小程序云开发快速入门(2/4)
前言
我们对《微信小程序云开发快速入门(1/4)》的知识进行回顾一下。在上章节我们知道了云开发的优势以及能力,并且我们还完成了码仔备忘录的本地版到网络版的改造,主要学习了云数据库同时还通过在小程序使用云API直接操作了云数据库:
- 使用 get() 进行了数据库的查询
- 使用 add() 进行了数据添加
- 使用 update() 进行了数据修改
- 使用 remove() 进行了数据删除
本章节给大家带来「排序」「精准」「模糊」「分页」这四种查询方式在实际业务种也是经常用到的。
列表排序
默认情况下小程序查询出来的列表是按时间来排序的,最新添加的数据在最后面。但是实际需求是需要最新添加的在最前面,那么这个时候我们就需要用排序函数 orderBy 来改变它的排序规则。
在 orderBy 具体使用方法(通过数据库对象直接链式调用的方法,在使用 get 方法之前使用):
文档示例代码:按进度排升序取待办事项
db.collection('todos').orderBy('progress', 'asc')
.get()
.then(console.log)
.catch(console.error)
参数分别:
- 需要排序的字段名
- 排序具体的规则
- asc:升序,从小到大
- desc:降序,从大到小
同时支持多个字段组合排序,优先级根据调用顺序来决定
当我们学习到这个API到时候,再来思考下如何实现具体需求,实现这个需求一共有两种方式:
新增时间字段排序
这个时候我们可以在新增/修改的时候去设置时间戳字段 createTime ,然后通过时间戳字段进行排序。
添加 createTime 属性代码写在编辑页面的 save 保存方法中
时间戳获取的4种方式
let createTime1 = Date.parse(new Date()); // 精确到秒
let createTime2 = new Date().getTime(); // 精确到毫秒
let createTime3 = new Date().valueOf(); // 精确到毫秒
let createTime4 = Date.now(); // 精确到毫秒,实际上是new Date().getTime()
排序代码:
db.collection('memo').orderBy('createTime', 'desc').get()
组合时间字段排序
除此之外还有同学在没有新增字段的情况下也完成了同样的效果,使用了多个字段组合排序。
db.collection('memo').orderBy('date','desc').orderBy('time','desc').get()
先对日期进行了排序,然后再对时间进行排序。在这里要注意有的同学只对时间进行了排序,这种情况下如果是同一天的数据排序正常,但是是多天的情况下顺序就会乱掉。
根据内容查询
为了更高效的找到备忘录,那么搜索是必不可少的,接下来我们会使用 where 函数来实现搜索功能。首先我们需要来一个搜索框,在这里再告诉大家一个小技巧一些常用的组件我们可以通过引用的成熟UI组件库来进行快速实现,上次我们学习了用npm应用时间工具包,接下来我们扩展库引入WeUI组件。
使用UI组件库
- 在app.json中配置:
{
"useExtendedLib": {
"weui": true
}
}
相当于引入了对应扩展库相关的最新版本的 npm 包,同时也不占用小程序的包体积。
2. 在使用的页面json配置搜索组件
{
"usingComponents": {
"mp-searchbar": "weui-miniprogram/searchbar/searchbar"
}
}
- 在页面需要的位置添加布局代码,插入到列表之上,头部之下的位置
显示效果:
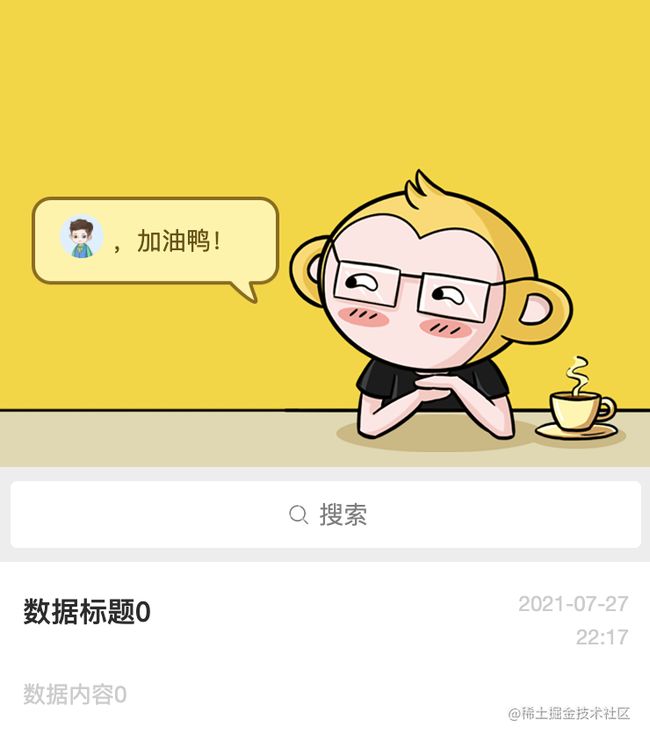
4. 监听输入框数据
searchTitle: function (event) {
console.log('search',event.detail.value)
}
到这里,我相信大家一定有对UI组件库相见恨晚对感觉,写样式实在是太痛苦了!但是话说回来,组件库只是覆盖了我们常用组件,如果组件库没有的组件我们还是要老老实实自己写,所以在样式的编写能力还是非常重要的,在学习的过程中一定要多加练习。
精准查询
当我们拿到数据后就开始去查询,在这里我们需要改造下我们的 getMemoList 函数。
// 获取备忘录列表,支持搜索标题
function getMemoList(value) {
// 1. 获取数据库引用
const db = wx.cloud.database()
// 2. 找到集合获取数据
let memo = db.collection('memo')
// 3. 判断是否有查询数据
if (value) {
memo = memo.where({
title: value
})
}
// 4. 判断查询返回数据
return memo.orderBy('createTime', 'desc').get()
}
然后在监听的时候调用
searchTitle: function (event) {
let value = event.detail.value
getMemoList(value).then(res=>{
console.log(res.data)
this.udpateList(res.data)
})
}
实现效果:
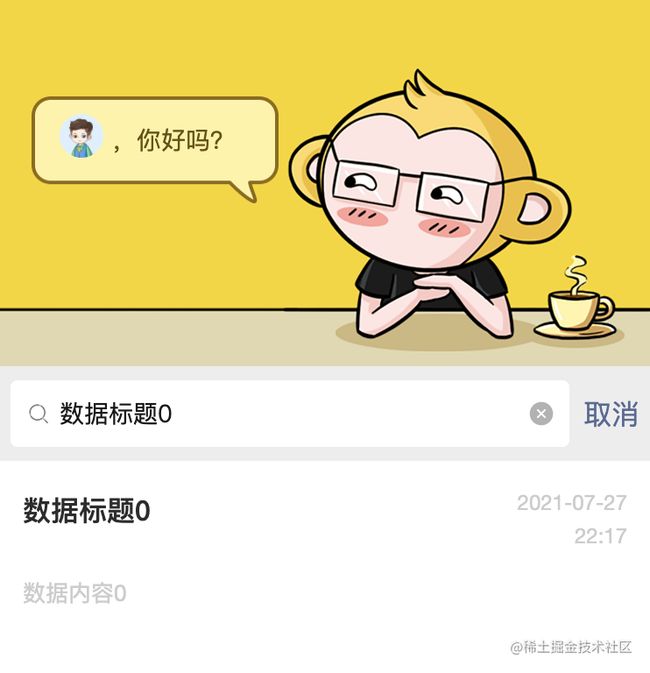
但是实际场景下,很多时候我们都是通过模糊匹配,因为有可能备忘录的标题过长了,不便于用户记住。
模糊查询
在这里主要是查询条件用正则匹配,使用 RegExp 构造器构造正则对象。
memo.where({
title: db.RegExp({
regexp: value, //从搜索栏中获取的value作为规则进行匹配。
options: 'i', //大小写不区分
})
实现效果:

分页查询
当备忘录使用的时间越来越长的时候,那么数据也会随着变多,这个时候实际需求也不需要一次性全部加载出来,那么分页的需求就随之而来。小程序端操作云数据库的 get() 获取数据API,一次性最多拉取20条。
那么如何进行数据分页?官方给出了案例:
db.collection('todos')
.where({
_openid: 'xxx', // 填入当前用户 openid
})
.skip(10) // 跳过结果集中的前 10 条,从第 11 条开始返回
.limit(10) // 限制返回数量为 10 条
.get()
.then(res => {
console.log(res.data)
})
.catch(err => {
console.error(err)
})
主要是通过 skip 和 limit 。
skip:从第多少条开始取
limit:一次性取多少条数据
我们来根据实际业务来实现下
- 定义页数和每页数量
/**
* 页面的初始数据
*/
data: {
pageNo:0, // 默认第一页
pageSize:5, // 一页5条数据
},
- 改造列表数据查询函数
function getMemoList(pageNo, pageSize) {
const db = wx.cloud.database()
return db.collection('memo')
.skip(pageNo * pageSize)
.limit(pageSize)
.orderBy('createTime', 'desc')
.get()
}
- 首次调用方式传入参数
onShow() {
getMemoList(this.data.pageNo,this.data.pageSize).then(res => {
this.udpateList(res.data)
})
}
- 监听页面上拉回调事件
// 上拉加载
onReachBottom (){
this.loadList()
}
- 实现具体数据加载逻辑
async loadList(){
// 1. 获取总条数
let {total} = await getListTotal()
// 2. 判断是否全部已经加载完毕
if(this.data.list.length注意:
- 以上逻辑中使用async/await来减少了回调让代码可读写更强。
- 以上逻辑中使用到获取列表总数的 getListTotal 使用了 count 函数。
function getListTotal() {
const db = wx.cloud.database()
return db.collection('memo').count()
}
指定返回
在实际业务中通常列表子项详情很多,但是列表只需要展示部分关键信息,那么这个时候我们就只需要查列表需要展示的字段,指定返回结果,没有必要的字段就不需要返回,使用 field 进行实现。
如:当前列表只需要显示标题字段数据。
// 获取备忘录列表
function getMemoList(pageNo, pageSize) {
const db = wx.cloud.database()
return db.collection('memo')
.field({
title: true,
})
.get()
}
数据返回
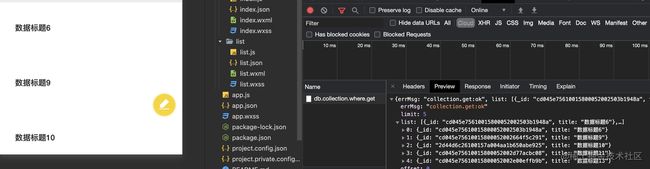
在实际业务场景也是列表通常不会查询出所有数据,点击详情才会把所有数据通过id查询出来,所以在列表页面到详情页面参数也是最佳做法是传递id字段,而不是把列表点击对象传递到详情页面。
总结
今日学习:
- 数据库 orderBy 排序条件
- 使用扩展库WeUI组件库
- 数据库 where 查询条件
- 数据库 skip、limit、count 组合实现分页查询
- 数据库 field 指定返回字段
学习更多小程序云开发快速入门知识请关注CRMEB