Java自带的一个很不错的框架——Fork/Join
1、基本概念
Fork/Join框架是Java 7提供的一个用于并行执行任务的框架, 核心思想就是把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果。
如果对算法有所了解的话,很清楚就能看出来Fork/join框架与分治算法很相似。比如计算1+2+…+10000,可以分割成10个子任务,每个子任务分别对1000个数进行求和,最终汇总这10个子任务的结果。
执行流程如下:
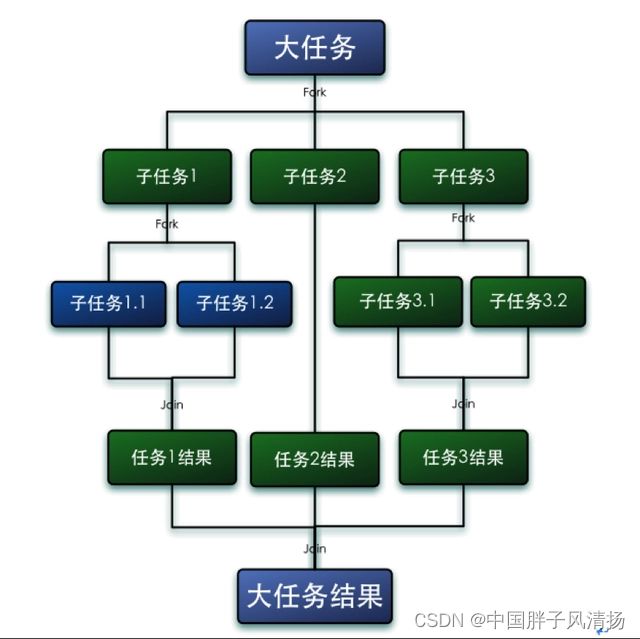
2、核心算法——工作窃取
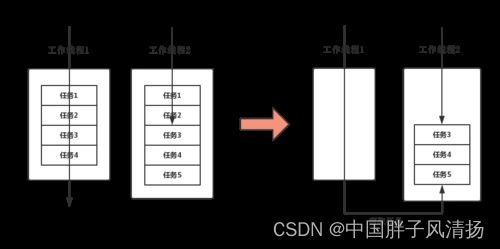
- 假如我们需要做一个比较大的任务,我们可以把这个任务分割为若干互不依赖的子任务。
- 为了减少线程间的竞争,于是把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务。
- 有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。
而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。
分不清双向队列对头、队尾可以参考下图:

3、相关类
当我们想将指定的任务提交到Fork/join框架中进行执行的时候,就需要任务所在类继承ForkJoinTask抽象类来表示一个ForkJoin任务,但是目前我们并不需要继承ForkJoinTask抽象类,JDK给我们提供了他的两个子类:
| 类名 | 描述 |
|---|---|
| RecursiveAction | 重写compute抽象方法,没有返回结果。 |
| RecursiveTask | 重写compute抽象方法,有返回结果。 |
3.1、RecursiveAction源码
public abstract class RecursiveAction extends ForkJoinTask<Void> {
private static final long serialVersionUID = 5232453952276485070L;
protected abstract void compute();
public final Void getRawResult() { return null; }
protected final void setRawResult(Void mustBeNull) { }
protected final boolean exec() {
compute();
return true;
}
}
3.2、RecursiveTask源码
public abstract class RecursiveTask<V> extends ForkJoinTask<V> {
private static final long serialVersionUID = 5232453952276485270L;
protected abstract V compute();
public final V getRawResult() {
return result;
}
protected final void setRawResult(V value) {
result = value;
}
protected final boolean exec() {
result = compute();
return true;
}
}
3.3、ForkJoinPool
Fork/Join的任务需要通过ForkJoinPool来进行执行。
ForkJoinPool由ForkJoinTask数组和ForkJoinWorkerThread数组组成,ForkJoinTask数组负责存放程序提交给ForkJoinPool的任务,而ForkJoinWorkerThread数组负责开创相应数量的线程执行这些任务。
3.3.1、ForkJoinPool的构造方法
无参构造
public ForkJoinPool() {
this(Math.min(MAX_CAP, Runtime.getRuntime().availableProcessors()),
defaultForkJoinWorkerThreadFactory, null, false,
0, MAX_CAP, 1, null, DEFAULT_KEEPALIVE, TimeUnit.MILLISECONDS);
}
有一个参数的构造方法
public ForkJoinPool(int parallelism) {
this(parallelism, defaultForkJoinWorkerThreadFactory, null, false,
0, MAX_CAP, 1, null, DEFAULT_KEEPALIVE, TimeUnit.MILLISECONDS);
}
全参构造
public ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler,
boolean asyncMode,
int corePoolSize,
int maximumPoolSize,
int minimumRunnable,
Predicate<? super ForkJoinPool> saturate,
long keepAliveTime,
TimeUnit unit) {
if (parallelism <= 0 || parallelism > MAX_CAP ||
maximumPoolSize < parallelism || keepAliveTime <= 0L)
throw new IllegalArgumentException();
// 此处已省略复杂代码
int n = (parallelism > 1) ? parallelism - 1 : 1; // at least 2 slots
n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16;
n = (n + 1) << 1; // power of two, including space for submission queues
this.workQueues = new WorkQueue[n];
// 省略复杂代码
}
- 无论是哪一种构造方法,调用的都是全参构造,我们可以通过全参构造不难看出,
parallelism参数直接影响着this.workQueues工作线程的大小。 - 当我们使用无参构造的时候,会用当前系统的可用线程数与MAX_CAP进行比较,取最小的一个。
Math.min(MAX_CAP, Runtime.getRuntime().availableProcessors())
static final int MAX_CAP = 0x7fff; // 32767
- 当我们使用一个参数的构造方法时,
parallelism参数假设为2,那么池的并行度级别为 2。这意味着池将使用 2 个处理器内核,但是不能超过MAX_CAP,从全参构造可以看出,超过MAX_CAP后就会报错。
3.3.2、WorkQueue数组何时扩容?
当新的任务到来,线程池会通知其他线程前去处理,如果这时没有处于等待的线程或者处于活动的线程非常少,就会往线程池中添加线程。
/**
在增长ctl数量之前尝试添加一个工作线程,依靠creatWorker方法进行创建并退出。
**/
private void tryAddWorker(long c) {
do {
long nc = ((RC_MASK & (c + RC_UNIT)) | (TC_MASK & (c + TC_UNIT)));
if (ctl == c && CTL.compareAndSet(this, c, nc)) {
createWorker();
break;
}
} while (((c = ctl) & ADD_WORKER) != 0L && (int)c == 0);
}
/**
利用ForkJoinWorkerThreadFactory创建工作线程。
1、如果成功创建并返回true。
2、如果ForkJoinWorkerThreadFactory为NULL并且创建的线程为NULL,
则调用deregisterWorker方法取消工作线程的注册,最后返回false。
**/
private boolean createWorker() {
ForkJoinWorkerThreadFactory fac = factory;
Throwable ex = null;
ForkJoinWorkerThread wt = null;
try {
if (fac != null && (wt = fac.newThread(this)) != null) {
wt.start();
return true;
}
} catch (Throwable rex) {
ex = rex;
}
deregisterWorker(wt, ex);
return false;
}
3.3.3、执行ForkJoinTask的方式
| 执行方式 | 描述 |
|---|---|
| void execute(ForkJoinTask task) | 异步执行tasks,无返回值 |
| 异步执行,且带Task返回值,可通过task.get 实现同步到主线程 | |
| tasks会被同步到主线程,主线程和ForkJoin线程是异步执行,而invoke启动时,主线程同步等待ForkJoin线程执行。 |
我们在使用forkJoin的时候一定要注意pool的启动方式,不然就会有隐藏的坑。
4、总结
- ForkJoin是一种专为CPU密集型任务而生的线程池(比如计算1~100亿的和),它能充分利用CPU资源,把大任务拆分成众多小的子任务,多线程并行。
- ForkJoinPool 使用submit 或 invoke 提交的区别:invoke是同步执行,调用之后需要等待任务完成,才能执行后面的代码;submit是异步执行,只有在Future调用get的时候会阻塞。
- Fork/Join框架不适合IO密集型,因为磁盘IO、网络IO的操作特点就是等待,容易造成线程阻塞。
- 执行子任务调用fork方法并不是最佳的选择,最佳的选择是ForkJoinPool中的invokeAll方法。