Canal内存队列的设计
1、背景
笔者的公司内部使用了开源的Canal数据库中间件来接受binlog数据,并基于此进行数据的订阅和同步到各种同构和异构的数据源上,本文将对Canal内部使用的store模块进行分析。
2、Store模块概览
Canal的store模块用于存储binlog中的每一个event,该模块的核心是CanalEventStore,定义了关于event的存储和获取的接口

最下面MemoryEventStoreWithBuffer是借鉴了Disruptor的内存ringbuffer的默认实现,按官方给出的模型图大概状态如下:
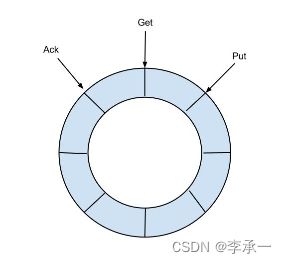
ringbuffer内部定义了三个不同的cursor,put表示写入队列中的最新的event的位置;get表示client每次请求后的位置,而ack而知由client发出ack后的位置,三者之间应该满足如下关系:
ackSequence <= getSequence <= putSequence如果将ringbuffer拉直的话,效果图如下
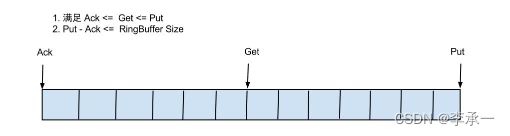
计算当前可消费的event数量如下:putSequenct - genSequence;
计算当前队列的大小(剩余多少event等待消费):putSequenct - ackSequence;
默认情况下ringbuffer的数组空间大小是16384,也就是总共可以存储16384个event,该空间的默认大小可以通过调整canal.properties的默认配置canal.instance.memory.buffer.size来修改,该配置需要保证必须是2的N次幂(N是整数),下面会介绍原因。
在进行put/ack/get操作的时候,都需要确定操作到ringbuffer中的哪个位置。拿put操作来说如果一直往队列里面插入event,很容易就超过这个值,所以每次操作时都需要衡量这三个值所对应的位置。打个比方,如果canal这时从binlog中获取到了一个event,此时放入到队列中需要判断当前队列putSequenct是否还有剩余空间使用,如果putSequenct目前最新的event放置的位置是16383(数组从1开始计数),那么下一个就需要放到16384的位置上,此时用16384 % bufferSize就得出需要放到0的位置上。可见当达到队列的最大下标时,再从头开始循环,这也是为什么称之为环形队列的原因。当然在实际操作时,更加复杂,如0号位置上已经有数据了,就不能插入,需要等待这个位置被释放出来,否则出现数据覆盖。
因为用到了求余的操作,所以如果bufferSize是2的N次幂,计算时只需要左移或者右移N位即可,这种方式只适用除数是2的N次幂,可以极大加快运算速度。
3、MemoryEventStoreWithBuffer
下面开始介绍内存队列的实现,核心字段属性如下:
public class MemoryEventStoreWithBuffer extends AbstractCanalStoreScavenge implements CanalEventStore, CanalStoreScavenge {
private static final long INIT_SEQUENCE = -1;
private int bufferSize = 16 * 1024;
private int bufferMemUnit = 1024;
// memsize的单位,默认为1kb大小
private int indexMask;
// binlog实际存储的地方
private Event[] entries;
// 记录下put/get/ack操作的三个下标,主要这里存的是在队列中对应的位置,不是数量
private AtomicLong putSequence = new AtomicLong(INIT_SEQUENCE);
private AtomicLong getSequence = new AtomicLong(INIT_SEQUENCE);
private AtomicLong ackSequence = new AtomicLong(INIT_SEQUENCE);
// 记录下put/get/ack操作的三个memsize大小
private AtomicLong putMemSize = new AtomicLong(0);
private AtomicLong getMemSize = new AtomicLong(0);
private AtomicLong ackMemSize = new AtomicLong(0);
// 阻塞put/get操作控制信号
private ReentrantLock lock = new ReentrantLock();
private Condition notFull = lock.newCondition();
private Condition notEmpty = lock.newCondition();
// 默认为内存大小模式
private BatchMode batchMode = BatchMode.ITEMSIZE;
// 针对entry是否开启raw模式
private boolean ddlIsolation = false;
private boolean raw = true; 其中event实际存储在entries字段中,默认该数组的大小是16384,由上面提到的canal.instance.memory.buffer.size限制,bufferSize本身代码中也是限定了16 * 1024
public void start() throws CanalStoreException {
super.start();
if (Integer.bitCount(bufferSize) != 1) {
throw new IllegalArgumentException("bufferSize must be a power of 2");
}
indexMask = bufferSize - 1;
entries = new Event[bufferSize];
}indexMask用于对putSequenct、getSequenct和ackSequence进行取余操作,值的大小为bufferSize-1;
batchMode由两个取值方式,分别是基于对象数量的ITEMSIZE和内存大小的MEMSIZE,该值的作用是表示Canal内存store中数据缓存模式,用以限制使用内存的大小,一旦超出该限制则暂停写入数据,
- ITEMSIZE,根据event的数量进行限制,如果每个event占用1M,那么在默认情况下16384的bufferSize则需要使用16G的空间(额。。。)
- MEMSIZE,根据bufferSize * buffer.memunit的大小,限制内存的使用空间,指定为这种模式时,意味着默认缓存的event占用的总内存不能超过16384*1024=16M。但是呢该值并不限制一个event最大只能是16M,因为Canal在put一个event的时候,只会判断队列中已有的event占用的内存是否超过16M,如果没有,新的event不论大小是多少,总是可以放入的(canal的内存计算实际上是不精确的),之后的event再要放入时,如果这个超过16M的event没有被消费,则需要进行等待。
batchMode由canal.properties中的配置canal.instance.memory.batch.mode决定,默认是MEMSIZE,而buffer.memtunit由同个文件的canal.instance.memory.buffer.memunit决定,默认是1024
队列内部可以类比生产和消费者模型,有数据时进行put操作,消费者获取数据时执行get操作。
3.1、Put操作
MemoryStoreWithBuffer实现了接口CanalEventStore的6个put方法,根据使用场景不同可以分为3类:
-
不带timeout超时参数的put方法,会一直进行阻塞,直到有足够的空间可以放入。
-
带timeout参数超时参数的put方法,如果超过指定时间还未put成功,会抛出InterruptedException。
-
tryPut方法每次只是尝试放入数据,随后立即返回true不管成功or失败,或者没有空间直接返回false,不会阻塞。
这里拿带超时时间的put方法进行分析,其他的方法都是差不多,区别主要在于是否带超时时间。
public boolean put(List data, long timeout, TimeUnit unit) throws InterruptedException, CanalStoreException {
if (data == null || data.isEmpty()) {
return true;
}
long nanos = unit.toNanos(timeout);
// 尝试获取整个全局锁
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
for (;;) {
// 循环下不断检查是否有足够的空间可以写入数据
// 这里需要的空间 = 队列中put的位置 + 当前写入的数据量
if (checkFreeSlotAt(putSequence.get() + data.size())) {
doPut(data);
return true;
}
// 如果超时了则直接返回
if (nanos <= 0) {
return false;
}
try {
// 等待一段时间,除非有唤醒时立即返回剩余等待时间
nanos = notFull.awaitNanos(nanos);
} catch (InterruptedException ie) {
notFull.signal();
throw ie;
}
}
} finally {
lock.unlock();
}
} 带超时时间的put逻辑还是比较清晰的,在死循环里通过调用checkFreeSlotAt方法不断检查是否有足够的空间用于存储数据,一旦超出规定的时间则立即返回false。
/**
* 查询是否有空位
*/
private boolean checkFreeSlotAt(final long sequence) {
// putSequence + dataSize - bufferSize,得出超出队列总大小之后,还需要多大的空间
final long wrapPoint = sequence - bufferSize;
// 获取ack和get两个下标的最小值,正常应该都是返回ack的位置,这里我没看懂为啥要加这个
final long minPoint = getMinimumGetOrAck();
// 这里如果如果需要的空间大于ack的空间,则不够当前数据塞入,需要等待消费
if (wrapPoint > minPoint) { // 刚好追上一轮
return false;
} else {
// 在bufferSize模式上,再增加MEMSIZE控制,检查是否塞入的数据超出内存大小限制
if (batchMode.isMemSize()) {
// 使用putMemSize值减去ackMemSize值,得到当前保存的event事件占用的总内存
// 这里计算出来的结果就是还没被ack的event,跟进一步说可能是没被消费的数据
// (有可能目前没有client在消费)
final long memsize = putMemSize.get() - ackMemSize.get();
// 如果没被消费的数据占用的内存大小大于bufferSize * bufferMemUnit,则不允许塞入数据
if (memsize < bufferSize * bufferMemUnit) {
return true;
} else {
return false;
}
} else {
return true;
}
}
}ringbuffer中设计,从ack到put两个下标之间的数据是未被消费或者ack的数据,也就是ringbuffer中的有效数据,而其余的空间是可以被回收的,尽管上面可以不为null。
这里canal在设计put操作的过程中,除了检查是否有足够的slot去插入数据之外,还检查了当前有效数据占用的内存空间是否超出的总的内存大小(bufferSize * bufferMemSize),不过可以看到这里的计算并不是特别严谨,计算时并没有加上当前准备写入的数据所占用的空间大小,也就是说一开始插入的数据可能是大于16M的(mysql binlog event限制最大是8M),假设现在再来一波数据总内存占用大于16M的,就必须得等待client全部消费完,直到有效数据占用空间 = 0了,则可以继续插入数据。
现在回头看doPut方法,这里是实际插入数据到ringbuffer内存数组中的逻辑,前面只是做空间的计算
private void doPut(List data) {
long current = putSequence.get();
long end = current + data.size();
// 这里有些时候是每写入数据就更新一次putSequence的值
// 作者这里是先写数据,再更新对应的cursor,
// 避免并发度高的情况,putSequence会被get请求可见,拿出了ringbuffer中的老的Entry值
// 笔者倒不认为会拿到老的值,不过保险一点全部写完再修改putSequence也没问题
for (long next = current + 1; next <= end; next++) {
// next - sequence - 1 取出即将写入的下一条数据
// 这里也可以用多一个for循环负责从data中取数据
entries[getIndex(next)] = data.get((int) (next - current - 1));
}
// 写完了再更新putSequence的值
// 这里要注意的是putSequence不是设置为数组的下标,而是event插入的记录数
// ringbuffer只是实际设计上是允许从0开始插入,但是逻辑上的下标确实要不断递增
// 所以这几个sequence都是设计为long类型
putSequence.set(end);
// 记录一下gets memsize信息,方便快速检索
if (batchMode.isMemSize()) {
long size = 0;
for (Event event : data) {
size += calculateSize(event);
}
putMemSize.getAndAdd(size);
}
// 监控指标,给prometheus使用的
profiling(data, OP.PUT);
// 写完数据,唤醒其他等待线程,例如get请求再苦苦等待是否有数据
notEmpty.signal();
} 这里需要注意的是在数组中下标的计算方式,由于内部实现是ringbuffer,所以需要在put的位置超出数组本身的大小之后,又从0开始写入,这里是由getIndex方法实现计算
private int getIndex(long sequcnce) {
// 将当前写入的位置对整个队里的大小求余即可得出要插入的下标位置
return (int) sequcnce & indexMask;
}除了插入数据之外,这里的doPut还计算了当前event占用大小
private long calculateSize(Event event) {
// 直接返回binlog中的事件大小
return event.getRawLength();
}这里的原理是mysql的binlog中会代用当前event的大小,所以在parser模块解析完成后直接获取这个值即可,不过这里获取结果并不一定就是准的,原始的event_length表示的是event是二进制字节流时的字节数,在转换成java对象后,基本上都会变大。
3.2、Get操作
相比于put请求,get请求会复杂一些,同样的它也有三个相关方法
// 尝试获取,如果获取不到立即返回
public Events tryGet(Position start, int batchSize) throws CanalStoreException
// 获取指定大小的数据,阻塞等待其操作完成
public Events get(Position start, int batchSize) throws InterruptedException, CanalStoreException
// 获取指定大小的数据,阻塞等待其操作完成或者超时,如果超时了,有多少,返回多少
public Events get(Position start, int batchSize, long timeout, TimeUnit unit)
throws InterruptedException,CanalStoreException 以带有超时时间的get请求为例来分析
public Events get(Position start, int batchSize, long timeout, TimeUnit unit) throws InterruptedException,
CanalStoreException {
long nanos = unit.toNanos(timeout);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
for (;;) {
// 检查是否有可以get的数据
if (checkUnGetSlotAt((LogPosition) start, batchSize)) {
return doGet(start, batchSize);
}
if (nanos <= 0) {
// 如果时间到了,有多少取多少
return doGet(start, batchSize);
}
try {
nanos = notEmpty.awaitNanos(nanos);
} catch (InterruptedException ie) {
notEmpty.signal(); // propagate to non-interrupted thread
throw ie;
}
}
} finally {
lock.unlock();
}
}
/**
* 检查是否存在需要get的数据,并且数量>=batchSize
*/
private boolean checkUnGetSlotAt(LogPosition startPosition, int batchSize) {
// 如果内存模式是ITEMSIZE
if (batchMode.isItemSize()) {
// 获取从get的位置以及put的位置
long current = getSequence.get();
long maxAbleSequence = putSequence.get();
long next = current;
if (startPosition == null || !startPosition.getPostion().isIncluded()) { // 第一次订阅之后,需要包含一下start位置,防止丢失第一条记录
next = next + 1;// 少一条数据
}
if (current < maxAbleSequence && next + batchSize - 1 <= maxAbleSequence) {
return true;
} else {
return false;
}
} else {
// 处理内存大小判断
// 这里是为了避免get固定batchSize的消息,数据大小太大导致OOM
// 要记住拿出的数据要再内存序列话,这也相当于复制一份
long currentSize = getMemSize.get();
long maxAbleSize = putMemSize.get();
if (maxAbleSize - currentSize >= batchSize * bufferMemUnit) {
return true;
} else {
return false;
}
}
} 这里摘抄一下别人的文章:
关于1.1步的描述"第一次订阅之后,需要包含一下start位置,防止丢失第一条记录”,这里进行一下特殊说明。首先要明确checkUnGetSlotAt方法的startPosition参数到底是从哪里传递过来的。
当一个client在获取数据时,CanalServerWithEmbedded的getWithoutAck/或get方法会被调用。其内部首先通过CanalMetaManager查找client的消费位置信息,由于是第一次,肯定没有记录,因此返回null,此时会调用CanalEventStore的getFirstPosition()方法,尝试把第一条数据作为消费的开始。而此时CanalEventStore中可能有数据,也可能没有数据。在没有数据的情况下,依然返回null;在有数据的情况下,把第一个Event的位置作为消费开始位置。那么显然,传入checkUnGetSlotAt方法的startPosition参数可能是null,也可能不是null。所以有了以下处理逻辑:
if (startPosition == null || !startPosition.getPostion().isIncluded()) {
next = next + 1;
}如果不是null的情况下,尽管把第一个event当做开始位置,但是因为这个event毕竟还没有消费,所以在消费的时候我们必须也将其包含进去。之所以要+1,因为是第一次获取,getSequence的值肯定还是初始值-1,所以要+1变成0之后才是队列的第一个event位置。关于CanalEventStore的getFirstPosition()方法,我们将在最后分析。当通过checkUnGetSlotAt的检查条件后,通过doGet方法进行真正的数据获取操作,获取主要分为5个步骤:
- 确定从哪个位置开始获取数据
- 根据batchMode是MEMSIZE还是ITEMSIZE,通过不同的方式来获取数据
- 设置PositionRange,表示获取到的event列表开始和结束位置
- 设置ack点
- 累加getSequence,getMemSize值
private Events doGet(Position start, int batchSize) throws CanalStoreException {
LogPosition startPosition = (LogPosition) start;
long current = getSequence.get();
long maxAbleSequence = putSequence.get();
long next = current;
long end = current;
// 如果startPosition为null,说明是第一次,默认+1处理
if (startPosition == null || !startPosition.getPostion().isIncluded()) { // 第一次订阅之后,需要包含一下start位置,防止丢失第一条记录
next = next + 1;
}
if (current >= maxAbleSequence) {
return new Events<>();
}
Events result = new Events<>();
List entrys = result.getEvents();
long memsize = 0;
if (batchMode.isItemSize()) {
end = (next + batchSize - 1) < maxAbleSequence ? (next + batchSize - 1) : maxAbleSequence;
// 提取数据并返回
for (; next <= end; next++) {
Event event = entries[getIndex(next)];
if (ddlIsolation && isDdl(event.getEventType())) {
// 如果是ddl隔离,直接返回
if (entrys.size() == 0) {
entrys.add(event);// 如果没有DML事件,加入当前的DDL事件
end = next; // 更新end为当前
} else {
// 如果之前已经有DML事件,直接返回了,因为不包含当前next这记录,需要回退一个位置
end = next - 1; // next-1一定大于current,不需要判断
}
break;
} else {
entrys.add(event);
}
}
} else {
// 从数组中拿出足够的数据并返回
long maxMemSize = batchSize * bufferMemUnit;
// 这里除了判断数量之外,也判断了拿出的数据的大小不能超出maxMemSize
// 猜测是对get的内存同样做了限制,这批数据copy复制一份进行序列化之后
// 发送给client,所以限制大小避免使用内存过大OOM
for (; memsize <= maxMemSize && next <= maxAbleSequence; next++) {
// 永远保证可以取出第一条的记录,避免死锁
Event event = entries[getIndex(next)];
if (ddlIsolation && isDdl(event.getEventType())) {
// 如果是ddl隔离,直接返回
if (entrys.size() == 0) {
entrys.add(event);// 如果没有DML事件,加入当前的DDL事件
end = next; // 更新end为当前
} else {
// 如果之前已经有DML事件,直接返回了,因为不包含当前next这记录,需要回退一个位置
end = next - 1; // next-1一定大于current,不需要判断
}
break;
} else {
entrys.add(event);
memsize += calculateSize(event);
end = next;// 记录end位点
}
}
}
PositionRange range = new PositionRange<>();
result.setPositionRange(range);
range.setStart(CanalEventUtils.createPosition(entrys.get(0)));
range.setEnd(CanalEventUtils.createPosition(entrys.get(result.getEvents().size() - 1)));
range.setEndSeq(end);
// 记录一下是否存在可以被ack的点
for (int i = entrys.size() - 1; i >= 0; i--) {
Event event = entrys.get(i);
// GTID模式,ack的位点必须是事务结尾,因为下一次订阅的时候mysql会发送这个gtid之后的next,如果在事务头就记录了会丢这最后一个事务
if ((CanalEntry.EntryType.TRANSACTIONBEGIN == event.getEntryType() && StringUtils.isEmpty(event.getGtid()))
|| CanalEntry.EntryType.TRANSACTIONEND == event.getEntryType() || isDdl(event.getEventType())) {
// 将事务头/尾设置可被为ack的点
range.setAck(CanalEventUtils.createPosition(event));
break;
}
}
if (getSequence.compareAndSet(current, end)) {
getMemSize.addAndGet(memsize);
// 这里get请求本质上不应该唤醒,应该只有ack操作才能唤醒put操作
notFull.signal();
profiling(result.getEvents(), OP.GET);
return result;
} else {
return new Events<>();
}
} 这里除了get数据之外,还构建了一个positionRange,在找到即将发送的event列表之后,会从中逆序寻找第一个类型为"事务开始/事务结束/DDL"的Event,将其位置作为PostionRange的可ack位置。
mysql原生的binlog事件中,总是以一个内容”BEGIN”的QueryEvent作为事务开始,以XidEvent事件表示事务结束。即使我们没有显式的开启事务,对于单独的一个更新语句(如Insert、update、delete),mysql也会默认开启事务。而canal将其转换成更容易理解的自定义EventType类型:TRANSACTIONBEGIN、TRANSACTIONEND。
而将这些事件作为ack点,主要是为了保证事务的完整性。例如client一次拉取了10个binlog event,前5个构成一个事务,后5个还不足以构成一个完整事务。在ack后,如果这个client停止了,也就是说下一个事务还没有被完整处理完。尽管之前ack的是10条数据,但是client重新启动后,将从第6个event开始消费,而不是从第11个event开始消费,因为第6个event是下一个事务的开始。
具体逻辑在于,canal server在接受到client ack后,CanalServerWithEmbedded#ack方法会执行。其内部首先根据ack的batchId找到对应的PositionRange,再找出其中的ack点,通过CanalMetaManager将这个位置记录下来。之后client重启后,再把这个位置信息取出来,从这个位置开始消费。
也就是说,ack位置实际上提供给CanalMetaManager使用的。而对于MemoryEventStoreWithBuffer本身而言,也需要进行ack,用于将已经消费的数据从队列中清除,从而腾出更多的空间存放新的数据。
随后如果client发生中断需要重新消费数据,则可以从某一个事务头开始消费,可以起到事务一致性的作用。
3.3、ack操作
相比于get和put操作,ack操作就比较简单,负责清理数据和重置下ackSequenct的位置。主要调用了cleanUtil方法执行
public void cleanUntil(Position position, Long seqId) throws CanalStoreException {
final ReentrantLock lock = this.lock;
lock.lock();
try {
long sequence = ackSequence.get();
long maxSequence = getSequence.get();
boolean hasMatch = false;
long memsize = 0;
// ack没有list,但有已存在的foreach,还是节省一下list的开销
long localExecTime = 0L;
int deltaRows = 0;
if (seqId > 0) {
maxSequence = seqId;
}
// 清理ack到get两个下标之间的数据
for (long next = sequence + 1; next <= maxSequence; next++) {
Event event = entries[getIndex(next)];
if (localExecTime == 0 && event.getExecuteTime() > 0) {
localExecTime = event.getExecuteTime();
}
// mysql binlog里一个event可能存在多行,这里要记住,但是event的大小都是统计所有row的
deltaRows += event.getRowsCount();
memsize += calculateSize(event);
// 这里的seqId对应文件队列中的get请求获取的positionRange的end的下标
// 当ack没有获取这个值的时候,需要根据position去文件队列中找到对应的位置,执行清理操作
if ((seqId < 0 || next == seqId) && CanalEventUtils.checkPosition(event, (LogPosition) position)) {
// 找到对应的position,更新ack seq
hasMatch = true;
if (batchMode.isMemSize()) {
ackMemSize.addAndGet(memsize);
// 尝试清空buffer中的内存,将ack之前的内存全部释放掉
for (long index = sequence + 1; index < next; index++) {
entries[getIndex(index)] = null;// 设置为null
}
// 考虑getFirstPosition/getLastPosition会获取最后一次ack的position信息
// ack清理的时候只处理entry=null,释放内存
Event lastEvent = entries[getIndex(next)];
lastEvent.setEntry(null);
lastEvent.setRawEntry(null);
}
// 采用cas操作避免并发ack,同时唤醒put操作避免插入操作一直等待
if (ackSequence.compareAndSet(sequence, next)) {
notFull.signal();
ackTableRows.addAndGet(deltaRows);
if (localExecTime > 0) {
ackExecTime.lazySet(localExecTime);
}
return;
}
}
}
if (!hasMatch) {// 找不到对应需要ack的position
throw new CanalStoreException("no match ack position" + position.toString());
}
} finally {
lock.unlock();
}
}从这里ack的逻辑也说明了,内存队列目前只能有一个client去消费(笔者就曾经开了多个消费者去消费数据,不看wiki的结果T_T)
注意,这里的ackSequence不一定会设置为getSequence的位置,前面说了get操作会记录一个positionRange,如果positionRange在最后一个事务后面还有数据,那么ack设置到最后一个事务的end位置,不会是getSequence的位置,为了尽可能做到事务一致性。
4、总结
canal内存队列模拟了ringbuffer的实现,本质上是一个生产-消费模型的实现,所以在很多put、get和ack的操作存在对同一个型号量的await和signal操作。除此之外还需要不断保证ackSequence、putSequence和getSequence三者之间关系的保持和计算,对内存使用也有一定的限制。内存队列中的其他方法实现就不列举了(嘻嘻),详细可以看下下面老哥的博客介绍。
笔者没看内存队列之前还没注意到,ringbuffer的sequence都是需要不断递增的, 一开始还以为是超出队列大小就从0开始。。。囧
还有一点,会发现除了put之外,ack和get都是用了cas操作,估计是因为后续扩展是留下的,put是铁定只能有一个,但是ack和get后续如果有支持多个client的话这里用cas
5、引用
田守枝-CANAL源码解析