自动化测试中的数据驱动
DDT
当测试框架是unittest时,可以使用ddt。ddt 这个类装饰器必须装饰在 TestCase 的子类上,TestCase 是 unittest 框架中的一个基类,它实现了 Test Runner 驱动测试运行所需的接口(interface)。
DDT 的使用步骤如下:
-
使用 @ddt 装饰你的测试类;
-
使用 @data 或者 @file_data 装饰你需要数据驱动的测试方法;
-
如一组测试数据有多个参数,则需 unpack,使用 @unpack 装饰你的测试方法。
安装:pip install ddt
ddt.data() 可接受的数据格式:
一组数据,每个数据为单个的值;多组数据,每组数据为一个列表或者一个字典
ddt 直接提供数据
单个参数
@ddt
class TestDdt(unittest.TestCase):
@data("Tom","Jack")
def test_a(self,a):
print("这次的测试数据是"+a)
if __name__ == '__main__':
unittest.main()
多个参数
-
# data表示data是直接提供的。
-
# unpack表示,对于每一组数据,如果它的值是list或者tuple,那么就分拆成独立的参数。
@ddt
class TestDdt(unittest.TestCase):
@data(["Tom1","Tom2"],["Jack1","Jack2"])
@unpack
def test_a(self,a,b):
print("这次的测试数据是"+a+b)
if __name__ == '__main__':
unittest.main() 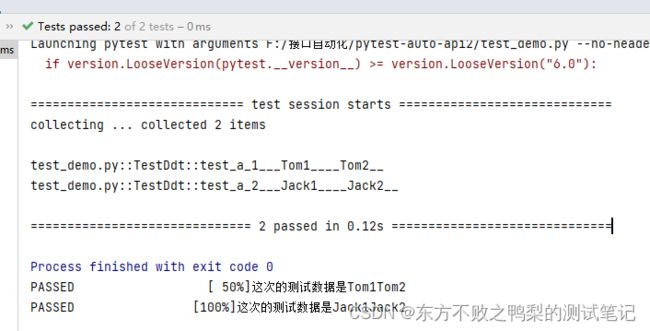
使用函数提供数据
import unittest
from ddt import ddt, data, unpack
def get_test_data():
data=(["Tom1","Tom2"],["Jack1","Jack2"])
return data
@ddt
class TestDdt(unittest.TestCase):
@data(*get_test_data())
@unpack
def test_a(self,a,b):
print("这次的测试数据是"+a+b)
if __name__ == '__main__':
unittest.main()
使用文件提供数据
可以使用json或者yaml文件提供测试数据
新建test_a.json
{
"case1": {
"a": "Tom",
"b":"Jack"
},
"case2": {
"a": "Tom2",
"b":"Jack2"
}
}import unittest
from ddt import ddt, data, unpack, file_data
@ddt
class TestDdt(unittest.TestCase):
@file_data('test_a.json')
def test_a(self,a,b):
print("这次的测试数据是"+a+b)
if __name__ == '__main__':
unittest.main()注意这里测试函数要用@file_data装饰。使用外部文件方式Load数据无须使用unpack
使用yaml文件
pip install pyyaml
新建test_a.yml
"case1":
"a": "Tom1"
"b": "Jack1"
"case2":
"a": "Tom2"
"b": "Jack2"
test_demo.py
import unittest
from ddt import ddt, data, unpack, file_data
@ddt
class TestDdt(unittest.TestCase):
@file_data('test_a.yml')
def test_a(self,a,b):
print("这次的测试数据是"+a+b)
if __name__ == '__main__':
unittest.main() 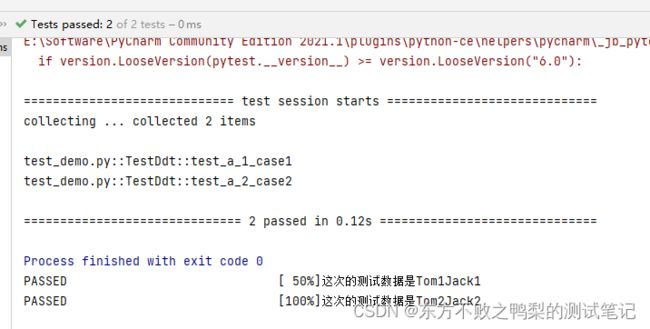
其他格式文件
ddt 默认只支持 JSON 和 YAML 格式的数据。但是我想使用其他数据格式怎么办?
常用的方式有如下两种:
-
先读取其他格式的文件(例如 Excel 格式),然后创建 ddt 支持的 JSON 或者 YAML 文件,最后把获取到的数据写入这个文件,再使用 @file_data() 即可;
-
创建一个函数,在函数中读取其他格式的文件并获取数据,将数据直接返回为 @ddt.data() 支持的格式调用即可。
Parametrize
如果使用的是pytest,则可以采用这种方法进行数据驱动。
pytest 可以通过 pytest.mark.parametrize 来实现数据驱动,而 pytest.mark.parametrize 接受的数据格式要求为:
-
如果只有一组数据,以列表的形式存在;注意需要传入参数。
import pytest
@pytest.mark.parametrize('a',["Tom","Jack"])
def test_a(a):
print("这次的测试数据是"+a)
输出:
PASSED [ 50%]这次的测试数据是Tom
PASSED [100%]这次的测试数据是Jack-
如果有多组数据,以列表嵌套元组的形式存在(例如 [0,1] 或者 [(0,1), (1,2)])(备注,实际列表嵌套列表也可以)
import pytest
@pytest.mark.parametrize('a,b',[("Tom","Jack"),("Tom1","Jack1")])
def test_a(a,b):
print("这次的测试数据是"+a+b)
输出PASSED [ 50%]这次的测试数据是TomJack
PASSED [100%]这次的测试数据是Tom1Jack1使用yaml/json文件提供数据
可以使用json/yaml文件提供数据,但需要写一个解析对应数据的方法。
因为json和yaml读取后的数据都是字典嵌套字典,所以写一个方法判断文件类型采用不同模块load,处理逻辑是一样的。
import json
import os.path
import pytest
import yaml
def yaml_data(filename):
file_path=os.path.abspath(filename)
print(file_path)
with open(filename,"r") as f:
if file_path.endswith((".yml", ".yaml")):
data=yaml.load(f,Loader=yaml.FullLoader)
elif file_path.endswith(("json")):
data=json.load(f)
else:
print("文件类型错误,仅支持yaml和json")
raise
result=[]
for key,value in data.items():
case_data = []
for k,v in value.items():
case_data.append(v)
result.append(tuple(case_data))
return result
@pytest.mark.parametrize('a,b',yaml_data(r'F:\接口自动化\pytest-auto-api2\test_a.json'))
def test_a(a,b):
print("这次的测试数据是"+a+b)
使用Excel文件提供数据
定义方法实现从excel读取数据,这里实现两个方法都可以使用。
import openpyxl
def read_excel_data(filename,sheetname):
if not os.path.exists(filename):
raise ValueError("File not exists")
workbook = openpyxl.load_workbook(filename)
worksheet = workbook.get_sheet_by_name(sheetname)
datas = list(worksheet.iter_rows(values_only=True)) # 获取Excel表中的所有数据,每一行组成元组,整个数据组成列表
case_datas = datas[1:] # 获取表数据
cases_list = []
for case in case_datas:
cases_list.append(case)
return cases_list
def read_excel_data2(filename, sheetname):
workbook = openpyxl.load_workbook(filename)
cases_list = []
worksheet = workbook.get_sheet_by_name(sheetname)
for row in worksheet.rows:
cases_list.append([col.value for col in row])
return cases_list[1:]
@pytest.mark.parametrize('a,b',read_excel_data(r'C:\Users\Administrator\Desktop\test1.xlsx','Sheet1'))
def test_a(a,b):
print("这次的测试数据是"+a+b)pandas
import pandas as pd
def read_excel_data3(filename,sheetname):
s = pd.ExcelFile(filename)
data =s.parse(sheet_name =sheetname)
return data.values.tolist()