文件操作和IO
目录
认识文件
文件的分类
如何区分文本文件和二进制文件?
文件的目录结构
文件路径
绝对路径
相对路径
Java当中的文件操作
1.文件系统的相关操作
通过绝对路径找到文件
通过相对路径来找到文件
2.文件内容的相关操作
FileInputStream
无参数版本读一个文件
两个参数版本读取文件
FileOutputStream
一个参数写入文件一次写一个字节
一个参数写入文件一次写多个字节
注意,写文件操作每次打开文件都会将文件内容全部清空,再从起始位置开始写文件。
FileReader和FileWriter
文件操作的案例
案例一
案例二
案例三
认识文件
1.平时说提到的文件和计算机当中的文件是两个不太相同的概念,平常提到的文件为存储在硬盘上的,格式大多为(txt,jpg,rar,mp4),但在计算机当中文件是一个广义的概念,包括目录(目录文件)。
2.在操作系统中,还会使用文件来描述一下硬件设备和软件资源,操作系统当中把网卡,显示器,键盘都简化为文件。
文件的分类
主要把文件分成两类
1.文本文件
里面存储的是字符,文本文件实际上也是存字节的,只不过相邻的字节恰好组成字符。
2.二进制文件
里面存储的是字节,二进制文件当中相邻的字节是没有关系的。
如何区分文本文件和二进制文件?
用记事本格式分别打开两种文件,打开为文字的是文本文件,打开为乱码的为二进制文件。


日常使用的文件当中,格式为.txt,.c,.java的文件为文本文件;格式为.doc,.ppt,.exe,.zip,.class 的为二进制文件。
文件的目录结构
在计算机中,保存文件的结构称为“文件系统”。在“文件系统”当中通常是通过“树形结构”来组织和管理磁盘上的目录和文件(就是数据结构所学的N叉树)。
整体的文件系统就是这种树形结构的,“目录文件”可以包含多个“普通文件”为非叶子结点,“普通文件”则为叶子结点。 这样的树每个结点上都可以有N个叶子结点,所以称这棵树为N叉树。
文件路径
绝对路径
绝对路径通常以盘名开头如
或者:
相对路径
相对路径首先需要一个基准,在这个基准的条件下去找到目标文件。
相对路径通常是以.或者..开头的,.表示当前的目录底下,..表示在当前目录的父目录下。
即使是定位到同一个文件,从不同的基准去寻找文件的相对路径也是不同的。
Java当中的文件操作
可以分为两种操作:
1.文件系统的相关操作。
2.文件内容的相关操作。
1.文件系统的相关操作
文件系统的相关操作指的是通过文件“文件资源管理器”完成一些操作如:
( 1 )列出文件目录有哪些文件。
( 2 )创建文件,删除文件。
( 3 )创建目录。
( 4 )重命名文件。
在Java当中提供了一个File类,File创建的类就是一个目录/文件,基于这个对象可以实现上述操作。
其中,File的构造方法可以传入一个路径(绝对路径或者相对路径)来指定对应的文件。接着通过创建的对象来调用一系列方法实现功能。
通过绝对路径找到文件
//从绝对路径找到文件
File file1 = new File("/Users/panhongfeng/Desktop/新建\\ Text\\ Document.txt");通过相对路径来找到文件
此时的基准:运行文件的目录。例如用IDEA来执行一个文件,此时该文件的基准就是当前Java项目的位置。
//从基准路径找到文件
File file2 = new File(".\\ Text\\ Document.txt");file对象调用第一组方法
System.out.println(file1.getParent()); //获取到父目录
System.out.println(file1.getName()); //获取到文件名
System.out.println(file1.getPath()); //获取到文件路径(构造File时指定的路径)
System.out.println(file1.getAbsolutePath()); //获取到绝对路径
System.out.println(file1.getCanonicalPath()); //获取到绝对路径file对象调用第二组方法
//从绝对路径找到文件
File file1 = new File("/Users/panhongfeng/Desktop/类类访问关键字的作用域.png");
System.out.println(file1.exists()); //判读文件是否真实存在
System.out.println(file1.isDirectory()); //判断文件是否是一个目录
System.out.println(file1.isFile()); //判断文件是否为一个普通文件file对象调用创建文件方法
public static void main(String[] args) throws IOException {
//文件的创建
File file = new File("./test.txt");
System.out.println(file.exists());
System.out.println("创建文件");
file.createNewFile();
System.out.println("创建完毕");
System.out.println(file.exists());
}file对象在相对路径底下创建目录和多级目录
public static void main(String[] args) {
//创建目录
//File file = new File("./aaa");
//file.mkdir();
//创建多级目录
File file = new File("./aaa/bbb/ccc/ddd");
file.mkdirs();
System.out.println(file.isDirectory());
}file调用方法将相对路径底下的文件例举出来
public static void main(String[] args) {
File file = new File("./");
System.out.println(Arrays.toString(file.list()));
System.out.println(Arrays.toString(file.listFiles()));
}file调用方法将文件重命名
public static void main(String[] args) {
File file1 = new File("./aaa");
File file2 = new File("./zzz");
file1.renameTo(file2);
}2.文件内容的相关操作
文件内容的相关操作分为:
1.打开文件
2.读文件
3.写文件
4.关闭文件
针对文件内容的读写,Java标志库当中提供了一组类,按照文件内容分成两种系列:
1.字节流对象,针对二进制文件,以字节为单位进行读写。
2.字符流对象,针对文本文件,以字符为单位进行读写。
支持字节流读和写操作的类分别为InputStream和OutputStream;
支持字符流读和写操作的类分别为Reader和Writer。
注意:以上四种类都为抽象类,使用时一般使用它们的子类:FileInputStream和FileOutputStream,FileReader和FileWriter
区别:上面那一组抽象类的用法向较它们的子类,使用方法更加广泛,不仅能处理普通文件还能处理一些特殊文件(网卡,socket文件)而它们的子类特指针对处理普通文件;但是在这两组类的使用方法是一模一样的。
FileInputStream

read提供的三个重新载方法:
1.无参数版本:一次只读一个字节,返回值为读到的字节。
2.有一个参数的版本:一次读到若干个字节,读到的字节存放在参数的数组当中,返回值为读到的字节数。
3.有三个参数的版本:一次读到若干个字节,读到的字节存放在参数的数组当中,返回值为读到的字节数。注意:不是从数组的起始开始放置的,而是从中间参数off为下标开始放置的,最后一个参数len表示能放置的最大字节数。
无参数版本的read()返回值为什么不是byte类型的而是int类型的?
byte类型的范围是-127~128,int类型的范围是0~255;因为约定了读到文件末尾时候返回-1,如果返回值是byte类型的,此时返回值-1无法区分为字节码还是文件末尾产生异常状态。使用int类型范围比byte大且不包括-1,正好适用。
无参数版本读一个文件
文件内容为:

public static void main(String[] args) {
//构造方法当中要写的是打开文件的路径,
// 该路径可以是绝对路径,也可以是相对路径,还可以是File的对象。
try {
//创建对象,同时打开文件
InputStream inputStream = new FileInputStream("/Users/panhongfeng/Desktop/test.txt");
//尝试一个字节一个字节的读,将文件读完
int b = inputStream.read();
//因为FileNotFoundException是IOException的子类可以直接使用一个异常捕捉
// } catch (FileNotFoundException e) {
// e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}最终代码
public static void main(String[] args) {
//构造方法当中要写的是打开文件的路径,
// 该路径可以是绝对路径,也可以是相对路径,还可以是File的对象。
try {
//创建对象,同时打开文件
InputStream inputStream = new FileInputStream("/Users/panhongfeng/Desktop/test.txt");
//尝试一个字节一个字节的读,将文件读完
while (true) {
int b = inputStream.read();
if (b == -1) {
//读到文件末尾了
break;
}
System.out.println(b);
}
//读完文件后关闭资源
inputStream.close();
//因为FileNotFoundException是IOException的子类可以直接使用一个异常捕捉
} catch (IOException e) {
e.printStackTrace();
}
}读到结果为:
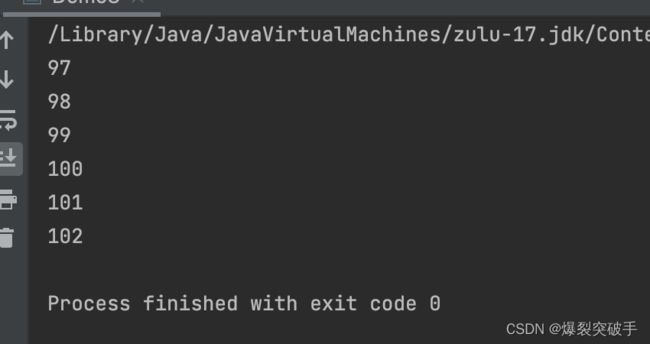
由于文件内容英文字符本身就是一个字节, 按字节读取文件内容读到的就是英文的ASCII码。
这样的代码显得比较的多余且复杂,下面将代码精进
在Java当中提供了try with resource的 的语法try(),改进后代码为:
public static void main(String[] args) {
try(InputStream inputStream = new FileInputStream("/Users/panhongfeng/Desktop/test.txt")){
while (true) {
int b = inputStream.read();
if (b == -1) {
break;
}
System.out.println(b);
}
} catch (IOException e) {
e.printStackTrace();
}
}注意:此时不用手动将inputStream资源关闭,因为try会自动调用,当执行完try代码块之后会调用close()。
但是不是所有的类都能放入到try()当中,要满足一定的条件:这个类实现Closeale接口,且所有的流的类都实现了这个接口。
两个参数版本读取文件
public static void main(String[] args) {
//两个参数版本读取文件
try(InputStream inputStream = new FileInputStream("/Users/panhongfeng/Desktop/test.txt")) {
while (true) {
//设立一个缓冲区
byte[] buffer = new byte[1024];
//一次读取若干个数据存放在缓冲区当中
int len = inputStream.read(buffer);
if (len == -1) {
break;
}
for (int i = 0;i < len;i++) {
System.out.println(buffer[i]);
}
}
} catch (IOException e) {
e.printStackTrace();
}
}对比无参数的字节流读取文件操作,有一个参数和有三个参数的字节流读取文件操作更为高效,因为在计算机当中读磁盘是一次低效操作,所以要尽可能的减少读磁盘的次数。
FileOutputStream
FileInputStream的read方法和FileOutputStream的write方法有许多相似之处,例如都提供了三种参数的版本,参数的类型也相同。下面将模拟实现FileOutputStream的写方法的三种参数版本。
文件内容置为空:

一个参数写入文件一次写一个字节
//使用字节流写文件案例
public static void main(String[] args) {
//一个参数一个字节一个字节输入的实现
try(OutputStream outputStream = new FileOutputStream("/Users/panhongfeng/Desktop/test.txt")) {
outputStream.write(97);
outputStream.write(98);
outputStream.write(99);
} catch (IOException e) {
e.printStackTrace();
}
}
同样是按字节读入将ASCII码转换为英文字符写入文件。
一个参数写入文件一次写多个字节
public static void main(String[] args) {
//写文件多个字节的写入的实现
try(OutputStream outputStream = new FileOutputStream("/Users/panhongfeng/Desktop/test.txt")) {
byte[] buffer = new byte[]{97,98,99,100};
outputStream.write(buffer);
} catch (IOException e) {
e.printStackTrace();
}
}实现结果:
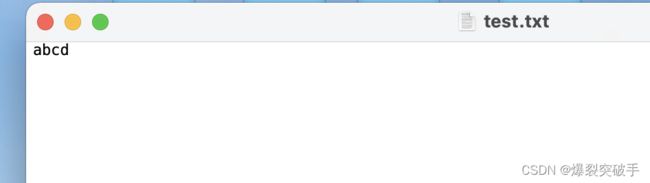
注意,写文件操作每次打开文件都会将文件内容全部清空,再从起始位置开始写文件。
即这步操作:

FileReader和FileWriter
列举一次读取多个字符的字符流读操作和一次写入多个字符的字符流写操作。
public static void main(String[] args) {
try (Reader reader = new FileReader("/Users/panhongfeng/Desktop/test.txt")){
//一次读取若干个
while (true) {
char[] ch = new char[1024];
int len = reader.read(ch);
if (len == -1) {
break;
}
// for (int i = 0;i < len;i++) {
// System.out.println(ch[i]);
// }
//如果这里传入的是byte类型的编码还可以指定utf-8字符集来避免乱码
String s = new String(ch,0,len);
System.out.println(s);
}
} catch (IOException e) {
e.printStackTrace();
}
}//按照字符来写
public static void main(String[] args) {
try (Writer writer = new FileWriter("/Users/panhongfeng/Desktop/test.txt");){
// writer.write('a');
// writer.write('b');
// writer.write('c');
// writer.write('d');
// writer.write('e');
char[] buffer = new char[]{'a','b','d','e'};
writer.write(buffer);
} catch (IOException e) {
e.printStackTrace();
}
}文件操作的案例
案例一
扫描指定目录,并找到指定字符的普通文件,后询问是否需要删除。
1.用户输入一个目录。
2.再输入一个文件名,最后询问是否删除。
//案例1,查找文件并确定是否删除
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
System.out.println("输入要删除文件的路径");
String rootDirPath = sc.next();
System.out.println("请输入要删除的文件名");
String toDeleteName = sc.next();
//通过路径获取目录
File rootDir = new File(rootDirPath);
if (!rootDir.isDirectory()) {
System.out.println("输入的文件路径有误");
return;
}
scanDir(rootDir,toDeleteName);
}
private static void scanDir(File rootDir, String toDeleteName) {
//先列出rootDir下都有哪些文件
File[] files = rootDir.listFiles();
//rootDir是一个空目录
if (files == null) {
return;
}
//如果当前列出的这些文件是普通文件就检验文件名确定是否为要删除的文件
//如果当前内容为目录,则递归遍历寻找
for (File f : files) {
//普通文件的情况
if (f.isFile()) {
//扫描的文件名包含要删除文件的文件名,这里不要求两个文件名完全相同
if (f.getName().contains(toDeleteName)) {
deleteFile(f);
}
//为文件目录的情况
} else if (f.isDirectory()) {
//当前内容为目录,递归扫描查找要删除的文件
scanDir(f,toDeleteName);
}
}
}
private static void deleteFile(File f) {
try {
System.out.println(f.getCanonicalPath() + "确定要删除文件吗?(Y/N)");
Scanner scanner = new Scanner(System.in);
String choice = scanner.next();
if (choice.equals("Y") || choice.equals("y")) {
f.delete();
System.out.println("删除完毕");
} else {
System.out.println("文件删除取消");
}
} catch (IOException e) {
e.printStackTrace();
}
}案例二
进行文件的复制,将一个文件的内容复制到另外一个文件当中。
1.输入两个文件路径,一个为源文件路径,一个为目标文件路径。
2.读取源文件的内容写入目标文件。
//复制一个文件的内容到另外一个文件
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
System.out.println("请输入源文件的文件路径");
String src = sc.next();
System.out.println("请输入目标文件的文件路径");
String des = sc.next();
File srcFile = new File(src);
//需要判断源文件是否为存在
if (!srcFile.exists()) {
System.out.println("源文件不存在");
}
//这里不需要检验目标文件是否存在,
// 因为OutputStream过程中会自动创建不存在的目标文件
try (InputStream inputStream = new FileInputStream(src)){
try (OutputStream outputStream = new FileOutputStream(des)){
byte[] buffer = new byte[1024];
while (true) {
int len = inputStream.read(buffer);
if (len == -1) {
break;
}
outputStream.write(buffer,0,len);
System.out.println("复制完毕");
}
}
} catch (IOException e) {
e.printStackTrace();
}
}案例三
通过文件路径和关键词找到包含该关键词的文件。
1.先输入文件路径,再输入要查找的关键词。
2.按照文件路径找到的内容,如果是一个文件则直接遍历改文件查找是否包含关键词,如果是一个目录则在遍历查找目录并搜索目录当中的文件,查看是否包含关键词。
这样的操作是一个低效的操作,因为当文件数目很多或者文件的内容很多的时候,这样的遍历查找的时间开销是很多的。
//输入文件路径和要查找的文件关键字
public static void main(String[] args) throws IOException {
Scanner sc = new Scanner(System.in);
//1.输入要查找的文件路径
System.out.println("输入要查找的文件路径");
String rootDirPath = sc.next();
//2.输入要查找的关键词
System.out.println("输入要查找的关键字");
String word = sc.next();
File file = new File(rootDirPath);
if (!file.isDirectory()) {
System.out.println("输入的不是路径不合法");
return;
}
//递归的进行遍历
scanDir(file,word);
}
private static void scanDir(File file, String word) throws IOException {
File[] files = file.listFiles();
if (files == null) {
System.out.println("这是一个空目录");
return;
}
for (File f : files) {
//如果f为普通文件
if (f.isFile()) {
//如果f包含要找的关键字
if (containWord(f,word)) {
//打印出所以包含关键字的文件的文件路径
System.out.println(f.getCanonicalPath());
}
//如果f为文件目录
} else if (f.isDirectory()) {
//f为文件目录,遍历搜索文件目录当中的文件
scanDir(f,word);
}
}
}
private static boolean containWord(File f, String word) {
StringBuilder stringBuilder = new StringBuilder();
try(Reader reader = new FileReader(f)) {
char[] buffer = new char[1024];
while (true) {
int len = reader.read(buffer);
if (len == -1) {
break;
}
stringBuilder.append(buffer,0,len);
}
}catch (IOException e) {
e.printStackTrace();
}
//在stringBuilder当中寻找是否包含关键字word,如果包含返回-1;
return stringBuilder.indexOf(word) != -1;
}.flush操作的意义
.flush叫做“刷新缓冲区”。
缓冲区存在的意义是提高效率,因为在计算机当中读取CPU的速度远大与读取硬盘的速率,读一次写一次数据到硬盘的效率是比较低的。所以不如一次积攒一堆数据后再读出或者写入这一堆数据,用于存放这一堆数据的内存空间称为“缓冲区”。
例如,在写数据的时候,需要把数据写到缓存区当中,再统一写到硬盘。如果当前缓存区已满,就会触发写入操作,将缓冲区的数据写入到硬盘当中;如果缓冲区还没满,此时想要将数据写入硬盘当中,则需要通过.flush来手动来“刷新缓冲区”。
之前的代码没有使用.flush操作是因为在close当中会自动触发“刷新缓冲区”。