seaborn数据可视化
1、加载seaborn自带的数据集,数据集名称“car_crashes”。
(1)画出“total”列与“alcohol”列的散点图。要求:有中文标题,样式自行设计(比如:散点图的风格、颜色、形状等),最后探索这两者的关系,写出分析结果。
import seaborn as sns
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
sns.set_style('darkgrid')
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
sns.set_style({'font.sans-serif':['simhei', 'Arial']})
data=pd.read_csv('../date/seaborn-data-master/car_crashes.csv',encoding='gbk')
# print(data)
# 1)画出“total”列与“alcohol”列的散点图。
yi=sns.scatterplot(x='alcohol',y='total',data=data,)
plt.xlabel('alcohol')
plt.ylabel('total')
plt.title('alcohol列与total列的散点图')
plt.show()

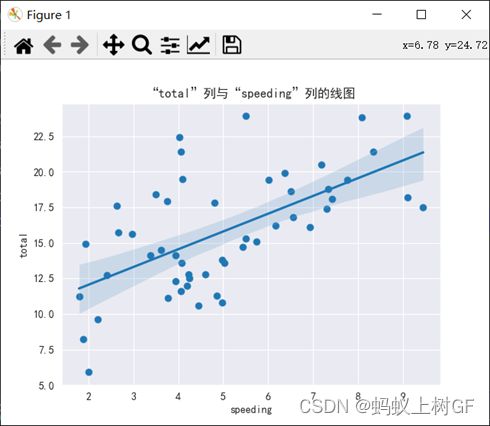
(2)画出“total”列与“speeding”列的线图。要求:有中文标题,样式自行设,最后分析两者之间的变化规律。
sns.scatterplot(x='speeding',y='total',data=data)
sns.regplot(x='speeding',y='total',data=data)
plt.title('“total”列与“speeding”列的线图')
plt.show()
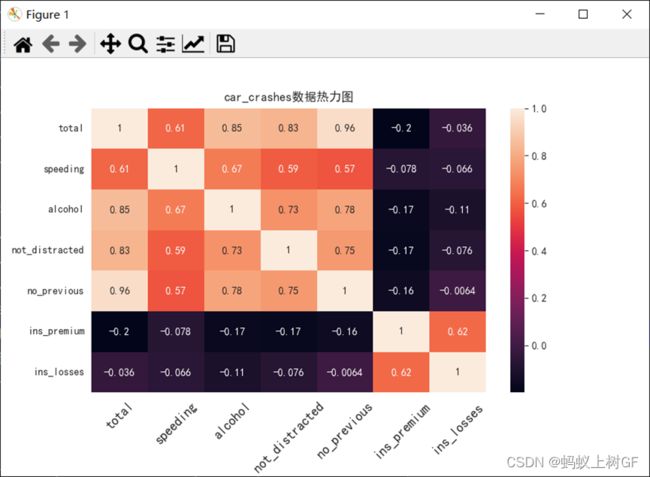
(3)探索car_crashes数据中各特征列之间的相关性,画出对应的热力图,要求热力图有数字标识,有标题,最后对主要几列比较明显特征关系的做出结论。
df=pd.DataFrame(data)
df=df.iloc[:,0:7]
xg=df.corr()
sns.heatmap(xg,annot=True)
plt.xticks(rotation=45,fontsize=13)
plt.title('car_crashes数据热力图')
plt.show()
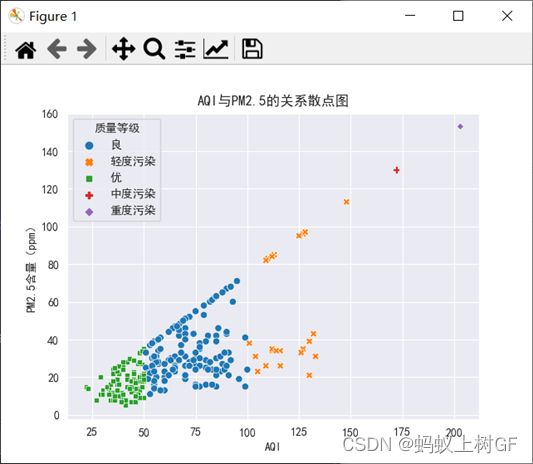
2、加载aqi.csv文件,探索各空气质量指数之间的关系。可视化期间解决中文字体显示的问题,设置字体为黑体,并解决保存图像时负号(-)显示为方块的问题。

(1)绘制AQI与PM2.5的关系散点图,要求根据“质量等级”的不同进行区分颜色和凸显不同的形状。并做出分析结论
import seaborn as sns
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
sns.set_style('darkgrid')
sns.set_style({'font.sans-serif':['simhei', 'Arial']})
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
sns.set_style({'font.sans-serif':['simhei', 'Arial']})
data=pd.read_csv('D:\\subject\\数据可视化\\实验要求\\实验2\\aqi.txt')
print(data)
# 1)绘制AQI与PM2.5的关系散点图
yi=sns.scatterplot(x='AQI',y='PM2.5含量(ppm)',data=data,hue="质量等级",style="质量等级")
plt.title('AQI与PM2.5的关系散点图')
plt.show()
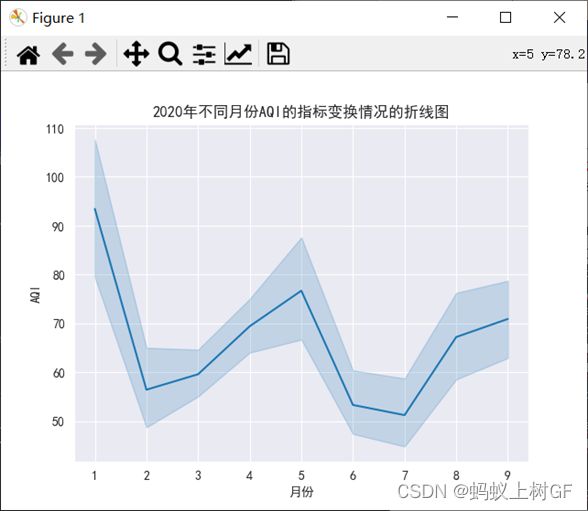
(2)绘制出所有数据在不同时间内AQI的指标变换情况的折线图。
df2=data.iloc[:,0:2]
df3=df2['日期'].str.split('/',expand=True)#分隔日期
df2.insert(2,'月份',df3.loc[:,1])
# print(df2)
sns.lineplot(x='月份',y='AQI',data=df2)
plt.title('2020年不同月份AQI的指标变换情况的折线图')
plt.show()
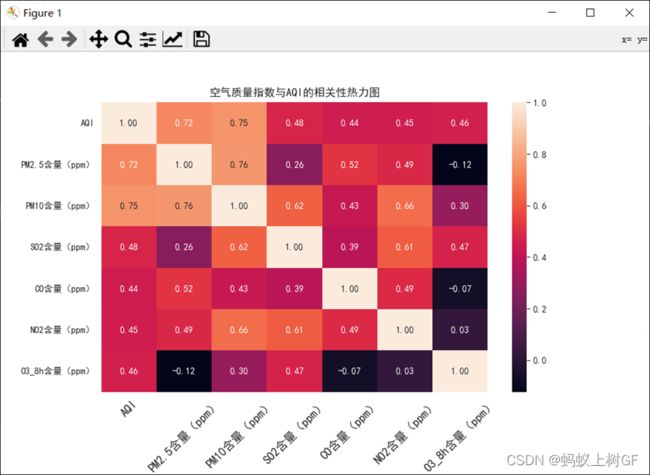
(3)分析各空气质量指数与AQI的相关性,绘制特征相关性热力图,要求热力图有数字标识,有标题,最后做出结论。
df=data.loc[:,['AQI','PM2.5含量(ppm)','PM10含量(ppm)','SO2含量(ppm)','CO含量(ppm)','NO2含量(ppm)','O3_8h含量(ppm)']]
xg=df.corr()
sns.heatmap(xg,annot=True,fmt='.2f')
plt.xticks(rotation=45,fontsize=13)
plt.title('空气质量指数与AQI的相关性热力图')
plt.show()
3、加载aqi.csv文件,探索各空气质量指数之间的关系。可视化期间使用seaborn库和matplotlib的函数解决中文字体显示的问题,设置字体为黑体,并解决保存图像时负号(-)显示为方块的问题,图像要有标题,其余样式自行设计。

import seaborn as sns
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
sns.set_style('whitegrid')
sns.set_style({'font.sans-serif':['simhei', 'Arial']})
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
sns.set_style({'font.sans-serif':['simhei', 'Arial']})
#忽略警告
import warnings
warnings.filterwarnings('ignore')
data=pd.read_csv("D:\\subject\\数据可视化\\实验要求\\实验3\\aqi.txt")
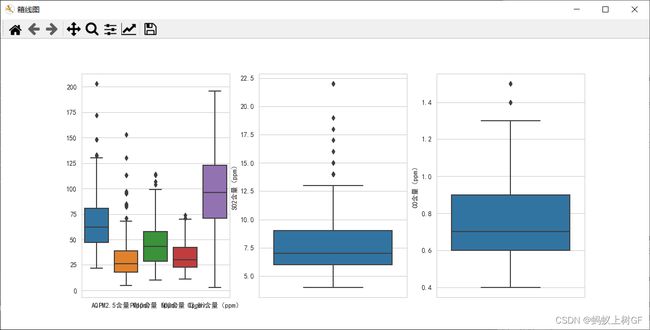
(1)绘制一行三列的三个子图在一张画布中,其中第一个子图绘制"AQI","PM2.5含量(ppm)","PM10含量(ppm)","NO2含量(ppm)","O3_8h含量(ppm)"五列数据的箱线图,第二个子图绘制"SO2含量(ppm)"的箱线图,第三个子图绘制"CO含量(ppm)"的箱线图。
fig = plt.figure('箱线图',figsize=(10,5))
fig.add_subplot(1,3,1)
sns.boxplot(data=data[["AQI","PM2.5含量(ppm)","PM10含量(ppm)","NO2含量(ppm)","O3_8h含量(ppm)"]])
fig.add_subplot(1,3,2)
sns.boxplot(y='SO2含量(ppm)',data=data)
fig.add_subplot(1,3,3)
sns.boxplot(y='CO含量(ppm)',data=data)
plt.show()
(2)绘制空气质量等级与PM2.5含量(ppm)的分类散点图。
sns.stripplot(x='质量等级',y='PM2.5含量(ppm)',data=data)
plt.show()

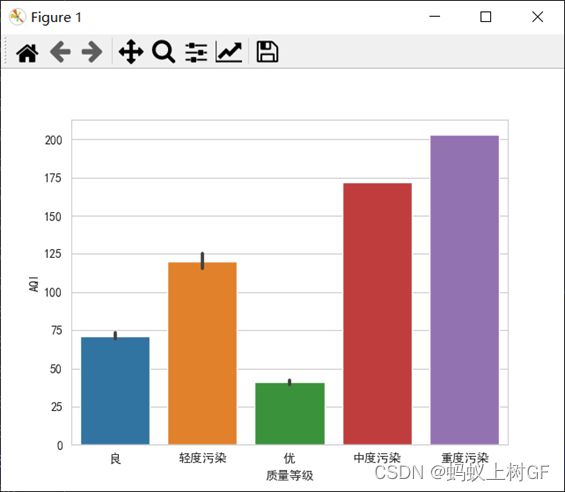
(3)使用条形图绘制不同空气质量等级下的AQI的平均值。
sns.barplot(x='质量等级',y='AQI',data=data)
plt.show()
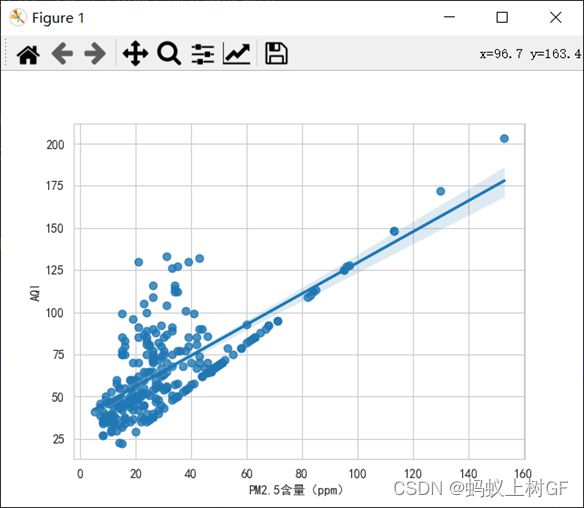
(4)绘制PM2.5与AQI的线性回归拟合图。
sns.regplot(x='PM2.5含量(ppm)',y='AQI',data=data)
plt.show()
4、将gdp_total.sql文件导入到mysql数据库,该数据表是2000-2019年国内生产总值的数据,使用seaborn库和matplotlib解决中文字体显示的问题,设置字体为黑体,并解决保存图像时负号(-)显示为方块的问题,图像要有标题,其余样式自行设计。
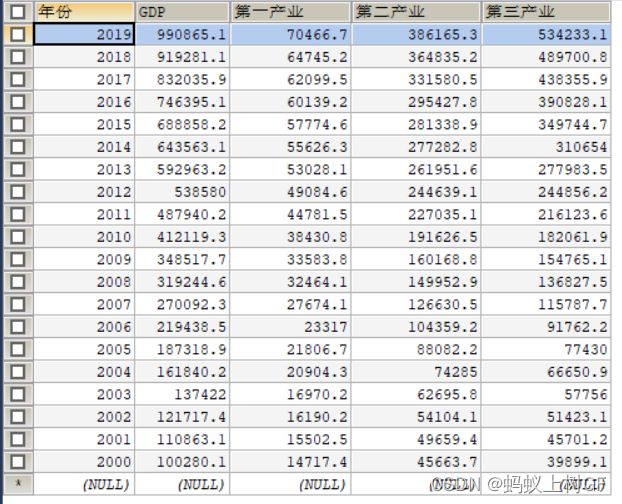
import seaborn as sns
import pymysql
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
sns.set_style('whitegrid')
sns.set_style({'font.sans-serif':['simhei', 'Arial']})
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus']=False #正常显示负号
(1)绘制第一产业增加值、第二产业增加值、第三产业增加值三者之间的相关系数热力图,并得出结论。
提示:
#连接MySQL数据库,读取数据库表数据核心代码
conn = pymysql.connect(host='127.0.0.1',port=3306,user='root',password='123123',db='stu',charset='utf8')
sql = "SELECT 年份 as year,Round(第一产业/10000,2) as primary_value,Round(第二产业/10000,2) as secondary_value,Round(第三产业/10000,2) as tertiary_value FROM gdp_total order by 年份 asc"
df = pd.read_sql(sql,conn)
'''1)绘制第一产业增加值、第二产业增加值、第三产业增加值三者之间的相关系数热力图,并得出结论。'''
conn = pymysql.connect(
host='localhost',
port=3306,user='root',
password='123456',
db='visual translation',
charset='utf8')
sql = "SELECT 年份 as year,Round(第一产业/10000,2) as primary_value,Round(第二产业/10000,2) as secondary_value,Round(第三产业/10000,2) as tertiary_value FROM gdp_total order by 年份 asc"
df = pd.read_sql(sql,conn)
#计算皮尔逊相关系数
corr=df[['primary_value','secondary_value','tertiary_value']]
# print(corr)
#绘制相关系数热力图
plt.figure(figsize=[12,7])
sns.heatmap(corr,annot=True,fmt='.4f')
plt.show()

(2)绘制第一产业增加值与第二产业增加值之间的线性回归图,并得出结论
#连接MySQL数据库,读取数据库表数据核心代码
conn = pymysql.connect(host='127.0.0.1',port=3306,user='root',password='123123',db='stu',charset='utf8')
sql = "SELECT 年份 as year,Round(第一产业/10000,2) as primary_value,Round(第二产业/10000,2) as secondary_value,Round(第三产业/10000,2) as Tertiary_value FROM gdp_total order by 年份 asc"
df = pd.read_sql(sql,conn)
sql2=sql = "SELECT 年份 as year,Round(第一产业/10000,2) as primary_value,Round(第二产业/10000,2) as secondary_value,Round(第三产业/10000,2) as Tertiary_value FROM gdp_total order by 年份 asc"
df2=pd.read_sql(sql2,conn)
# print(df2)
sns.regplot(x='primary_value',y='secondary_value',data=df2)
plt.show()
