Golang 爬取力扣的题库
一、力扣网站分析(这里使用的是 Edge 浏览器)
题目信息页分析
进入官网题库:
题库 - 力扣 (LeetCode) 全球极客挚爱的技术成长平台 https://leetcode.cn/problemset/all/
https://leetcode.cn/problemset/all/
这里以中等难度为例(难度选择中等),且普通不需要付费的题目并不需要登录:
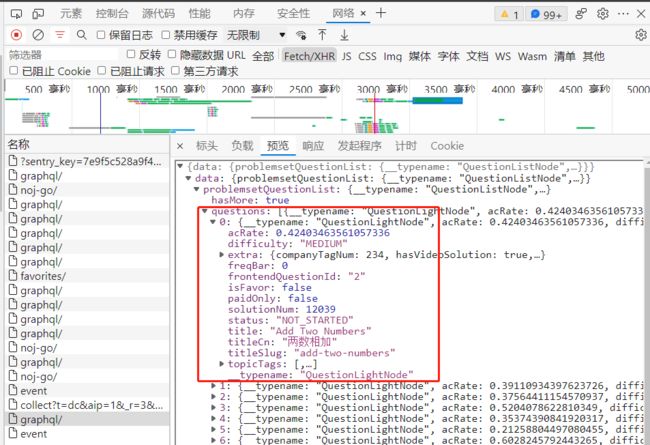
F12 打开开发者模式,选择网络 > Fetch/XHR,如果没有数据按F5刷新一下,找到请求到数据的请求地址,分析发现这里有我们需要获取的题目信息,难度(difficulty),题目(titleCn)、通过率(acRate)、是否付费(paidOnly)、titleSlug(后续用到):
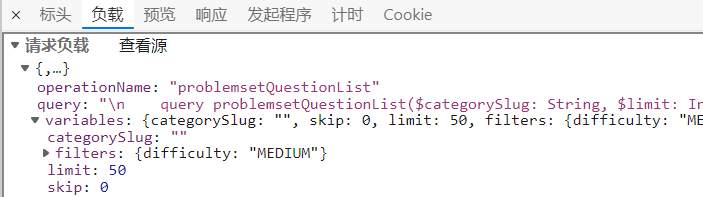
请求地址(https://leetcode.cn/graphql/)和请求头(request header 主要是 Cookie)在标头可以看到,这里主要看看请求负载,这个是我们发送请求的请求体也就是请求参数(非常重要):
PS:
顺便说一下,你直接访问力扣官网 url 爬取到的网页里是无法获取题目信息和详情页链接的,因为力扣使用的是 graphql 直接请求数据。
GraphQL 是一种用于 API 的查询语言,是由 Facebook 开源的一种用于提供数据查询服务的抽象框架。在服务端 API 开发中,很多时候定义一个接口返回的数据相对固定,因此要获得更多信息或者只想得到某部分信息时,基于 RESTful API 的接口就显得不那么灵活。而 GraphQL 对 API 中的数据提供了一套易于理解的完整描述,使得客户端能够准确地获得它需要的数据,而且没有任何冗余,也让 API 更容易地随着时间推移而演进,还能用于构建强大的开发者工具。
这里没深入探讨 GraphQl ,有兴趣可参考 https://docs.github.com/en/graphql 。
题目详情页内容分析
随便找一个题目点进去进入详情页:

同样的 F12,找到发送请求数据的请求,可以看到内容 (translatedContent) 即为我们需要的题目详情内容:
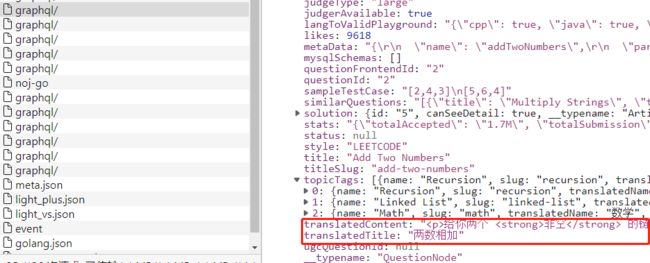
细心的就会发现,请求题目详情页的 url 其实就是 https://leetcode.cn/problems/ + titleSlug,titleSlug 是上方信息页的请求到的数据(这里主要爬取题库,题解的爬取其实也是差不多)。
二、代码实施(代码上都有注释,所以不过多讲解)
请求参数获取和测试
请求参数获取:
这里使用的是 postman 进行测试,并且修改请求参数,因为实际请求时,我们并不需要获取所有数据,postman 操作 import --> Raw text --> ctrl+c --> Continue -- >选择 POST 请求 --> Send,请求成功后会出现和网页上请求的数据(详情页的请求参数获取和测试也一样):

简化请求参数(这里用 postman 测试,就是怕删错了),应该还可以更简单,这里懒得折腾了,将就着用:
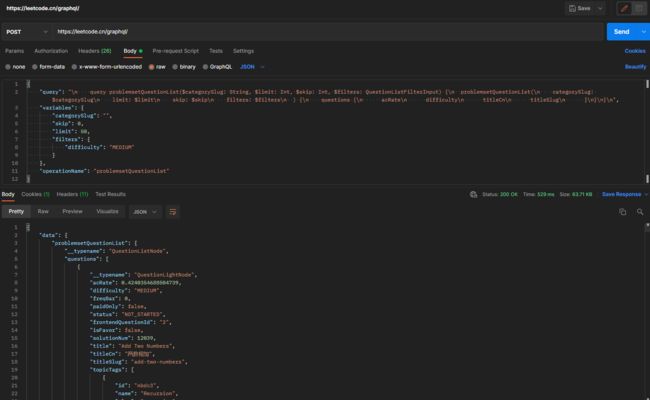 题目信息数据请求
题目信息数据请求
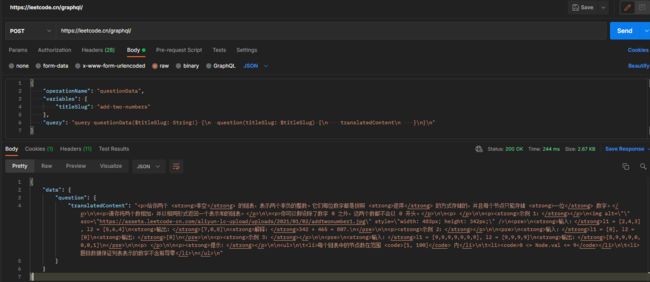 题目详细内容请求
题目详细内容请求
代码编写
package main
import (
"encoding/json"
"fmt"
"io/ioutil"
"log"
"net/http"
"net/url"
"os"
"strings"
"time"
simplejson "github.com/bitly/go-simplejson"
_ "github.com/go-sql-driver/mysql"
"github.com/jinzhu/gorm"
)
// 连接数据库
var (
DB *gorm.DB
err error
)
// 模型
type QuestionBank struct {
Id int
TitleCn string
AcRate string
Difficulty string
Content string
Link string
}
func (QuestionBank) TableName() string {
return "question_bank"
}
func init() {
// 这里的 x 为你连接数据库的配置
DB, err = gorm.Open("mysql", "xxxx:xxxxxxxxxxx@tcp(xxxx)/leetcode?charset=utf8mb4&parseTime=True&loc=Local&timeout=180s")
if err != nil {
log.Println("Failed to open database connection: ", err)
return
} else {
log.Println("Database connection established!")
}
// 设置连接成功后配置
DB.DB().SetMaxIdleConns(30) // 空闲时连接数
DB.DB().SetMaxOpenConns(0) // 连接数据库连接数
DB.DB().SetConnMaxIdleTime(time.Second * 300) // 连接池内链接最大空闲时长
DB.SingularTable(true) // 设置模型创建时单数表名
DB.LogMode(true) // 开启数据库日志模式,打印详细日志
DB.SetLogger(log.New(os.Stdout, "\r\n", log.LstdFlags)) // 输出到终端并加上日期时间且每条log都会执行 \r\n
}
// 抓取力扣题目信息数据
func Crawl_LC(num int, exit chan int) {
// 请求数据的 url
li_url := "https://leetcode.cn/graphql/"
// 解析 url
parse_Url, err := url.Parse(li_url)
if err != nil {
fmt.Println("url解析失败!", err)
return
}
// 将访问 url 重构成合法 url 字符串
Url := parse_Url.String()
// 创建客户端
client := &http.Client{}
/*
上方获取到的请求参数,分析这个请求参数可以发现:
limit 是控制每页显示的题目数
skip 则是跳过上一页显示的数量,通过改变 skip 可以控制获取下一页的题目
difficulty 修改后可以分别爬取 EASY MEDIUM HARD 难度的题目
*/
reqBody := strings.NewReader(fmt.Sprintf("{\"query\": \"\\n query problemsetQuestionList($categorySlug: String, $limit: Int, $skip: Int, $filters: QuestionListFilterInput) {\\n problemsetQuestionList(\\n categorySlug: $categorySlug\\n limit: $limit\\n skip: $skip\\n filters: $filters\\n ) {\\n questions {\\n acRate\\n difficulty\\n titleCn\\n titleSlug\\n }\\n}\\n}\\n\",\"variables\": {\"categorySlug\": \"\",\"skip\": %d,\"limit\": 50,\"filters\": {\"difficulty\": \"MEDIUM\"}},\"operationName\": \"problemsetQuestionList\"}", num))
// 解析请求,分析请求头发现时 POST 请求
req, err := http.NewRequest("POST", Url, reqBody)
if err != nil {
fmt.Println("请求解析失败!", err)
return
}
// 请求头设置,这里对着请求头照抄就是了,x 为你浏览器访问的请求头配置
req.Header.Set("Accept", "*/*")
req.Header.Set("Cache-Control", "max-age=0")
req.Header.Set("Connection", "keep-alive")
req.Header.Set("Cookie", "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx") // Cookie 必须
req.Header.Set("Origin", "https://leetcode.cn")
req.Header.Set("Sec-Fetch-Dest", "empty")
req.Header.Set("Sec-Fetch-Mode", "cors")
req.Header.Set("Sec-Fetch-Site", "same-origin")
req.Header.Set("User-Agent", "xxxxxxxxxxxxxxxxxxxxxxxxxxx") // 用户代理 必须
req.Header.Set("content-type", "application/json")
req.Header.Set("random-uuid", "xxxxxxxxxxxxxxxxxxxxxxxxxxx")
req.Header.Set("sec-ch-ua-mobile", "?0")
req.Header.Set("sec-ch-ua-platform", "Windows")
req.Header.Set("x-csrftoken", "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx")
// 发送请求
resp, err := client.Do(req)
if err != nil {
fmt.Println("请求失败!", err)
}
// 关闭链接
defer resp.Body.Close()
// 读取访问获取的页面
content, err := ioutil.ReadAll(resp.Body)
if err != nil {
fmt.Println("页面读取失败!", err)
return
}
// 解析 json 数据,用到了 simplejson 库
unContent, err := simplejson.NewJson(content)
if err != nil {
fmt.Println("json 解析失败!", err)
return
}
// 获取指定数据
questions_Array, err := unContent.Get("data").Get("problemsetQuestionList").Get("questions").Array()
if err != nil {
fmt.Println("获取数据失败!", err)
return
}
// 遍历进一步筛选数据
var questionBank QuestionBank
for _, value := range questions_Array {
if v, ok := value.(map[string]interface{}); ok {
// 判断是否是要付费
if v["paidOnly"] == false {
questionBank = QuestionBank{
TitleCn: v["titleCn"].(string),
AcRate: string(v["acRate"].(json.Number)),
Difficulty: v["difficulty"].(string),
Content: Crawl_D(v["titleSlug"].(string)),
Link: "https://leetcode.cn/problems/" +
v["titleSlug"].(string),
}
DB.Create(&questionBank)
}
}
}
// 完成后发送
exit <- 1
}
// 爬取详情页
func Crawl_D(titleSlug string) string {
// 请求数据的 url
detail_url := "https://leetcode.cn/graphql/"
// 解析 url
parse_Url, err := url.Parse(detail_url)
if err != nil {
fmt.Println("url解析失败!", err)
return ""
}
// 转成合法 url
Url := parse_Url.String()
// 创建客户端
client := &http.Client{}
// 请求体,通过替换 titleSlug 访问不同题目
reqBody := strings.NewReader(fmt.Sprintf("{\"operationName\": \"questionData\",\"variables\": {\"titleSlug\": \"%s\"},\"query\": \"query questionData($titleSlug: String!) {\\n question(titleSlug: $titleSlug) {\\n translatedContent\\n }\\n}\\n\"}", titleSlug))
// 解析请求
req, err := http.NewRequest("POST", Url, reqBody)
if err != nil {
fmt.Println("请求解析失败!", err)
return ""
}
// 请求头设置,x 同样为你浏览器访问的请求头配置
req.Header.Set("Accept", "*/*")
req.Header.Set("Connection", "keep-alive")
req.Header.Set("content-type", "application/json")
req.Header.Set("Cookie", "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx")
req.Header.Set("Referer", fmt.Sprintf("ttps://leetcode.cn/problems/%s/", titleSlug))
req.Header.Set("User-Agent", "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx")
req.Header.Set("X-CSRFToken", "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx")
// 发送请求
resp, err := client.Do(req)
if err != nil {
fmt.Println("请求失败!", err)
}
// 关闭链接
defer resp.Body.Close()
// 读取访问获取的页面
content, err := ioutil.ReadAll(resp.Body)
if err != nil {
fmt.Println("页面读取失败!", err)
return ""
}
// 解析 json 数据
unContent, err := simplejson.NewJson(content)
if err != nil {
fmt.Println("json 解析失败!", err)
return ""
}
// 获取指定数据
questions_detail, err := unContent.Get("data").Get("question").Get("translatedContent").String()
if err != nil {
fmt.Println("获取数据失败!", err)
return ""
}
return questions_detail
}
// 爬取力扣题库,题目的查看不需要登录
func main() {
fmt.Println("题目爬取中...")
// 接收和发送退出信号
exit := make(chan int, 10)
mainExit := make(chan int, 10)
// 这里主要根据题库的页码和每页多少来爬取,分析发现每页 50 题,所以每爬完一次要把爬过的删除
for i := 0; i <= 1650; i += 50 {
go Crawl_LC(i, exit)
if i == 1650 {
mainExit <- <-exit
} else {
<-exit
}
}
flag := <-mainExit
if flag == 1 {
fmt.Println("爬取结束!")
return
}
}
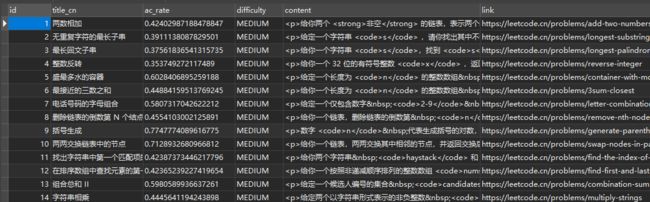
最终效果
三、结语
目前代码只是写了个大概流程并没有简化或优化,其中分析也可能有不足的地方,欢迎各位在评论和私信里提出您宝贵的意见或其他有趣的想法。