Text-to-SQL小白入门(一)
摘要
本文主要介绍了Text-to-SQL研究的定义、意义、研究方法以及未来展望,主要是对Text-to-SQL领域进行一个初步的认识和了解,适合初学者入门了解。
1 引言
作为Text-to-SQL领域的小白,学习该领域的最好方式就是看最新的综述文章,一般而言,综述文章都是由该领域的多位大牛综合上百篇文章形成的总结、沉淀和思考。通过学习综述文章,我们可以快速对该领域有一个全局的认识,站得高看得远还是很有道理的。同时学习综述文章,我们可以站在巨人的肩膀上,了解该领域的最新发展,避免出现闭门造车的情况。
那么今天我主要以2022年的2篇综述文章为主,简单介绍一下该研究领域。
- 1.第一篇综述文章标题为《A Survey on Text-to-SQL Parsing: Concepts, Methods, and Future Directions》,意思就是Text-to-SQL解析的概念、方法和未来方向。
-
- 发表期刊/会议:IEEE Transactions on Knowledge and Data Engineering,简称为TKDE,属于CCF-A类期刊,属于数据库/数据挖掘/内容检索上的顶刊!(如果不知道期刊会议等级可以通过中国计算机学会推荐国际学术会议和期刊目录(2022)这个链接查询)。
- 发表时间:2022年
- 论文作者:Bowen Qin, Binyuan Hui, Lihan Wang, Min Yang, Jinyang Li, Binhua Li, Ruiying Geng, Rongyu Cao, Jian, Sun, Luo Si, Fei Huang, Yongbin Li(可以看出团队阵容还是很强大的)
- 作者单位:中科院、阿里巴巴达摩院、香港大学
- 文章链接:https://arxiv.org/pdf/2208.13629.pdf
- 2.第二篇综述文章标题是《Recent Advances in Text-to-SQL: A Survey of What We Have and What We Expect》,意思就是Text-to-SQL领域的最新进展:关于我们所拥有该领域的知识以及和所期盼的发展方向的综述。
-
- 发表期刊/会议:International Conference on Computational Linguistics,简称COLOING,属于CCF-B类会议,属于人工智能领域/NLP领域有重要影响力的会议。(一般来说,ACL、NAACL、EMNLP、COLING被称为是NLP领域的四大顶会。)
- 发表时间:2022年
- 论文作者:Naihao Deng、Yulong Chen、 Yue Zhang
- 作者单位:密歇根大学(美国)、西湖大学
- 文章链接:https://arxiv.org/pdf/2208.10099v1.pdf
2 Text-to-SQL是什么?
了解一个研究领域,首先需要搞明白任务是什么?确定任务的输入输出边界是什么?也就是了解what?
Text-to-SQL(简写为T2S,或者是Text2SQL),顾名思义就是把文本转化为SQL语言,更学术一点的定义是:把数据库领域下的自然语言(Natural Language,简写为NL)问题,转化为在关系型数据库中可以执行的结构化查询语言(Structured Query Language,简写为SQL),因此T2S也可以被简写为NL2SQL。
举个例子比较直观,T2S任务给定一个表格Table,输入就是一段自然语言文本,输出就是SQL语句,如图1(Sun, Tang et al., 2018)所示:用户想要查询 “由安娜最初演唱的歌曲总数是多少?”,经过T2S任务解析后,输出SQL语句,执行模块再在数据库中执行SQL,返回执行结果:1。
- 输入:自然语言问题:“what 's the total number of songs originally performed by anna nalick?”
- 输出:SQL语句:“SELECT COUNT Song choice WHERE Original artist = anna christine nalick”

图1 Text-to-SQL例子
再举个中文场景的例子,比如给定如下表1,用户查询问题:“新浪网的周涨跌幅是多少?”,输出SQL语句“SELECT 周涨跌幅 FROM 表1 WHERE 名称 = '新浪'”,经过数据库SQL执行器后,得到输出-4.52.
- 输入:“新浪网的周涨跌幅是多少?”
- 输出:“SELECT 周涨跌幅 FROM 表1 WHERE 名称 = '新浪'”

表1 测试表
前不久,github上有个比较有意思的项目叫DB-GPT,专注于做数据库场景下的安全可靠隐私的大模型,目前已经有5.7k的star,可以直接体验一下T2S的功能,这里贴上几张效果图,详情可以参考点击前面的超链接进入使用。
- 如图2所示,根据自然语言生成SQL(这就是前面提到的T2S)

图2 DB-GPT中生成SQL效果图
- 如图3所示,与数据对话,直接查看结果(把自动生成的SQL语句在数据库中执行并展示到网页)

图3 DB-GPT中与数据对话效果图
3 Text-to-SQL有什么用?
我们前面提到了T2S的定义,了解了T2S最基础的概念是什么,那么接下来了解一下研究T2S的价值是什么,有什么意义,可以在哪些领域发挥作用,也就是了解why?
T2S可以让非专家用户无需费力地查询表,并在各种现实生活应用程序中发挥核心作用,如智能客户服务、智能问答和机器人导航等。
- 智能客户服务:假设一家电子商务公司拥有大量的客户数据,包括客户的订单信息、客户的问题和反馈等。这些数据通常存储在关系型数据库中,但是这些数据对于客户服务来说,查询和分析起来比较困难。因此,该公司采用Text-to-SQL技术将自然语言文本数据转化为结构化数据,以便更容易地进行查询和分析。例如,客户服务人员可以通过Text-to-SQL查询系统快速地检索出最近一段时间内提出的问题,并根据问题的类型、等级和优先级进行分类和处理。此外,Text-to-SQL还能够将自然语言问题转化为结构化问题,方便数据库进行问题的分析和处理,从而提高客户服务的效率和质量。
- 智能问答:智能问答系统通常需要大量的自然语言文本数据,以便能够理解用户的问题并给出相应的答案。Text-to-SQL可以将这些自然语言文本数据转化为结构化数据,以便更容易地进行查询和分析。例如,智能问答系统可以通过Text-to-SQL查询系统快速地检索出用户的问题,并根据问题的类型、关键词和语义等信息进行分类和处理。此外,Text-to-SQL还能够将自然语言问题转化为结构化问题,方便数据库进行问题的分析和处理,从而提高智能问答系统的效率和准确性。
- 机器人导航:机器人导航系统需要能够理解环境中的自然语言信息,以便能够感知环境并做出相应的决策。Text-to-SQL可以将这些自然语言信息转化为结构化数据,以便更容易地进行查询和分析。
- 其他
4 Text-to-SQL方法集合
前面我们已经了解了T2S任务的定义以及价值,那么最重要的就是学习如何去做?如何实现T2S?也就是how?
在了解T2S方法之前,先了解一下数据集和评测指标。
4.1 数据集
在TKDE综述文章中,常见的数据集有GenQuery、Scholar、WikiSQL、Spider、Spider-SYN、Spider-DK、Spider-SSP、CSpider、SQUALL、DuSQL、ATIS、SparC、CHASE等,如图4所示。

图4 T2S数据集汇总示意图
由图4知,数据集的分类有单领域和交叉领域;有单轮对话和多轮对话;有简单问题和复杂问题;有中文语言和英文语言;有单张表和多张表等。
在COLING综述文章中,最新的T2S相关数据集主要有Spider、WikiSQL、Squall、KaggleDBQA、IMDB、Yelp、Advisiing、MIMICSQL、SEDE等,如图5所示。文章中把数据集主要划分为3类:单域数据集、跨域数据集和其他数据集。
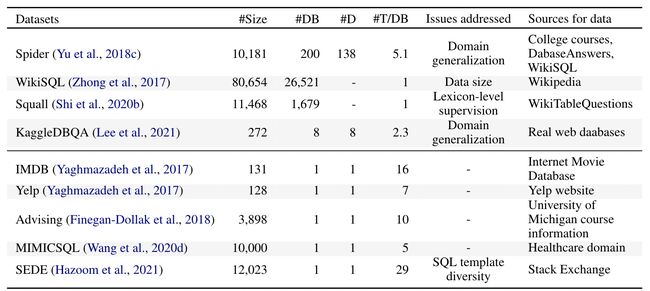
图5 T2S最近几年的数据集汇总示意图
接下来结合两个综述文章,介绍几个重点数据集:WikiSQL、Spider、CHASE等。
4.1.1 WikiSQL
WikiSQL数据集是目前规模最大的T2S数据集,由2017年美国的Salesforce公司提出,场景来源于 Wikipedia,属于单领域。数据标注采用外包。
- 包含了80654个自然语言问题,77840个SQL语句。
- 包含了26521张数据库表,1个数据库只有1张表。
- 预测的SQL语句形式比较简单,基本为一个SQL主句加上0-3个WHERE子句条件限制构成,如图6所示

图6 WikiSQL数据集SQL语句统计
4.1.2 Spider
Spider数据集是多数据库、多表、单轮查询的T2S数据集,也是业界公认难度最大的大规模跨领域评测榜单,由2018年耶鲁大学提出,由11名耶鲁大学学生标注。
- 10181个自然语言问题,5693个SQL语句。
- 涉及138个不同领域的200多个数据库。
- 难易程度分为:简单、中等、困难、特别困难,如图7所示。

图7 Spider数据集SQL语句示例
- 7000个问题用于训练train,1034用于开发development,2147用于test。
4.1.3 CHASE
CHASE数据集是首个跨领域、多轮Text2SQL中文数据集,由2021年微软亚洲研究院、北航和西安交大提出,相关论文被2021ACL接收。
- 跨领域,包含280个不同领域的数据库,且 train/dev/test 不重复;
- 大规模,包含5459个多轮问题组成的列表,一共17940个
图8 Spider数据集多轮对话问答示例
- 多轮交互,同一个列表的问题之间会有实体省略等交互现象,类似于 SParc 和 CoSQL;
- 中文数据集,问题和数据库表名、列名、其中的元素都是中文,相比之下,CSpider只是将表名、列名字段翻译为中文。
- 标注信息丰富,除了 query 和 SQL,CHASE 额外标注了(1)上下文依赖关系,包括 Coreference 共指、Ellipsis 省略;(2)模式链接关系,对于 query 中提到的表名和列名信息进行了标记。
4.2 评测指标
目前来说,没有完全统一的标准度量,目前广泛使用的是执行准确率(Execution Accuracy,简称EX)和逻辑形式准确率(Exact Match,简称EM)。
4.2.1 执行准确率
- 定义:计算SQL执行结果正确的数量在数据集中的比例。
- 缺点:存在高估的可能。因为一个完全不同的非标准的SQL可能查出于与标准SQL相同的结果(例如,空结果),这时也会判为正确。
- 举个例子:假如有个学生表,我们想要查询学生表中年龄等于19的学生姓名,就如“SELECT sname FROM Student where age = 19;”所示,通过数据库执行标准SQL后得到结果为null;此时Text-to-SQL模型预测的SQL为“SELECT sname FROM Student where age = 20;”,通过数据库执行后也得到结果为null。虽然预测的SQL跟标注的SQL不一致,但是结果是一样的,根据执行准确率指标来比较,那么就认为模型预测是正确的。
# groundtruth_SQL SELECT sname FROM Student where age = 19; # SQL执行结果 null # predict_SQL SELECT sname FROM Student where age = 20; # SQL执行结果 null
4.2.2 逻辑形式准确率
- 定义:计算模型生成的SQL和标注SQL的匹配程度。
- 缺点:存在低估的可能。如一个SQL执行结果是正确的,但于标注SQL的字符串并非完全匹配,例如,只是select 列的顺序不同或SQL查询目的完全相同的不同SQL。为了解决一部分该问题,有研究指出了一种查询匹配精度query match accuracy:将生成的SQL和标注SQL都以标准形式表示,再计算两者匹配精度。这种方法只解决了由于排序问题而导致的误判。另外,通过对列和表进行排序并使用标准化别名来对SQL进行规范化,也可以消除不同SQL格式导致的误判问题。
- 举个例子:同样地,假如有个学生表,我们想要查询学生表中年龄等于19的学生姓名和学生学号。,就如“SELECT sname FROM Student where age = 19;”所示,通过数据库执行标准SQL后得到结果为(张三,123456);此时Text-to-SQL模型预测的SQL为“SELECT sno,sname FROM Student where age = 19;”,通过数据库执行后也得到结果为(123456,张三),如果从逻辑形式准确率指标来看,因为SQL并不是一模一样,尽管两者只是筛选顺序的语序问题,所以会认为模型预测是错误的。
# groundtruth_SQL SELECT sname,sno FROM Student where age = 19; # SQL执行结果 张三,123456 # predict_SQL SELECT sno,sname FROM Student where age = 19; # SQL执行结果 123456,张三
4.3 研究方法
4.3.1 基于模版和匹配的方法
因为输出SQL本质上:是一个符合语法、有逻辑结构的序列,本身具有很强范式结构,所以可以采取基于模板和规则的方法。简单SQL语句都可以抽象成如下图9:

图9 简单SQL模板示例
- AGG表示聚合函数,如求MAX,计数COUNT,求MIN。
- COLUMN表示需要查询的目标列。
- WOP表示多个条件之间的关联规则“与and /或 or”
- 三元组 [COLUMN, OP, VALUE] 构成了查询条件,分别代表条件列、条件操作符(>、=、<等)、条件值。
- *表示目标列和查询条件不止一个!
基于模板和匹配的方法,是早期的研究方法,适用于简单SQL,定义后的sql准确率高;不适合复杂SQL,没有定义模板的SQL不能识别。
4.3.2 基于Seq2Seq框架方法
对于T2S研究而言,本质上属于自然语言处理(Natural Language Processing,NLP),而在NLP领域中,常见的任务可以大概分为如下四个场景,1、N和M代表的是token的数量。
- 1 -> N:生成任务,比如输入为一张图片,输出图片的文本描述。
- N -> 1:分类任务,比如输入为一句话,输出这句话的情感分类。
- N -> N:序列标注任务,比如输入一句话,输出该句话的词性标注。
- N -> M:机器翻译任务,比如输入一句中文,输出英文翻译。
可以发现的是,T2S任务是符合N -> M机器翻译任务的,处理机器翻译任务最主流的方法是基于Seq2Seq框架方法,Seq2Seq是一种基于序列到序列模型的神经网络架构,它由两个部分组成:编码器Encoder和解码Decoder。因此,T2S最主流的方法也是基于Seq2Seq框架。
4.3.2.1 单轮对话T2S方法
- Encoder
-
- 输入数据表征:把自然语言问题和表结构信息进行编码。
-
-
- 基于LSTM的方法。
- 基于Transformer的方法。
-
-
- 结构信息建模:任务本质上是一个高度结构化的任务,重点需要解决3个挑战:
-
-
- 链式结构linking structure,编码器需要将NL问题中提到的实体与所提到的模式表或列对齐。
- 模式结构schema structure,编码的表示应该知道架构结构信息,如主键、外键和列类型。
- 问题结构question structure,编码器应该能够感知NL问题的复杂变化,即问题结构。
-
- Decoder
-
- 基于草图Sketch-based方法。
-
-
- 内容:1.将SQL生成的过程分解为子模块,比如select列,AGG聚合(aggregate)功能,where 值。2.每个子模块对应于要填充的预测槽的类型,比如select槽,AGG槽等,每个槽都有独立的模型,不共享训练参数,独立负责最终SQL的一部分。3.把子模块最终集合起来,生成SQL。
- 优点:速度很快,保证符合正确的SQL语法规则。
- 缺点:很难处理复杂的SQL语句,比如嵌套查询,多表连接等等。
- 适用数据集:在WikiSQL数据集流行;不适用于spider数据集。
-
-
- 基于生成generation-based方法。
-
-
- 内容:基于Seq2Seq模型来解码SQL。
- 优点:更适合于复杂SQL场景。
- 缺点:可能生成的SQL不符合语法,所以引入了深度遍历优先的抽象语法树abstract syntax tree。
- 适用数据集:spider数据集也适用。
-
4.3.2.2 多轮对话T2S方法
- Encoder
-
- 多轮输入表征Multi-turn input representation。如图10所示,研究了不同上下文信息编码方法对多回合T2S解析性能的影响,包括(a)接触每个问题序列中的所有NL问题作为输入,(b)使用回合级编码器处理每个问题,以及(c)设计一个门机制,以平衡每个历史问题的重要性。

图10 多轮对话不同上下文信息编码示例
-
- 多轮结构建模Multi-turn Structure Modelling。
-
-
- linking structure:R2SQL专注于上下文链接结构的独特性,引入了一种新颖的动态图框架来有效地对上下文问题、数据库模式及其之间的复杂链接结构进行建模。应用衰减机制来评估历史链接对当前转弯的影响。
- schema structure模式结构。IGSQL提出了一种数据库模式交互图编码器,用于将数据库模式项与历史项一起获得,从而保持上下文一致性。跨回合模式交互图层和回合内模式图层分别使用上一回合和当前回合来更新模式项表示。IST-SQL处理了受面向任务的数据生成任务启发的多回合文本到SQL解析任务。IST-SQL定义、跟踪并利用多回合文本到SQL解析的交互状态,其中每个交互状态都由基于先前预测的SQL查询的状态更新机制更新。
-
- Decoder
-
- 对于多回合设置,大多数以前的方法使用具有注意力机制的LSTM解码器,以产生基于历史NL问题、当前NL问题和表模式的SQL查询。解码器将当前NL问题、SQL状态、模式状态和上次预测的SQL查询的编码表示作为输入,并在解码过程中应用查询编辑机制来编辑先前生成的SQL查询,同时合并NL问题和模式的上下文。对于SQL查询,使用单独的层来预测SQL关键字、表名和问题标记。softmax操作最终用于生成输出概率分布。
4.3.3 模型预训练方法
4.3.3.1 预训练数据构造
训练数据不足是学习强大的预训练表格语言模型的一个重要挑战。当应用于SQL解析任务的下游文本时,预训练数据的质量、数量和多样性对预训练语言模型的总体性能有重大影响。尽管从Web(例如维基百科)收集大量表格很容易,但在收集的表格上获得高质量的NL问题及其相应的SQL查询是一个劳动密集型和耗时的过程。最近,有大量的研究可以手动或自动生成用于文本到SQL解析的预训练数据。接下来,我们将从三个角度讨论以前的预训练数据构建方法:表收集、NL问题生成和逻辑形式(SQL)生成。
- 表集合table collection
- NL问题生成
- SQL生成
4.3.3.2 输入编码input encoding
在文本到SQL的解析任务中,输入通常包括两部分:NL问题和表模式,输出可能是SQL查询。然而,文本数据、选项卡数据和SQL查询是异构的,它们具有不同的结构和格式。具体来说,表格数据通常分布在二维结构中,有数值和单词,而SQL查询通常由SQL关键字(如“SELECT”、“UPDATE”、“DELETE”、“INSERT INTO”)和模式元素组成。因此,在这三种类型的数据上开发一个联合推理框架是非常重要的。
- 文本数据编码
- 表格数据编码
4.3.3.3 预训练的目标
大多数现有的文本到SQL解析的预训练模型采用单个Transformer或基于编码器-解码器框架的Transformer作为主干,并采用不同类型的预训练目标来捕捉文本到SQL的解析任务的特征。预训练目标可分为五个主要类别,包括掩蔽语言建模(MLM)、模式链接、SQL执行器、文本生成和上下文建模。
- 屏蔽语言建模masked language modeling
- 模式链接schema linking
- SQL执行器
- 文本生成
- 上下文建模
5 Text-to-SQL未来展望
T2S方向未来发展放下主要有以下几个方向:
- 高质量的训练数据生成
- 处理大规模表格/数据库形态
- 结构化表格数据编码
- 异构信息建模
- 跨领域T2S
- T2S模型的鲁棒性
- 零样本/小样本学习
- 上下文相关的T2S解析预训练
- 模型可解释性
- 数据隐私保护
参考文献
1.Y. Sun, D. Tang, N. Duan, J. Ji, G. Cao, X. Feng, B. Qin, T. Liu, and M. Zhou, “Semantic parsing with syntax-and table-aware sql gener.,” in Proc. of the 56th Annu. Meeting of the Assoc. for Comput. Linguistics (Vol. 1: Long Papers), pp. 361–372, 2018.
2.Qin B, Hui B, Wang L, et al. A survey on text-to-sql parsing: Concepts, methods, and future directions[J]. arXiv preprint arXiv:2208.13629, 2022.
3.Deng N, Chen Y, Zhang Y. Recent advances in text-to-SQL: a survey of what we have and what we expect[J]. arXiv preprint arXiv:2208.10099, 2022.
4.Recent Advances in Text-to-SQL: A Survey of What We Have and What We Expect_哔哩哔哩_bilibili
5.ACL 2021 | CHASE:首个跨领域多轮Text2SQL中文数据集 - 知乎
6..2021你还在手写SQL吗?万字综述Text to SQL技术 - 知乎
7.https://github.com/eosphoros-ai/DB-GPT/blob/main/README.zh.md
8.https://github.com/eosphoros-ai/DB-GPT-Hub/blob/main/README.zh.md