clickhouse,数据查询与写入优化,分布式子查询优化,外部聚合/排序优化,基于JOIN引擎的优化,SQL优化案例,物化视图提速,查询优化常用经验法则,选择和主键不一样的排序键,数据入库优化
1.分布式子查询优化
带子查询的IN和JOIN有两个选项:普通的IN/JOIN、GLOBAL IN / GLOBAL JOIN。
- 普通的IN/JOIN : 查询发送到远程的server,在每个远程的server上运行IN子查询或JOIN子句。
- GLOBAL IN/GLOBAL JOIN : 首先为GLOBAL IN/GLOBAL JOIN运行所有子查询,将结果收集在临时表中。然后将临时表发送到每个远端server,并在其中使用此临时数据运行查询。
1.1)分布式表的IN查询示例1(普通IN子查询、IN子查询为本地表)
SELECT uniq(UserID) FROM distributed_table WHERE UserID IN (SELECT UserID FROM local_table_in WHERE CounterID = 34);上面的查询语句将被发送到所有远程服务器上, 并在远程服务器使用本地表运行:
SELECT uniq(UserID) FROM local_table WHERE UserID IN (SELECT UserID FROM local_table_in WHERE CounterID=34);上面的语句需要保证该local_table_in表的所有USERID完全驻留在单个服务器上,否则,数据可能会不准确。
1.2)分布式表的IN查询示例2(普通IN子查询、IN子查询为分布式表)
SELECT uniq(UserID) FROM distributed_table WHERE UserID IN (SELECT UserID FROM distributed_table_in WHERE CounterID = 34);上面的查询语句将被发送到所有远程服务器上(假设100台服务器),并被远程服务器使用本地表运行:
SELECT uniq(UserID) FROM local_table WHERE UserID IN (SELECT UserID FROM distributed_table_in WHERE CounterID = 34);由于子查询是分布式表,每个子查询分发至100台服务器,运行如下查询:
SELECT UserID FROM local_table_in WHERE CounterID = 34;执行整个查询需要100 * 100 = 10000个请求。这将导致严重性能问题。
考虑使用GLOBAL IN。
1.3)分布式表的IN查询示例3(GLOBAL IN子查询、IN子查询为分布式表)
SELECT uniq(UserID) FROM distributed_table WHERE UserID GLOBAL IN (SELECT UserID FROM distributed_table_in WHERE CounterID = 34);在请求服务器上运行子查询,并将结果存储在RAM的临时表_data1中。
SELECT UserID FROM distributed_table_in WHERE CounterID = 34;请求服务器将临时表_data1发送到每个远程的服务器上,并在每个服务器执行如下查询:
SELECT uniq(UserID) FROM local_table WHERE UserID IN _data1;避免了普通IN导致的连锁响应请求。
1.4)使用GLOBAL IN/GLOBAL JOIN注意事项
- 使用GLOBAL IN创建临时表,数据没有去重。若要减少网络传输的数据量, 在子查询中指定 DISTINCT。
- 使用GLOBAL时,应尽量避免使用大数据集。临时表将发送所有远程的主机,特别是在多机房容灾的集群架构下,数据发送至远程数据中心性能低下。
- GLOBAL可能会导致网络超载。不会限制网络带宽。
- 使用GLOBAL时,尽量保证副本组驻留在同一个数据中心,保证快速的网络数据传输。
- 为避免GLOBAL导致的数据传输,可提前将全量的数据发至每个节点,并使用普通JOIN/IN。
2.外部聚合/排序优化
聚合查询消耗的内存超过max_memory_usage(默认10G)设置的值,导致内存溢出。
ClickHouse支持将临时数据转储到磁盘以限制GROUP BY期间的内存使用。
当GROUP BY消耗超过max_bytes_before_external_group_by设置的阈值,ClickHouse将中间数据转储到磁盘。默认值为0,表示禁用磁盘溢写。
聚合有两个阶段,第一阶段读取数据并形成中间数据。第二阶段合并中间数据。中间临时数据转储到磁盘是发生在第一阶段,如果没有数据转储,则两个阶段使用的内存相同。
在设置max_bytes_before_external_group_by值时,建议将其设置为max_memory_usage的一半。
当使用分布式查询,为了保证外部聚合时在远程的server端执行,设置 distributed_aggregation_memory_efficient为1。
开启外部排序设置max_bytes_before_external_sort,否则可能会内存不足导致查询异常终止。
当启用外部聚合,如果数据没有转储到磁盘,此时,查询的运行速度和没有外部聚合时一样快。 如果中间数据转储到磁盘,则运行时间将延长数倍(大约3倍)。
而外部排序,数据转储到磁盘,性能将明显下降。
三个参数分别设置为20GB、10GB和40GB。1).在命令行界面设置:
set max_bytes_before_external_group_by=20000000000; set max_bytes_before_external_sort=10000000000; set max_memory_usage=40000000000;2)JDBC设置,在URL添加参数:
url?max_bytes_before_external_group_by=20000000000&max_memory_usage=40000000000

3.基于JOIN引擎的优化
如果多次使用相同的表(子查询),每次都需要重新计算运行子查询。为此,可使用Join表引擎将数据缓存在 RAM中。
语法:ENGINE=Join(join_strictness,join_type,k1[,k2,...]) 参数: join_strictness,取值ALL,ANY和ASOF join_type : JOIN的类型,LEFT、RIGHT、INNER等。 k1[,k2,...] : 关联的字段JOIN引擎使用示例:
创建表:DROP TABLE id_val; CREATE TABLE id_val(`id` UInt32, `val` UInt32) ENGINE = TinyLog;插入表数据:
INSERT INTO id_val VALUES (1,11)(2,12)(3,13);创建右连接的JOIN引擎表:
DROP TABLE id_val_join; CREATE TABLE id_val_join(`id` UInt32, `val` UInt8) ENGINE = Join(ANY, LEFT, id);插入数据:
INSERT INTO id_val_join VALUES (1,21)(1,22)(3,23);表数据关联:
SELECT * FROM id_val ANY LEFT JOIN id_val_join USING (id) SETTINGS join_use_nulls = 1;
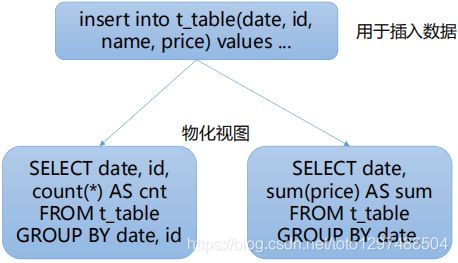
4.物化视图提速
在用于插入数据的表上,创建多个物化视图,每个物化视图根据业务需求对数据做转换。
1.物化视图存储通过由相应的SELECT查询转换的数据。
2.在数据插入期间做查询转换,压力分散。
3.仅在插入的单个数据块中聚合,数据不会进一步聚合。
4.数据表的引擎可为NULL。
5.查询优化常用经验法则
1.小表放在JOIN的右边
2.使用子查询显示设置数据处理的顺序
3.使用IN替换JOIN操作
4.使用字典替换JOIN操作。
5.设置单射属性。
6.使用Join引擎缓存表。
7.禁用分布式表的子查询,使用GLOBAL IN/JOIN替换或者将子查询的表提前分发至所有的server作为本地表。
8.使用PREWHERE
9.避免使用SELECT *查询
10.尽量少用或不用多表关联。
6.选择和主键不一样的排序键
默认情况下,主键(由PRIMARY KEY指定)跟排序键(ORDER BY)相同,因此,大部分情况下,不需要专门指定一个PRIMARY KEY子句。
当使用SummingMergeTree 和 AggregatingMergeTree时,可考虑选择和主键不一样的排序键。
CREATE TABLE t_merge_sum ( id UInt32, name String, value UInt32 )ENGINE = SummingMergeTree() PRIMARY KEY id ORDER BY (id,name);1.排序键可以修改,主键不能修改。
2.预聚合/增量聚合的key是由排序键指定的。业务逻辑后期可能会更改。
3.查询条件无需包括排序键的所有字段。添加排序键需要注意的:
1.主键字段是排序键字段的子集。
例如主键为(A,B),则排序键以(A,B)开头,排序键可为(A,B)或(A,B,C)等。2.旧的排序键是新的排序键的前缀。
修改排序键只能增加排序字段,不能减少排序键字段,例如可修改排序键(A,B)为(A,B,C),但不能修改为(A,C)或(A,C,B)等。3.排序键只能添加新加入表的列,表中已存在的数据的列不能添加到排序键中。
7.数据入库优化
1.使用复制表,能够保证数据原子写入和去重。
2.限制单个复制表INSERT语句执行的频率(建议每秒不超过1个)
3.以相当大的数据块插入数据(默认为1048576)。
4.将数据INSERT到ClickHouse之前,通过分区键对数据进行分组。
5.增加入库的并发,入库性能线性提升。
6.自定义负载均衡策略,控制数据均衡。
