【机器学习】可视化模块-seaborn详细教程
文章目录
- 一、Seaborn介绍
- 二、使用前骤
-
- 1.安装
- 2.导包
- 三、使用
-
- 1.统计关系
- 2.分类关系
- 3.数据集的分布
- 4.线性关系
- 5. 结构化构图
- 6.风格设置
- 总结
一、Seaborn介绍
Seaborn是一个基于Python语言的数据可视化库,它能够创建高度吸引人的可视化图表,是在matplotlib库的基础上,提供了更为简便的API和更为丰富的可视化函数,使得数据分析与可视化变得更加容易。Seaborn的设计哲学是以美学为中心,致力于创建最佳的数据可视化,同时也保持着与Python生态系统的高度兼容性,可以轻松集成到Python数据分析以及机器学习的工作流程中.
特点:
- 丰富的可视化函数:Seaborn拥有一系列丰富的可视化函数,能够创建多种类型的图表,包括折线图、柱状图、散点图、核密度图、热力图等等。
- 简洁的API:Seaborn的API设计简洁,代码易读易写,让用户能够轻松地创建高质量的可视化图表。
- 支持数据分组:Seaborn支持按照数据分组进行可视化,使得用户能够更好地分析数据的差异。
- 自动化调整:Seaborn能够自动调整图表的各种参数,包括颜色、标签、坐标轴等等,使得用户能够更专注于数据分析。
- 计算多变量间关系的面向数据集接口
- 可视化类别变量的观测与统计
- 可视化单变量或多变量分布并与其子数据集比较
- 控制线性回归的不同因变量并进行参数估计与作图
- 对复杂数据进行易行的整体结构可视化
- 对多表统计图的制作高度抽象并简化可视化过程
- 提供多个内建主题渲染 matplotlib 的图像样式
- 提供调色板工具生动再现数据
二、使用前骤
1.安装
pip install seaborn
由于需要其他模块依赖,还需要安装
pip install numpy
pip install scipy
pip install pandas
2.导包
import numpy as np
import pandas as pd
from scipy import stats
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style="darkgrid")
三、使用
1.统计关系
- 散点图
data=sns.load_dataset('tips')
sns.relplot(x='total_bill',y='tip',data=data)
plt.show()

添加参数
hue ->颜色 style->风格 size->尺寸
sns.relplot(x='total_bill',y='tip',hue="smoker",style='darkgrid',size=10,data=data)

- 折线图
data=np.random.rand(100)
sns.relplot(kind='line',data=data)
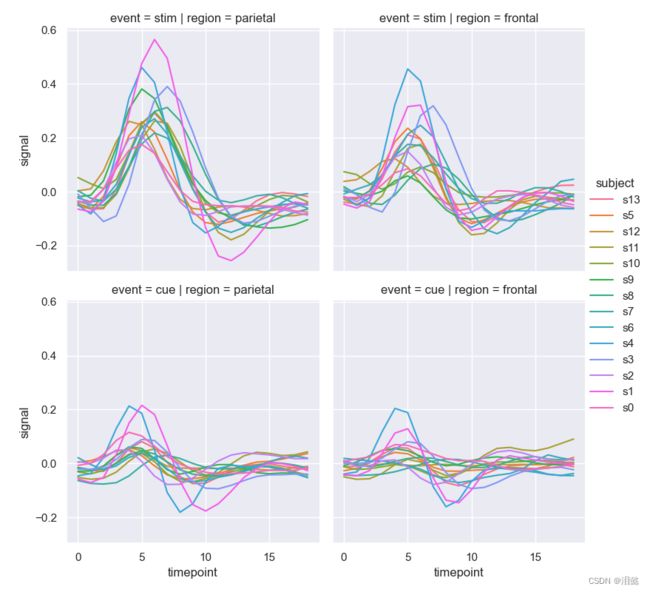
- 显示与切面的多种关系
fmri=sns.load_dataset('fmri')
sns.relplot(x="timepoint", y="signal", hue="subject",
col="region", row="event", height=4,
kind="line", estimator=None, data=fmri)
2.分类关系
- 热力图
unniform_data=np.random.rand(8,8)
#vim,vmax表示范围 ,center表示中心数据大小
heatmap=sns.heatmap(unniform_data,vmin=0,vmax=1,center=0)
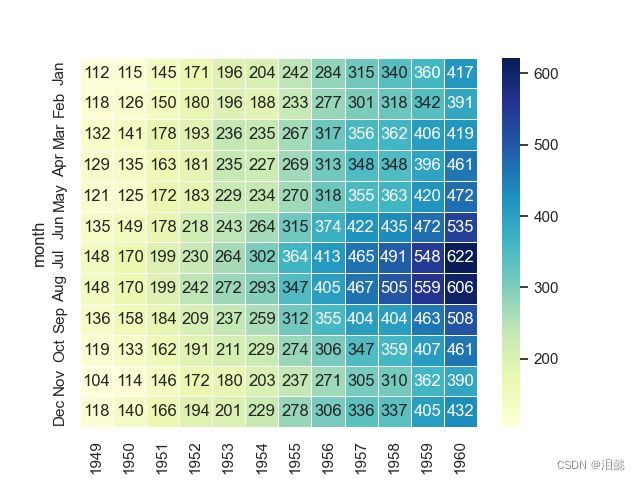
 可以显示每个数据,增加间隔
可以显示每个数据,增加间隔
- annot是否显示数据,fmt字体格式,linewwidth间距,cmap调色板
flights=sns.load_dataset('flights')#读取航班数据
flights=flights.pivot("month",'year',"passengers")
#annot是否显示数据,fmt字体格式,linewwidth间距,cmap调色板
ax=sns.heatmap(flights,annot=True,fmt='d',linewidths=.5,cmap="YlGnBu")
- 散点图
data=sns.load_dataset('tips')
sns.catplot(x="day", y="total_bill", data=data)
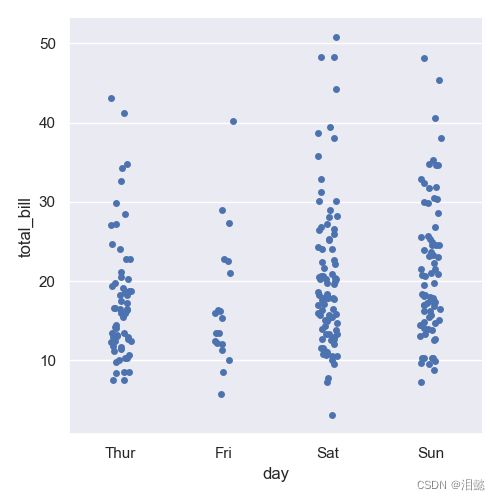
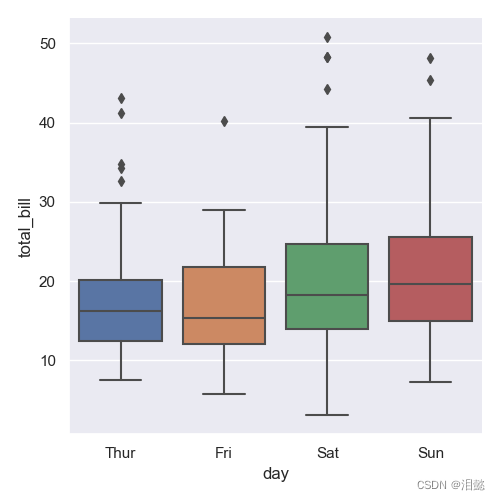
- 箱线图
data=sns.load_dataset('tips')
sns.catplot(x='day',y='total_bill',kind='box',data=data)
plt.savefig('1.png')
plt.show()
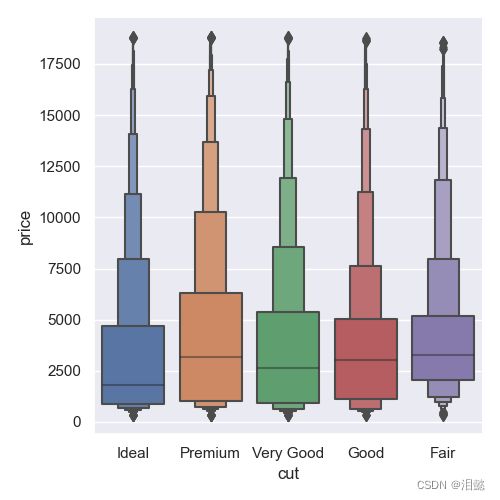
data = sns.load_dataset("diamonds")
sns.catplot(x="cut", y="price", kind="boxen",
data=data.sort_values("cut"))
- 条形图
data = sns.load_dataset("titanic")
sns.catplot(x="alone", y="age", hue="class", kind="bar", data=data)

3.数据集的分布
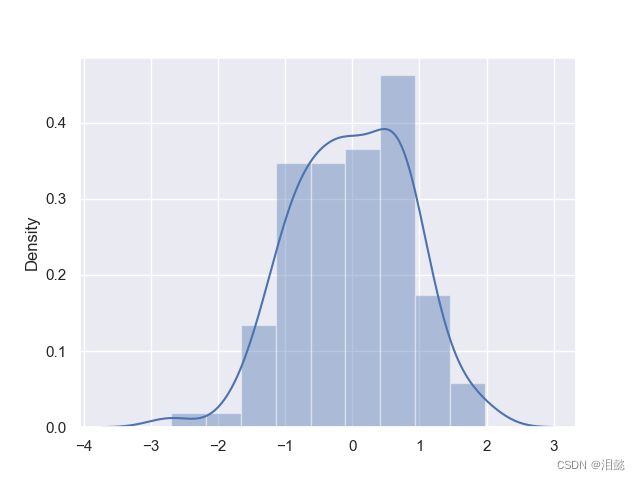
- 直方图并拟合
data= np.random.normal(size=100)
sns.distplot(data)
- 核密度
- numpy.random.multivariate_normal 是NumPy的一个函数,用于生成多元正态分布的随机样本。它接受两个必需参数:均值和协方差矩阵,并返回一个随机数样本数组,该数组的形状由第一个参数确定。
具体地,如果您传递一个形状为 (n,) 的均值向量和一个形状为 (n, n) 的协方差矩阵,函数将生成一个形状为 (m, n) 的随机数样本数组,其中 m 是您希望生成的样本数。每一行是一个长度为 n 的向量,表示一个多元正态分布的样本。
例如,以下代码将生成一个形状为 (100, 2) 的随机数样本数组,其中每一行表示一个二元正态分布的样本:
- numpy.random.multivariate_normal 是NumPy的一个函数,用于生成多元正态分布的随机样本。它接受两个必需参数:均值和协方差矩阵,并返回一个随机数样本数组,该数组的形状由第一个参数确定。
import numpy as np
mean = [0, 0]
cov = [[1, 0.5], [0.5, 1]]
samples = np.random.multivariate_normal(mean, cov, 100)
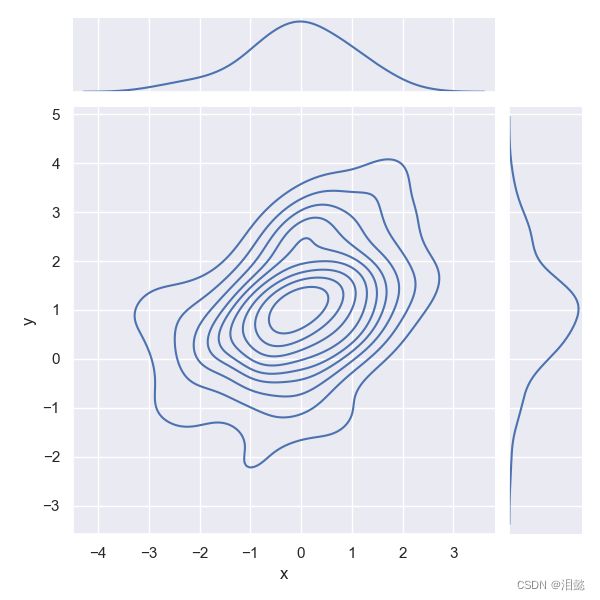
生成核密度图
mean, cov = [0, 1], [(1, .5), (.5, 1)]
data = np.random.multivariate_normal(mean, cov, 100)
df=pd.DataFrame(data,columns=['x','y'])
sns.jointplot(x="x", y="y", data=df, kind="kde")
- 数据集中的成对关系
iris = sns.load_dataset("iris")
sns.pairplot(iris)

4.线性关系
- 通过regplot()和lmplot()函数拟合回归模型y~x并绘制得到回归线和该回归的 95%置信区间
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(color_codes=True)
data=sns.load_dataset("tips")
sns.regplot(x='total_bill',y="tip",data=data)

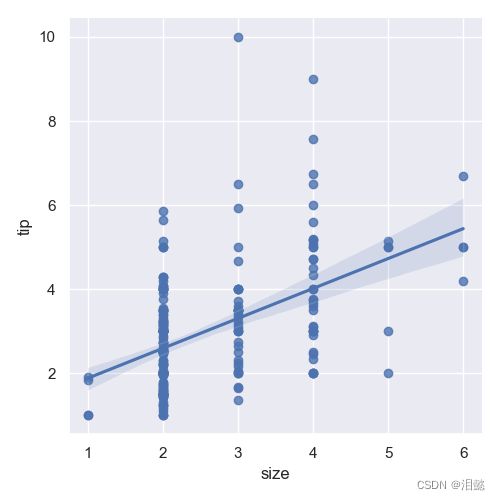
当变量有离散值时候,可以拟合线性回归
sns.lmplot(x="size", y="tip", data=data)
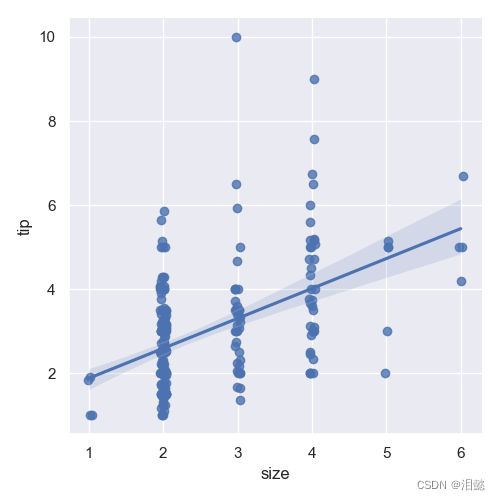
由于可能得到不是最优解,所以可以添加噪音或者综合每个离散箱中的观测值,以绘制集中趋势的估计值和置信区间。
sns.lmplot(x="size", y="tip", data=data,x_jitter=0.04)
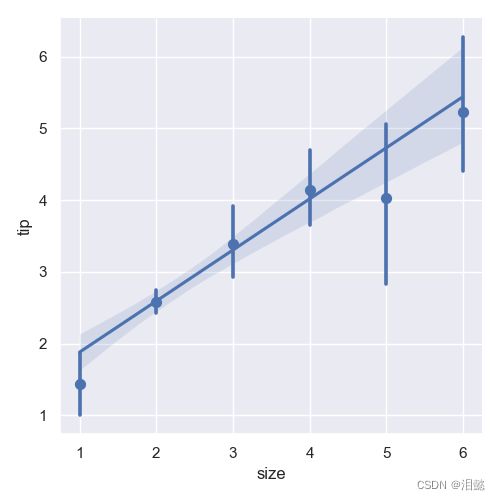
sns.lmplot(x="size", y="tip", data=data,x_estimator=np.mean)
5. 结构化构图
sns居于强大的网格图功能
- 初始化网格
data=sns.load_dataset('tips')
g=sns.FacetGrid(data,col='time')
- FacetGrid.map()是绘制网格数据的主要方法
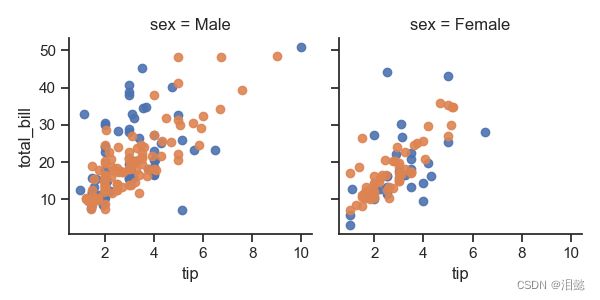
data=sns.load_dataset('tips')
g=sns.FacetGrid(data,col='sex',hue='smoker')
g.map(plt.scatter,'tip','total_bill',alpha=0.9)
6.风格设置
seaborn内置了5种主题风格
- darkgrid,whitegrid,dark,white , ticks
sns.set_style("whitegrid")#设置主题风格
可以根据喜好与情况选择,也可以自定义
通过给 axes_style() 与set_style()函数中的 rc 参数传递一个参数字典来实现,具体想深入研究,可以看文档
实例
sns.set_style("darkgrid", {"axes.facecolor": "0.6"})
总结
seaborn作为一个强大的可视化模块,在数据分析机器学习有很大的作用,但其功能远不在这里,如果想更加深入了解,可以访问其 官网地址或者中文文档
希望大家多多支持,一起努力学习,后续慢慢分享更多新奇有趣的东西