二十一章:PUZZLE-CAM:通过匹配局部和全局特征来改进定位
0.摘要
弱监督语义分割(WSSS)被引入来缩小从像素级监督到图像级监督的语义分割性能差距。大多数先进的方法是基于类激活图(CAM)来生成伪标签以训练分割网络。WSSS的主要局限性在于从使用图像分类器的CAM生成伪标签的过程主要集中在对象的最具区分性的部分。为了解决这个问题,我们提出了Puzzle-CAM,它通过最小化分割网络中独立补丁和整个图像特征之间的差异来发现对象中最一体化的区域。我们的方法包括一个拼图模块和两个正则化项。Puzzle-CAM可以利用图像级监督激活对象的整个区域,而不需要额外的参数。在实验中,Puzzle-CAM在PASCAL VOC 2012数据集上使用相同的标签进行监督,优于先前的最先进方法。与我们实验相关的代码可以在https://github.com/OFRIN/PuzzleCAM找到。
索引词 - 图像分割,深度学习,神经网络,弱监督语义分割
1.引言
语义分割是一种使用卷积神经网络(CNN)的基本方法,其目的是正确预测图像的像素级分类。最近,全监督语义分割(FSSS)取得了显著的进展[1,2,3]。然而,为每个图像制作具有精确像素级注释的大规模训练数据集非常昂贵,需要耗时耗力的任务。为了解决这个问题,许多研究人员专注于弱监督语义分割(WSSS),它使用图像级别的注释、涂鸦、边界框和点来训练网络。与其他方法相比,图像级别的监督更容易进行。在本研究中,我们只关注使用图像级别监督来学习语义分割模型。
大多数先前的WSSS方法[4,5,6]基于类激活图(CAMs)[7]来实现良好的性能。然而,生成的CAMs通常只关注语义对象的小部分,以有效分类它们,这阻止了分割模型学习像素级的语义知识。此外,我们可以看到,从平铺图像中的孤立补丁生成的CAMs与原始图像中获得的CAMs不同。如图1所示,由平铺补丁组成的平铺图像的CAMs与原始图像的CAMs明显不一致。这些差异进一步扩大了FSSS和WSSS之间的监督差距。
上述观察结果启发我们使用基于注意力的特征学习方法来解决WSSS问题。因此,我们提出了Puzzle-CAM用于WSSS训练,以检测对象的整合区域。我们的方法应用了与从平铺和原始图像生成的CAMs对应的重构正则化来提供自我监督。为了进一步改善网络预测的一致性,我们引入了一个拼图模块,将图像分割并合并从平铺图像生成的CAMs。
Puzzle-CAM由一个具有重构正则化损失的孪生神经网络组成,该损失减少了原始和合并的CAM之间的差异。我们的实验产生了定量和定性结果,证明了我们方法的优越性。我们的主要贡献如下:
- 我们提出了Puzzle-CAM,它结合了重构正则化和拼图模块,有效提高了CAM的质量,而不需要增加网络层。
- 在PASCAL VOC 2012数据集上,Puzzle-CAM在相同级别的监督下表现优于现有的最先进方法。
图1:从平铺和原始图像生成的CAMs:(a)来自原始图像的传统CAMs,(b)来自平铺图像的生成CAMs,以及(c)由提出的Puzzle-CAM预测的CAMs。
图2:提出的Puzzle-CAM的整体架构,显示了重构正则化和拼图模块的集成。
2.相关工作
2.1.使用CNN的注意力机制
这些提供了CNN中学习到的特征的细粒度信息。Simonyan等人[8]使用误差反向传播策略来可视化语义区域,而联合注意力模型使用CNN中的全局平均池化(GAP)层更高效地生成CAMs [7]。最后,使用最终的分类器生成注意力图。据我们所知,在实现WSSS的高性能方面,选择哪种注意机制并没有太大的影响,因此我们基于联合注意力模型构建了Puzzle-CAM,因为它比其他注意机制更易于处理。
2.2.弱监督语义分割
与需要对图像进行逐像素标记的FSSS不同,WSSS采用了较低级别的标记,如边界框[9]、涂鸦[10]和图像级别的分类标签[4,6]。最近,通过引入CAMs,WSSS的性能得到了显著提升。大多数先前的WSSS方法通过对图像分类器生成的CAMs进行细化,以逼近分割掩码[4,11,12,13,6]。AffinityNet [4]训练了一个额外的网络来学习像素之间的相似性,通常生成一个过渡矩阵,并将其与CAM相乘以调整其激活范围。IRNet [11]从边界激活图生成过渡矩阵,并扩展该方法以实现弱监督实例分割和WSSS。SEAM [5]旨在通过使用捕捉每个像素的上下文外观信息的像素相关模块来改进CAMs,并通过使用学习到的亲和力注意力图来改变原始的CAMs。
3.方法论
3.1.动机
传统的单个图像的CAM高亮显示了每个类别最具代表性的区域。因此,当为图像块生成同一类别的CAM时,模型只使用对象的一部分来寻找类别的关键特征。因此,图像块的合并CAM比单个图像的CAM更准确地突出了对象区域。为了利用上述优势,我们提出了Puzzle-CAM,它使用重构损失训练分类器,以最小化单个图像的CAM和从图像块合并的CAM之间的差异。通过使用这种重构损失训练分类网络,CAM更精确地覆盖了对象区域。Puzzle-CAM包含设计的损失函数,以匹配从平铺图像生成的CAM与原始图像的CAM(图2)。
3.2.雇佣的CAM方法
首先,我们介绍用于生成初始注意力图的CAM方法。给定特征提取器F和分类器θ,我们可以生成CAMs,这是所有类别的CAM的集合。通过图像级别监督训练分类器后,我们将c通道分类器的权重应用于从输入图像I得到的特征图f =F(I),以获得类别c的CAM,如下所示: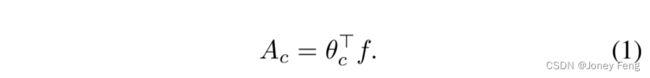
通过使用Ac的最大值对生成的CAM进行归一化。最后,通过连接Ac,我们获得了所有类别的CAMs(A)。
3.3.拼图模型
在匹配部分特征和完整特征时,关键是缩小FSSS和WSSS之间的差距。拼图模块由平铺和合并模块组成。从大小为W×H的输入图像I开始,平铺模块生成大小为W=2×H=2的非重叠的平铺块fI1;1;I1;2;I2;1;I2;2g。接下来,我们为每个Ii;j生成Ai;j的CAMs。最后,合并模块将所有的Ai;j连接到一个具有与I的CAMs相同形状的单个CAMs Are中。
3.4.Puzzle-CAM的损失设计
我们在网络末端采用了一个GAP层,用于融合预测向量Y^=σ(G(Ac))进行图像分类,并采用多标签软边缘损失进行分类任务。为了方便表示,我们定义Yt为:
其中α是用于不同损失的权重平衡系数。分类损失Lcls和Lp−cls用于粗略估计对象的区域。重构损失Lre用于缩小像素级和图像级监督过程之间的差距。我们在实验部分报告了网络训练设置的详细信息,并对所提出的模块的有效性进行了探究。
表1:使用ResNet-50作为骨干网络的Puzzle-CAM损失函数的消融研究。
4.实验结果
4.1.实现细节
我们使用了PASCAL VOC 2012数据集[14]来评估我们的方法。该数据集被分为了1,464张图片用于训练,1,449张用于验证,1,456张用于测试。按照之前方法[4,5,6]使用的实验协议,我们从语义边界数据集[15]中获取了额外的注释,构建了一个包含10,582张图片的增强训练集。这些图片在[320,640]的范围内进行随机缩放,然后裁剪为512×512作为网络的输入。对于所有实验,我们将α设置为4,并在半个epoch内线性地将α逐渐增加到最大值。在推断过程中,我们使用不带拼图模块的分类器。因此,我们采用了多尺度和水平翻转来生成伪分割标签。我们使用了四个TITAN-RTX GPU来训练数据集。
4.2.消融研究
通过应用平均交并比(mIoU)指标(Table 1),我们对Puzzle-CAM的主要组成部分进行了消融研究,其中基线为mIoU = 47.82%。通过提出的平铺块的重构规范化(Lre),基线提升到了mIoU = 49.21%,而来自平铺块的分类损失(Lp-cls)与基线相似。Lre和Lp-cls都持续提高了基线3.71%。我们使用它们的损失函数组合来可视化CAMs(见公式3)。当仅使用分类损失(Lp-cls)时,结果不会显示边际差异。同时,当仅使用重构损失(Lre)时,结果相比原始结果对某些类别具有更好的定位能力,但该方法无法预测几个类别。当两组损失结合时,结果显示出改进的定位能力,而不会遭受分类损失。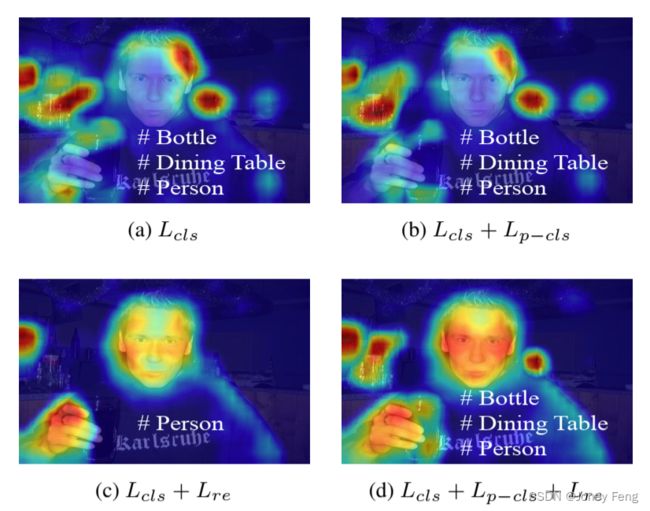
图3:使用损失函数组合可视化预测标签和CAMs。在(d)中,最终的CAMs不仅抑制了过度激活,还将CAMs扩展到完整的对象激活范围。
表2:在PASCAL VOC 2012训练集[14]上评估的伪语义分割标签的mIoU质量。RW,使用AffinityNet的随机游走方法[4];dCRF,密集条件随机场[16]。
4.3.与现有的最先进方法的比较
为了进一步提高伪像素级注释的准确性,我们按照[4]中的方法,使用Puzzle-CAM训练了AffinityNet。我们采用了ResNeSt架构,它能普遍改进学习到的特征表示,提升图像分类、目标检测、实例分割和语义分割的性能。在表2中,我们报告了基线AffinityNet [4]和Puzzle-CAM使用的原始CAM的性能表现。
最终合成的伪标签在PASCAL VOC 2012训练集上达到了74.67%的mIoU。然后,使用Puzzle-CAM以全监督模式使用伪标签来训练具有ResNeSt-269[18]骨干的DeepLabv3+[1]分割模型,以获得最终的分割结果。表3比较了所提出方法和先前方法的mIoU值。与基线方法相比,Puzzle-CAM在相同的训练设置下在验证集和测试集上的性能显著提高。图4显示了验证集上的一些定性结果,说明所提出的方法在大型和小型对象上都效果良好。
表3:在PASCAL VOC 2012验证集和测试集上,Puzzle-CAM与现有的最先进方法的比较。I表示图像级标签;S表示外部显著性模型。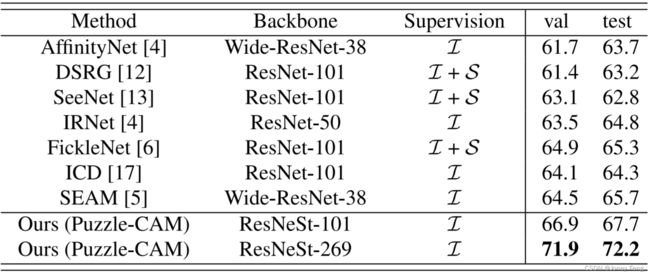

图4:PASCAL VOC 2012验证集上的定性分割结果。顶部:原始图像。中间:真实标注。底部:使用Puzzle-CAM生成的伪标签训练的分割模型的预测结果。
5.结论
在本文中,我们提出了Puzzle-CAM算法,利用图像级标签来缩小全监督语义分割(FSSS)和弱监督语义分割(WSSS)之间的监督差距。为了改进生成一致CAM的网络,我们设计了一个拼图模块,并采用了重构正则化来匹配局部特征和全局特征。Puzzle-CAM不仅能够一致地生成来自局部平铺补丁的特征,而且还更好地适应了真实标注掩码的形状。通过使用我们合成的像素级伪标签训练的分割网络在PASCAL VOC 2012数据集上取得了最先进的性能,这证明了我们方法的有效性。我们相信,Puzzle-CAM作为一个训练模块的概念可以推广,并且将有益于其他弱监督和半监督任务,如语义分割和实例分割。