)一对多表映射
对于一对多映射,查询结果为一个集合。
查看用户和文章的一对多关系(需要修改Usermapper.xml文件):
四、动态SQL
1、标签
sql中,分为必填字段和非必填字段,对于非必填的字段,需要根据用户传进来的数据判断是否传入该字段,使用
标签。
insert into user(
username,
password,
nickname,
sex,
) values (
#{username},
#{password},
#{nickname},
#{sex},
)2、标签
之前的if标签,只有一个字段是选填项,如果有多个字段选填,使用if标签的时候可能会存在“,”处理的问题,可以使用trim标签,对多个字段都采取动态生成的方式,标签中有如下属性:
- prefix:值作为整个语句块的前缀;
- suffix:值作为整个语句块的后缀;
- prefixOverride:表示整个语句块要去掉的前缀;
- suffixOverride:表示整个语句块要去掉的后缀;
insert into user
username,
password,
#{username},
#{password},
3、标签
查询操作:对于if标签和trim标签,如果进行where查询,此时不传入字段时会报错,所以查询的时候需要使用where标签。
select * from user
and username=#{username}
and password=#{password}
4、标签
修改操作,修改的字段和值是可选的场景使用。
update user
and username=#{username}
and password=#{password}
5、标签
对集合进行遍历,有以下属性:
- collection:绑定方法参数中的集合;
- item:遍历时的每一个对象;
- open:语句块的前缀;
- close:语句块的后缀;
- separactor:每次遍历之间间隔的字符串。
使用场景:
(1)根据id进行批量删除:
delete from article
where id in
#{item}
(2)批量插入:
insert into user(username,password) values
(#{item.username},#{item.password})