R语言:permutation test 置换检验
1. 生成男女生身高数据各20个
男身高,mean=180, sd=10
女身高,mean=178, sd=10
set.seed(20211009)
boy=rnorm(20, 180, 10)
girl=rnorm(20, 178, 10)
stu=c(boy, girl)
# 计算初始均值差
diff1=mean(boy) - mean(girl)
diff1 #3.033677直接做t-test,p=0.257,差异不显著。
# direct t-test
t.test(boy, girl) #p-value = 0.2578
#增加样本量,则显著性增加。
# 随着样本量的增加,微小恒定的差异会变得显著(男女身高)。
# 但是不显著的差异,增加样本量也不会显著(男女体重?)。
t.test(rep(boy, 2), rep(girl,2) ) #p-value = 0.1038
t.test(rep(boy, 3), rep(girl,3) ) #p-value = 0.04514
t.test(rep(boy, 3), rep(girl,3) ) #p-value = 0.02037
t.test(rep(boy, 5), rep(girl,5) ) #p-value = 0.009394
t.test(rep(boy, 10), rep(girl,10) ) #p-value = 0.0002287todo: 样本量该准备多少?关键词:统计效力 power, 样本量估计
2. permutation test
随机打乱40个样本,前20个作为男生,后20个作为女生,计算均值差x。
重复n次,做出均值差x 的分布。
p值 = 绝对值超出 初始均值差diff1 的x的个数 / 实验重复次数n。
# permutation test
doTest=function(len=100, seed=20211009){
# sampling
set.seed(seed)
diffMeans=c()
for(i in 1:len){
groupA=sample( seq(1,40), 20)
groupB=setdiff( seq(1,40), groupA)
#
meanA=mean( stu[groupA] )
meanB=mean( stu[groupB] )
diffMeans = c(diffMeans, meanA - meanB)
}
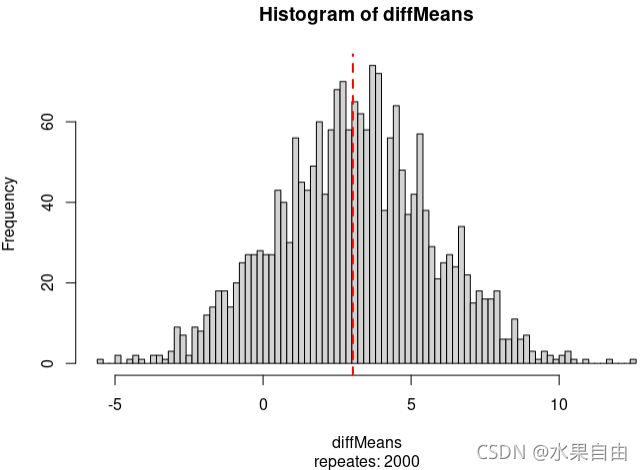
# plot
hist(diffMeans, n=100, sub=paste("repeates:", len) )
abline(v=diff1, lty=2, col="red", lwd=2)
# method1, p = bigger / n
p1= 2* as.numeric( table(diffMeans > diff1)[2] ) / len; #p1
return( c(len, p1))
}
doTest(100) #0.28
doTest(1000) #0.252
doTest(10000) #0.2544
doTest(20000) #0.2604
doTest(40000) #0.2579
doTest(100000) #0.25928
# p value almost doesn't change as repeate number increases.这个p=0.25值和直接t-test的p值很接近,而且随着重复次数n的增加,p几乎不变。

3. 组内重抽样?
从男生、女生中各抽取一半样本,不放回抽样,计算分别计算男女生平均身高x1, x2,然后计算其差异是否显著。
# method: sampling within group
doTest2=function(len=100, seed=20211009){
# sampling
set.seed(seed)
diffMeans=c()
for(i in 1:len){
groupA=sample( seq(1,20), 10)
groupB=sample( seq(1,20), 10)
#
meanA=mean( boy[groupA] )
meanB=mean( girl[groupB] )
diffMeans = c(diffMeans, meanA - meanB)
}
# plot
hist(diffMeans, n=100, sub=paste("repeates:", len) )
abline(v=diff1, lty=2, col="red", lwd=2)
# method2, H0: diffMeands=0
p2= t.test(diffMeans)$p.value
return( c(len, p2))
}
doTest2(100) #5.998058e-22
doTest2(100,seed=20211008) #9.385248e-19
doTest2(200) #4.097417e-39
doTest2(500) #2.603963e-104
doTest2(1000) #1.907446e-199
doTest2(2000) #0
# p value decrease dramatically as repeate number increases.组内重抽样,计算每组内男女生平均身高的差,重复n次,t检验该差是否不等于0。
结果p值随着重复次数n的增加而显著降低。这一点不符合预期,p值不稳定。
小样本量中的计算统计量,应该怎么计算其p值呢?
比如比较2个样本的均值是否有显著差异?先计算均值,然后就2个样本。。。
还有其他复杂统计量的比较。