十大开源GPT替代模型,实现属于你自己的chatGPT
文章目录
-
-
- LLaMA
- Alpaca
- Alpaca-LoRA
- Chinese-Vicuna
- BLOOM
- BELLE
- T5
- BERT
- OPT
- GLM
-
公众号: MCNU云原生,文章首发地,欢迎微信搜索关注,更多干货,第一时间掌握!
今年chatGPT真的是出尽了风头,搞得好像凡是不讲chatGPT的都是村里还没通网络的,各种技术平台也是充斥着人工智能的相关文章,凡是不谈人工智能的感觉都要跟不上时代了~
社区里面不少朋友们都在咨询LLM大预言模型的相关内容,另外都特别纠结不的话用不了chatGPT。于是乎,我认真准备了几天,终于梳理完这篇文章的内容,那就是开源的大语言模型,可以作为chatGPT的替换方案,让每个人都可以拥有自己的大语言模型。
本文梳理出来10个当前最热门、效果最好的10个开源LLM模型,让你体验一把自己玩转模型的快乐。
LLaMA
- github项目名称:facebookresearch/llama
- Star数量:21.5K

LLaMA是Large Language Model Meta AI的缩写,它是Meta开源的一个基础大语言模型,它具有多个模型版本,参数规模从70亿、130亿到300亿、650亿,其中LLaMA-13B在大多数基准上超过了GPT-3(175B),而LLaMA-65B与最好的模型Chinchilla70B和PaLM-540B相比也具有竞争力。
LLaMA是一种先进的基础大语言模型,旨在帮助研究人员推进他们在 AI 子领域的工作,LLaMA 等更小、性能更高的模型使得基础设施资源有限的研究者们也可以玩转大语言模型。
LLaMA需要更少的算力,适合对各种任务进行微调在生成创意文本、解决数学定理、回答阅读理解问题等方面表现优秀。
Alpaca
- github项目名称:tatsu-lab/stanford_alpaca
- Star数量:23.9K

Alpaca模型是stanford开源的一种轻量级的语言模型,它可以根据用户输入的指令来生成不同类型的文本,例如邮件、社交媒体、生产性工具等。Alpaca模型是基于LLaMA模型微调而来的,LLaMA模型是Meta公司发布的一系列大规模的预训练语言模型。
Alpaca模型的训练方法分为两个部分:第一部分是使用self-instruct思想,利用text-davinci-003模型来自动生成指令和输出的数据集;第二部分是在这个数据集上通过监督学习来微调LLaMA模型。Alpaca模型的训练成本非常低,只需要在8张A100 80G上训练3个小时,花费不到100美元。
Alpaca模型的性能也非常出色,在单轮指令执行的效果上,Alpaca模型的回复质量和text-davinci-003模型相当,但是Alpaca模型的参数量只有7B,而text-davinci-003模型的参数量有175B。Alpaca模型还可以适用于消费级显卡,通过使用LoRA技术来降低内存占用和计算量。
Alpaca模型是一个开源的项目,它继承了LLaMA模型的开源协议,仅限于学术研究,其模型的训练数据和代码都可以在GitHub上找到。
alpaca这个词还有另一个意思,是一种南美洲的驼科动物,它和羊驼很像,但是通常比羊驼小一些,所以也被人们称为“羊驼模型”。
alpaca发布以后,在国内广受欢迎,属于非常热门的一个替代模型。
Alpaca-LoRA
- github项目名称:tloen/alpaca-lora
- Star数量:14.7K
alpaca-lora模型是一种使用lora技术在llama模型上进行微调的轻量级语言模型,它可以根据用户输入的指令来生成不同类型的文本,例如邮件、社交媒体、生产性工具等。alpaca-lora模型是基于alpaca模型改进而来的,alpaca模型是Stanford大学的研究者开源的,它是基于Meta公司的llama模型微调而来的。
lora技术是一种低秩适应(low-rank adaptation)的技术,它可以在冻结原模型llama参数的情况下,通过往模型中加入额外的网络层,并只训练这些新增的网络层参数。由于这些新增参数数量较少,这样不仅微调的成本显著下降,还能获得和全模型微调类似的效果。
alpaca-lora模型的训练方法分为两个部分:第一部分是使用self-instruct思想,利用text-davinci-003模型来自动生成指令和输出的数据集;第二部分是在这个数据集上通过监督学习来微调llama模型,并使用lora技术来减少参数量。alpaca-lora模型的训练成本非常低,只需要在一块RTX 4090显卡上训练5个小时,就可以训练出一个与alpaca水平相当的模型。
微调是非常重要的一项能力,实际上很多大语言模型要真正应用于某些特定场景必须经过微调,而lora是进行微调的一个效果比较好的常规方案。
Chinese-Vicuna
- github项目名称:Facico/Chinese-Vicuna
- Star数量:2.9K
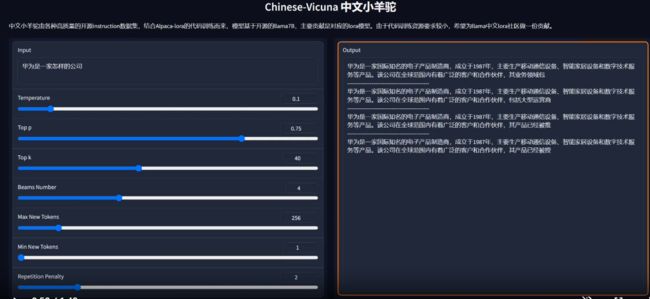
Chinese-Vicuna是一个中文低资源的llama+lora方案,基于LLaMA+instruction数据构建,这个模型的主要特点是对中文更加友好地支持,参数高效,显卡友好,部署简易,使用较少的资源训练出较好地效果。
官方介绍,模型对资源地消耗比较小,例如
- 在一张2080Ti(11G)上可以对Llama-7B进行指令微调
- 在一张3090(24G)上可以对Llama-13B进行指令微调
- 即使是长度为2048的对话,在3090上也可以完成Llama-7B的微调;使用5万条数据即可有不错效果
如果你的需求是尽量少的资源,使用某些垂直场景的数据进行微调,需要对中文更友好地支持,这个模型是个不错的选择。
BLOOM
- 项目名称(huggingface托管):bigscience/bloom
- Star数量:3.5K

BLOOM模型是bigscience开源的大语言模型,它是BigScience Large Open-science Open-access Multilingual Language Model的缩写。BLOOM是在46种自然语言和13种编程语言上训练的1760亿参数语言模型,其是由数百名研究人员合作开发和发布的。
Bloom模型通过Transformer架构实现,利用自注意力机制和大规模训练数据对语言进行建模。通过在海量文本数据上进行预训练,Bloom模型能够学习到丰富的语言表示和语义知识,从而具备强大的语言理解和生成能力。
BLOOM 的模型架构与 GPT3 非常相似,但是做了一些改进,最突出的特点是千亿级别的参数规模,使得Bloom模型在语言理解和生成任务中能够表现出色,另外BLOOM支持多模态,使得Bloom模型在处理与语言相关的多模态任务时具备优势,如视觉问答、图像描述生成等。
总体来说,BLOOM在语言生成、文本理解和分类、问答、迁移学习、可解释性与可控性方面表现良好,可以在机器翻译、摘要生成、情感分析、对话系统、信息检索等场景应用,目前国内已有部分企业在落地应用。
BELLE
- github项目名称:LianjiaTech/BELLE
- Star数量:5.3K

BELLE是Be Everyone’s Large Language model Engine的缩写,是一个开源的中文对话大模型,BELLE更关注如何在开源预训练大语言模型的基础上,帮助每一个人都能够得到一个属于自己的、效果尽可能好的具有指令表现能力的语言模型,降低大语言模型、特别是中文大语言模型的研究和应用门槛。
BELLE模型是一种基于深度神经网络的大规模多模态语言模型。它将语言和视觉信息相结合,通过联合学习来理解和生成多模态数据。BELLE模型采用了先进的神经网络架构,如Transformer和卷积神经网络(CNN),以实现对文本和图像等多模态数据的深度表示学习。
BELLE在多模态学习、语言理解与生成能力、视觉问答、视觉推理、图像描述生成等方面表现优秀。
T5
- github项目名称:google-research/text-to-text-transfer-transformer
- Star数量:5.2K
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QN7ZplUd-1688387606762)(http://image.mcnu.tech/mcnu/T5.jpg)]
T5(Text-to-Text Transfer Transformer)模型是google开源的一种基于Transformer架构的大型预训练语言模型,被广泛应用于自然语言处理(NLP)领域。T5模型以"Text-to-Text"的方式统一了各种NLP任务的表达方式,通过将不同任务转化为文本到文本的转换问题,实现了多任务学习和迁移学习的能力。
T5模型的突出重点能力:
- 多任务学习:T5模型能够同时处理多个不同的NLP任务,包括机器翻译、文本摘要、问答系统、文本分类等。通过在大规模数据上进行联合训练,T5模型能够学习到通用的语言表示和任务处理能力,从而在多个任务上展现出色的性能。
- 迁移学习:由于T5模型在多任务学习中进行了大规模预训练,它具备较强的迁移学习能力。这意味着T5模型在新的任务上可以通过微调少量的任务特定数据,快速适应并取得优秀的表现,从而降低了针对不同任务的训练成本和时间。
- 通用的文本到文本框架:T5模型采用了统一的文本到文本框架,即将输入和输出都表示为文本序列。这种设计使得T5模型能够在处理不同任务时具有一致的表达形式,简化了模型的设计和应用。通过适当的任务描述和输入形式,T5模型可以根据任务的不同进行转换,实现灵活且高效的多任务处理。
T5模型的应用场景:
- 机器翻译:T5模型可以用于将一个语言翻译成另一个语言,实现高质量的自动翻译,有助于促进跨语言交流和信息传播。
- 文本摘要:T5模型能够将长文本内容进行概括和提炼,生成简洁准确的文本摘要,有助于处理大量信息和快速获取关键信息。
- 问答系统:T5模型可以用于问答任务,根据问题提供准确的答案或解决方案,使得问答系统更具智能和实用性。
- 文本分类:T5模型能够对文本进行分类,识别文本所属的类别或标签,如情感分析、垃圾邮件过滤、新闻分类等。
- 自动文本生成:T5模型具备强大的文本生成能力,可以生成
- 自动对话系统:T5模型在对话系统中具有广泛应用。它可以根据用户的输入生成自然流畅的回复,实现智能对话和交互。
- 文本纠错和改写:T5模型可以用于纠正文本中的拼写错误、语法错误或重写不通顺的句子,提供文本的修正和改进建议。
- 文本生成和创作助手:T5模型在文本生成领域表现出色,可以用于生成文章、故事、诗歌等各种文本形式,为创作者提供灵感和辅助创作。
- 信息检索和推荐:T5模型可以用于对用户的查询进行理解,并根据用户需求生成相关的搜索结果或推荐信息,提升信息检索和推荐系统的精准度和个性化程度。
- 领域专属任务:T5模型具备很强的灵活性和可扩展性,可以通过微调和领域自适应进行定制化,适用于特定领域的任务,如医疗领域的病历摘要、法律领域的法律文件分析等。
T5模型是一种强大的大规模预训练语言模型,在多任务学习和迁移学习方面具备突出能力。它在机器翻译、文本摘要、问答系统、文本分类等任务中展现出色的性能,并在多个应用场景中发挥重要作用,为自然语言处理领域的发展带来了巨大的推动力。
BERT
- github项目名称:google-research/bert
- Star数量:34.3K
BERT(Bidirectional Encoder Representations from Transformers)模型是一种基于Transformer架构的双向编码器语言模型,被广泛应用于自然语言处理(NLP)领域。BERT模型通过预训练和微调的方式,实现了对文本的深度理解和表征学习,并在多个NLP任务中取得了卓越的性能。
BERT模型的突出重点能力:
- 双向上下文表示:BERT模型采用双向上下文编码的方式,能够同时利用上下文的信息来理解文本。它通过Masked Language Model(MLM)和Next Sentence Prediction(NSP)任务的预训练,使得模型能够学习到丰富的句子级和词级的上下文表示。
- 上下文敏感的词向量:BERT模型生成的词向量具有上下文敏感性,即同一个词在不同上下文中可以具有不同的表示。这种能力使得BERT模型能够更好地捕捉词义的多样性和语境的变化,提升了文本理解和表征的准确性。
- 预训练和微调:BERT模型采用两阶段的训练方式。首先,通过大规模的无标签数据进行预训练,学习通用的语言表示。然后,在特定任务上使用有标签数据进行微调,将模型应用于具体任务并进行优化。这种训练方式使得BERT模型能够充分利用大量无标签数据和少量有标签数据,实现迁移学习和泛化能力的提升。
BERT模型的应用场景:
- 文本分类和情感分析:BERT模型在文本分类任务中表现出色,能够对文本进行分类和情感分析,如新闻分类、产品评论情感分析等。
- 问答系统:BERT模型在问答任务中具有优秀的性能,能够根据给定的问题和上下文生成准确的回答,如阅读理解、常识问答等。
- 命名实体识别和实体关系抽取:BERT模型能够识别文本中的命名实体,并提取实体之间的关系,如人物关系抽取、医疗实体识别等。
- 机器翻译和文本生成:BERT模型可以应用于机器翻译任务,将一种语言翻译成另一种语言,也可以用于生成自然流畅的文本,如摘要生成、对话系统等。
- 文本匹配和相似度计算:BERT模型能够判断两段文本之间的相似度或匹配程度,如搜索引擎中的查询和文档匹配、句子相似度计算等。
- 文本生成和创作助手:BERT模型具备强大的文本生成能力,可以用于生成文章、故事、诗歌等各种文本形式,为创作者提供灵感和辅助创作。
- 语义理解和句子表征:BERT模型可以将文本句子映射为高质量的语义向量表示,用于计算句子相似度、聚类分析、语义搜索等任务。
- 领域特定任务:BERT模型可以通过在特定领域进行微调,适用于领域特定的任务,如医疗领域的疾病诊断、法律领域的案例分析等。
BERT模型作为一种强大的双向编码器语言模型,具备双向上下文表示、上下文敏感的词向量和预训练微调等突出能力。它在文本分类、问答系统、命名实体识别、机器翻译等多个NLP任务中取得了显著的性能提升,并在广泛的应用场景中发挥重要作用。
OPT
- github项目名称:facebookresearch/metaseq
- Star数量:5.9K
OPT是Open Pre-trained Transformers的缩写,是Meta开源的AI模型,它仅支持英文,暂不支持中文。OPT提供了不同规模的参数模型,其参数规模从125 million到175 billion不等,其中OPT-175B是一个拥有 1750 亿个参数的语言模型,使用了 5 个公开数据集的 800 GB 数据进行训练,其他小规模模型的参数包括 1.25 亿、3.5 亿、13 亿、27 亿、67 亿、130 亿和 300 亿等,可以适用于不同的场景和需求。
OPT模型与GPT系列模型类似,都采用了Transformer-Decoder结构,使用了自回归的方式来生成文本,使用了一些先进的分布式训练技术,如Fully Sharded Data Parallel和Tensor Parallelism,以及一些优化策略,如AdamW和gradient clipping,来提高训练效率和稳定性。
OPT刚发布的时候引起了轰动和广泛关注,因为它1750亿参数比GPT3的3750亿的参数更少,但是它的效果却能够对标GPT3,在多个NLP任务中,如文章生成,代码生成,机器翻译,Q&A等,都取得了与GPT-3可比甚至更好的效果,而只用了GPT-3的1/7的计算资源,Meta AI表示,最低只需要16块英伟达V100 GPU,就能训练并部署OPT-175B模型。
OPT模型不仅开源了代码和权重文件,还开源了训练笔记和数据集,方便其他研究者和开发者复现和使用。
GLM
- github项目名称:THUDM/ChatGLM-6B,THUDM/ChatGLM-130B
- Star数量:25.3K

随着自然语言处理(Natural Language Processing,NLP)领域的快速发展,语言模型的重要性不断凸显。其中,GLM(Giant Language Model)作为一种强大的语言模型,已经在NLP任务中取得了令人瞩目的成果。
GLM模型是基于深度神经网络的语言模型,其主要目标是理解和生成自然语言。GLM采用了Transformer架构,这是一种自注意力机制的模型,能够有效地捕捉输入文本中的上下文关系和语义信息。通过在大规模文本数据上进行预训练,GLM模型能够学习到丰富的语言表示,包括词汇、句法和语义等方面的知识。
GLM模型具有以下几个显著特点:
- 大规模参数:GLM模型通常拥有数十亿到数百亿的参数量级,能够学习到更丰富、更准确的语言表示。
- 上下文理解:通过自注意力机制,GLM模型能够准确捕捉到文本中的上下文关系,提高对句子整体含义的理解能力。
- 多任务学习:GLM模型可以通过联合训练多个NLP任务,共享模型参数,提高模型的泛化能力和效果。
GLM模型可以应用于内容生成、问答系统、分类检索等多个场景,但是推理能力稍微弱一点。
目前清华大学开源的GLM模型比较热门的有GLM-6B和GLM-130B,支持中英文,其中GLM-6B对中文的支持很好,训练和推理需要的资源比较低,开放了API调用,使用门槛较低,在国内的开源社区非常火爆,值得一试。
GLM-130B支持单台A100(40G * 8)或V100(32G * 8)服务器上具有130B参数的推理任务,支持中英双语,支持在NVIDIA、Hygon DCU、Ascend 910、Sunway上的训练和推理。
性能方面,在 7 个零样本 CLUE 数据集(+24.26%)和 5 个零样本 FewCLUE 数据集(+12.75%)上明显优于 ERNIE TITAN 3.0 260B,在 LAMBADA 上优于 GPT-3 175B davinci (+5.0%)、OPT-175B (+6.5%) 和 BLOOM-176B (+13.0%),略优于 GPT-3 175B (+0.9%) 。
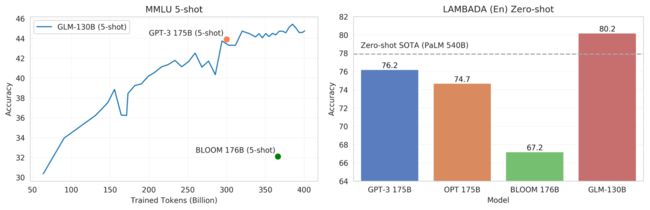
GLM模型的迭代速度很快,社区也很热闹,近期还输出了支持多模态的能力,相信功能会越来越丰富的,能力会越来越强。
以上就是我梳理的10个热门的LLM开源模型,国内采用开源的模型大部分都在这里面了,心动不如行动,有兴趣的童鞋们自己搭建一个试试吧,欢迎交流~