python与深度学习(十五):CNN和宝可梦模型
目录
- 1. 说明
- 2. 宝可梦模型
-
- 2.1 导入相关库
- 2.2 建立模型
- 2.3 模型编译
- 2.4 数据生成器
- 2.5 模型训练
- 2.6 模型保存
- 3. 宝可梦的CNN模型可视化结果图
- 4. 完整代码
- 5. 宝可梦的迁移学习
1. 说明
本篇文章是CNN的另外一个例子,宝可梦模型,是自制数据集的例子。之前的例子都是python中库自带的,但是这次的例子是自己搜集数据集,如下图所示整理。

之前简单介绍如何自制数据集,在这里继续介绍将自制的数据划分为训练集,测试集和验证集。
首先建立一个pokeman的文件夹,然后利用之前介绍的爬虫下载5种宝可梦的图片,然后运行下面代码。
import glob
import os
import cv2
import numpy as np
import random
import tensorflow as tf
from tensorflow import keras
tf.random.set_seed(520)
np.random.seed(520)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
assert tf.__version__.startswith('2.')
def Data_Generation():
X_data = [];
Y_data = []
path_data = [];
path_label = []
# path_file=os.getcwd() #获取当前工作目录
files = os.listdir('pokeman') # 获取'pokeman'文件夹下的所有文件名
for file in files:
print(file)
for path in glob.glob('pokeman/' + file + '/*.*'):
if 'jpg' or 'png' or 'bmp' in path: # 只获取jpg/png/bmp格式的图片
path_data.append(path)
random.shuffle(path_data) # 打乱数据
for paths in path_data: #
if 'bulbasaur' in paths: # 为每一类打标签
path_label.append(0)
elif 'charmander' in paths:
path_label.append(1)
elif 'mewtwo' in paths:
path_label.append(2)
elif 'pikachu' in paths:
path_label.append(3)
elif 'squirtle' in paths:
path_label.append(4)
img = cv2.imread(paths) # 用opencv读图片数据
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # cv的图片通道是BGR,要转换成送入NN的RGB
img = cv2.resize(img, (96, 96)) # 统一图片大小
X_data.append(img)
L = len(path_data)
Y_data = path_label
X_data = np.array(X_data, dtype=float)
Y_data = np.array(Y_data, dtype='uint8')
X_train = X_data[0:int(L * 0.8)] # 将数据分为训练集 验证集和测试集 比例为 0.8:0.1:0.1
print(X_train.shape)
Y_train = Y_data[0:int(L * 0.8)]
print(Y_train.shape)
X_valid = X_data[int(L * 0.8):int(L * 0.9)]
Y_valid = Y_data[int(L * 0.8):int(L * 0.9)]
X_test = X_data[int(L * 0.9):]
Y_test = Y_data[int(L * 0.9):]
return X_train, Y_train, X_valid, Y_valid, X_test, Y_test, L
X_train, Y_train, X_valid, Y_valid, X_test, Y_test, L = Data_Generation()
np.savez(os.path.join('pokeman', 'data.npz'), X_train=X_train, Y_train=Y_train, X_valid=X_valid, Y_valid=Y_valid,
X_test=X_test, Y_test=Y_test)
# 打包成npz的压缩格式 储存在工程文件目录中,这样运行程序进行测试时就不用每次都重复生成数据,直接调用npz就好
2. 宝可梦模型
2.1 导入相关库
以下第三方库是python专门用于深度学习的库。需要提前下载并安装
from keras.models import Sequential
from keras.layers import Dense, Conv2D, Flatten, Dropout, MaxPool2D
from keras import optimizers, losses
from keras.preprocessing.image import ImageDataGenerator
import sys, os # 目录结构
import matplotlib.pyplot as plt
from keras.callbacks import EarlyStopping, ReduceLROnPlateau
2.2 建立模型
这是采用另外一种书写方式建立模型。
构建了三层卷积层,三层池化层,然后是展平层(将二维特征图拉直输入给全连接层),然后是三层全连接层,并且加入了dropout层。
"1.模型建立"
# 1.卷积层,输入图片大小(96, 96, 3), 卷积核个数16,卷积核大小(5, 5), 激活函数'relu'
conv_layer1 = Conv2D(input_shape=(96, 96, 3), filters=16, kernel_size=(5, 5), activation='relu')
# 2.最大池化层,池化层大小(2, 2), 步长为2
max_pool1 = MaxPool2D(pool_size=(2, 2), strides=2)
# 3.卷积层,卷积核个数32,卷积核大小(5, 5), 激活函数'relu'
conv_layer2 = Conv2D(filters=32, kernel_size=(5, 5), activation='relu')
# 4.最大池化层,池化层大小(2, 2), 步长为2
max_pool2 = MaxPool2D(pool_size=(2, 2), strides=2)
# 5.卷积层,卷积核个数64,卷积核大小(5, 5), 激活函数'relu'
conv_layer3 = Conv2D(filters=64, kernel_size=(5, 5), activation='relu')
# 6.最大池化层,池化层大小(2, 2), 步长为2
max_pool3 = MaxPool2D(pool_size=(2, 2), strides=2)
# 7.卷积层,卷积核个数128,卷积核大小(5, 5), 激活函数'relu'
conv_layer4 = Conv2D(filters=128, kernel_size=(5, 5), activation='relu')
# 8.最大池化层,池化层大小(2, 2), 步长为2
max_pool4 = MaxPool2D(pool_size=(2, 2), strides=2)
# 9.展平层
flatten_layer = Flatten()
# 10.Dropout层, Dropout(0.2)
third_dropout = Dropout(0.2)
# 11.全连接层/隐藏层1,240个节点, 激活函数'relu'
hidden_layer1 = Dense(240, activation='relu')
# 12.全连接层/隐藏层2,84个节点, 激活函数'relu'
hidden_layer3 = Dense(84, activation='relu')
# 13.Dropout层, Dropout(0.2)
fif_dropout = Dropout(0.5)
# 14.输出层,输出节点个数5, 激活函数'softmax'
output_layer = Dense(5)
model = Sequential([conv_layer1, max_pool1, conv_layer2, max_pool2,
conv_layer3, max_pool3, conv_layer4, max_pool4,
flatten_layer, third_dropout, hidden_layer1,
hidden_layer3, fif_dropout, output_layer])
2.3 模型编译
模型的优化器是Adam,学习率是0.01,
损失函数是binary_crossentropy,二分类交叉熵,
性能指标是正确率accuracy,
另外还加入了回调机制。
回调机制简单理解为训练集的准确率持续上升,而验证集准确率基本不变,此时已经出现过拟合,应该调制学习率,让验证集的准确率也上升。
"2.模型编译"
# 模型编译,2分类:binary_crossentropy
model.compile(optimizer=optimizers.Adam(lr=1e-3),
loss=losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.summary() # 模型统计
# 回调机制 动态调整学习率
reduce = ReduceLROnPlateau(monitor='val_accuracy', # 设置监测的值为val_accuracy
patience=2, # 设置耐心容忍次数为2
verbose=1, #
factor=0.5, # 缩放学习率的值为0.5,学习率将以lr = lr*factor的形式被减少
min_lr=0.000001 # 学习率最小值0.000001
) # 监控val_accuracy增加趋势
2.4 数据生成器
加载自制数据集
利用数据生成器对数据进行数据加强,即每次训练时输入的图片会是原图片的翻转,平移,旋转,缩放,这样是为了降低过拟合的影响。
然后通过迭代器进行数据加载,目标图像大小统一尺寸96963,设置每次加载到训练网络的图像数目,设置而分类模型(默认one-hot编码),并且数据打乱。
# 生成器对象1: 归一化
gen = ImageDataGenerator(rescale=1 / 255.0)
# 生成器对象2: 归一化 + 数据加强
gen1 = ImageDataGenerator(
rescale=1 / 255.0,
rotation_range=5, # 图片随机旋转的角度5度
width_shift_range=0.1,
height_shift_range=0.1, # 水平和竖直方向随机移动0.1
shear_range=0.1, # 剪切变换的程度0.1
zoom_range=0.1, # 随机放大的程度0.1
fill_mode='nearest') # 当需要进行像素填充时选择最近的像素进行填充
# 拼接训练和验证的两个路径
train_path = os.path.join(sys.path[0], 'data', 'train')
val_path = os.path.join(sys.path[0], 'data', 'val')
print('训练数据路径: ', train_path)
print('验证数据路径: ', val_path)
# 训练和验证的两个迭代器
train_iter = gen1.flow_from_directory(train_path, # 训练train目录路径
target_size=(96, 96), # 目标图像大小统一尺寸96
batch_size=8, # 设置每次加载到内存的图像大小
class_mode='categorical', # 设置分类模型(默认one-hot编码)
shuffle=True) # 是否打乱
val_iter = gen.flow_from_directory(val_path, # 测试val目录路径
target_size=(96, 96), # 目标图像大小统一尺寸96
batch_size=8, # 设置每次加载到内存的图像大小
class_mode='categorical', # 设置分类模型(默认one-hot编码)
shuffle=True) # 是否打乱
2.5 模型训练
模型训练的次数是30,每1次循环进行测试
"3.模型训练"
# 模型的训练, model.fit
result = model.fit(train_iter, # 设置训练数据的迭代器
epochs=30, # 循环次数30次
validation_data=val_iter, # 验证数据的迭代器
callbacks=[reduce], # 回调机制设置为reduce
validation_freq=1)
2.6 模型保存
以.h5文件格式保存模型
"4.模型保存"
# 保存训练好的模型
model.save('my_bkm.h5')
"5.模型训练时的可视化"
# 显示训练集和验证集的acc和loss曲线
acc = result.history['accuracy'] # 获取模型训练中的accuracy
val_acc = result.history['val_accuracy'] # 获取模型训练中的val_accuracy
loss = result.history['loss'] # 获取模型训练中的loss
val_loss = result.history['val_loss'] # 获取模型训练中的val_loss
# 绘值acc曲线
plt.figure(1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.savefig('my_bkm_acc.png', dpi=600)
# 绘制loss曲线
plt.figure(2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.savefig('my_bkm_loss.png', dpi=600)
plt.show() # 将结果显示出来
3. 宝可梦的CNN模型可视化结果图
Found 116 images belonging to 5 classes.
Epoch 1/30
56/118 [=============>................] - ETA: 12s - loss: 1.5176 - accuracy: 0.3061F:\python_code\python_study\venv\lib\site-packages\PIL\Image.py:993: UserWarning: Palette images with Transparency expressed in bytes should be converted to RGBA images
"Palette images with Transparency expressed in bytes should be "
118/118 [==============================] - 25s 205ms/step - loss: 1.3913 - accuracy: 0.3863 - val_loss: 1.1440 - val_accuracy: 0.4310 - lr: 0.0010
Epoch 2/30
118/118 [==============================] - 22s 190ms/step - loss: 0.9990 - accuracy: 0.5646 - val_loss: 0.8448 - val_accuracy: 0.6466 - lr: 0.0010
Epoch 3/30
118/118 [==============================] - 22s 190ms/step - loss: 0.8921 - accuracy: 0.5966 - val_loss: 0.8387 - val_accuracy: 0.5862 - lr: 0.0010
Epoch 4/30
118/118 [==============================] - 22s 186ms/step - loss: 0.7903 - accuracy: 0.6649 - val_loss: 0.6711 - val_accuracy: 0.6638 - lr: 0.0010
Epoch 5/30
118/118 [==============================] - 22s 186ms/step - loss: 0.8736 - accuracy: 0.6638 - val_loss: 0.5738 - val_accuracy: 0.7759 - lr: 0.0010
Epoch 6/30
118/118 [==============================] - 23s 192ms/step - loss: 0.6817 - accuracy: 0.7225 - val_loss: 0.6160 - val_accuracy: 0.7241 - lr: 0.0010
Epoch 7/30
118/118 [==============================] - ETA: 0s - loss: 0.6360 - accuracy: 0.7204
Epoch 7: ReduceLROnPlateau reducing learning rate to 0.0005000000237487257.
118/118 [==============================] - 24s 201ms/step - loss: 0.6360 - accuracy: 0.7204 - val_loss: 0.5757 - val_accuracy: 0.7586 - lr: 0.0010
Epoch 8/30
118/118 [==============================] - 25s 213ms/step - loss: 0.5462 - accuracy: 0.7994 - val_loss: 0.5143 - val_accuracy: 0.7845 - lr: 5.0000e-04
Epoch 9/30
118/118 [==============================] - 23s 198ms/step - loss: 0.5129 - accuracy: 0.8282 - val_loss: 0.4831 - val_accuracy: 0.8103 - lr: 5.0000e-04
Epoch 10/30
118/118 [==============================] - 26s 218ms/step - loss: 0.4712 - accuracy: 0.8410 - val_loss: 0.4913 - val_accuracy: 0.8276 - lr: 5.0000e-04
Epoch 11/30
118/118 [==============================] - 24s 204ms/step - loss: 0.3914 - accuracy: 0.8954 - val_loss: 0.4444 - val_accuracy: 0.8190 - lr: 5.0000e-04
Epoch 12/30
118/118 [==============================] - 26s 217ms/step - loss: 0.4182 - accuracy: 0.8730 - val_loss: 0.2892 - val_accuracy: 0.8793 - lr: 5.0000e-04
Epoch 13/30
118/118 [==============================] - 24s 203ms/step - loss: 0.3533 - accuracy: 0.8965 - val_loss: 0.3292 - val_accuracy: 0.8707 - lr: 5.0000e-04
Epoch 14/30
118/118 [==============================] - ETA: 0s - loss: 0.3113 - accuracy: 0.9093
Epoch 14: ReduceLROnPlateau reducing learning rate to 0.0002500000118743628.
118/118 [==============================] - 25s 216ms/step - loss: 0.3113 - accuracy: 0.9093 - val_loss: 0.3788 - val_accuracy: 0.8448 - lr: 5.0000e-04
Epoch 15/30
118/118 [==============================] - 24s 205ms/step - loss: 0.2714 - accuracy: 0.9146 - val_loss: 0.2918 - val_accuracy: 0.8793 - lr: 2.5000e-04
Epoch 16/30
118/118 [==============================] - 28s 236ms/step - loss: 0.2520 - accuracy: 0.9264 - val_loss: 0.2720 - val_accuracy: 0.8966 - lr: 2.5000e-04
Epoch 17/30
118/118 [==============================] - 26s 223ms/step - loss: 0.2647 - accuracy: 0.9242 - val_loss: 0.3163 - val_accuracy: 0.8879 - lr: 2.5000e-04
Epoch 18/30
118/118 [==============================] - ETA: 0s - loss: 0.2045 - accuracy: 0.9402
Epoch 18: ReduceLROnPlateau reducing learning rate to 0.0001250000059371814.
118/118 [==============================] - 26s 218ms/step - loss: 0.2045 - accuracy: 0.9402 - val_loss: 0.2453 - val_accuracy: 0.8966 - lr: 2.5000e-04
Epoch 19/30
118/118 [==============================] - 26s 222ms/step - loss: 0.1866 - accuracy: 0.9477 - val_loss: 0.2465 - val_accuracy: 0.8966 - lr: 1.2500e-04
Epoch 20/30
118/118 [==============================] - ETA: 0s - loss: 0.1782 - accuracy: 0.9413
Epoch 20: ReduceLROnPlateau reducing learning rate to 6.25000029685907e-05.
118/118 [==============================] - 24s 203ms/step - loss: 0.1782 - accuracy: 0.9413 - val_loss: 0.2706 - val_accuracy: 0.8793 - lr: 1.2500e-04
Epoch 21/30
118/118 [==============================] - 25s 208ms/step - loss: 0.1486 - accuracy: 0.9498 - val_loss: 0.2947 - val_accuracy: 0.8879 - lr: 6.2500e-05
Epoch 22/30
118/118 [==============================] - ETA: 0s - loss: 0.1581 - accuracy: 0.9530
Epoch 22: ReduceLROnPlateau reducing learning rate to 3.125000148429535e-05.
118/118 [==============================] - 25s 212ms/step - loss: 0.1581 - accuracy: 0.9530 - val_loss: 0.2734 - val_accuracy: 0.8966 - lr: 6.2500e-05
Epoch 23/30
118/118 [==============================] - 25s 212ms/step - loss: 0.1403 - accuracy: 0.9541 - val_loss: 0.2923 - val_accuracy: 0.8966 - lr: 3.1250e-05
Epoch 24/30
118/118 [==============================] - 25s 210ms/step - loss: 0.1408 - accuracy: 0.9573 - val_loss: 0.2596 - val_accuracy: 0.9052 - lr: 3.1250e-05
Epoch 25/30
118/118 [==============================] - 26s 225ms/step - loss: 0.1420 - accuracy: 0.9584 - val_loss: 0.2862 - val_accuracy: 0.8966 - lr: 3.1250e-05
Epoch 26/30
118/118 [==============================] - ETA: 0s - loss: 0.1348 - accuracy: 0.9594
Epoch 26: ReduceLROnPlateau reducing learning rate to 1.5625000742147677e-05.
118/118 [==============================] - 27s 226ms/step - loss: 0.1348 - accuracy: 0.9594 - val_loss: 0.2690 - val_accuracy: 0.9052 - lr: 3.1250e-05
Epoch 27/30
118/118 [==============================] - 27s 227ms/step - loss: 0.1198 - accuracy: 0.9626 - val_loss: 0.2801 - val_accuracy: 0.9052 - lr: 1.5625e-05
Epoch 28/30
118/118 [==============================] - ETA: 0s - loss: 0.1396 - accuracy: 0.9520
Epoch 28: ReduceLROnPlateau reducing learning rate to 7.812500371073838e-06.
118/118 [==============================] - 26s 224ms/step - loss: 0.1396 - accuracy: 0.9520 - val_loss: 0.2825 - val_accuracy: 0.9052 - lr: 1.5625e-05
Epoch 29/30
118/118 [==============================] - 25s 213ms/step - loss: 0.1296 - accuracy: 0.9658 - val_loss: 0.2830 - val_accuracy: 0.9052 - lr: 7.8125e-06
Epoch 30/30
118/118 [==============================] - ETA: 0s - loss: 0.1255 - accuracy: 0.9605
Epoch 30: ReduceLROnPlateau reducing learning rate to 3.906250185536919e-06.
118/118 [==============================] - 26s 225ms/step - loss: 0.1255 - accuracy: 0.9605 - val_loss: 0.2876 - val_accuracy: 0.8966 - lr: 7.8125e-06
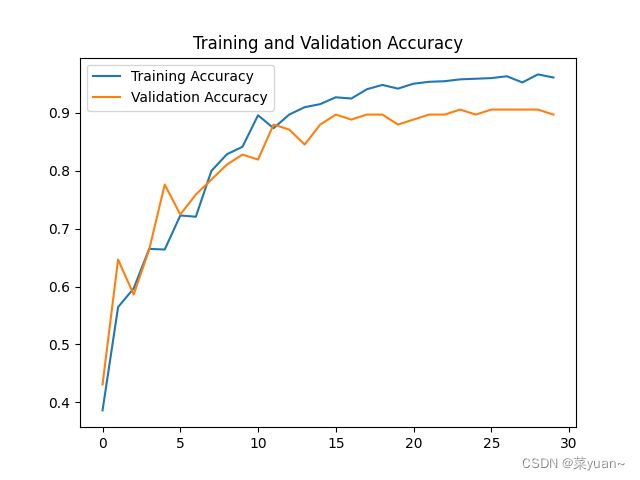
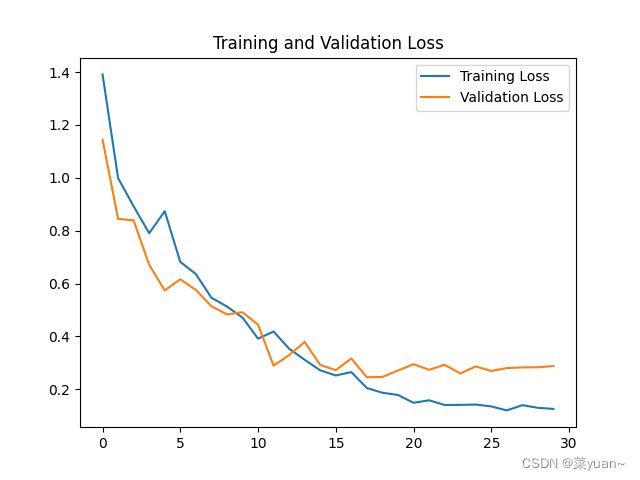
从以上结果可知,模型的准确率达到了90%,准确率还是很高的。
4. 完整代码
from keras.models import Sequential
from keras.layers import Dense, Conv2D, Flatten, Dropout, MaxPool2D
from keras import optimizers, losses
from keras.preprocessing.image import ImageDataGenerator
import sys, os # 目录结构
import matplotlib.pyplot as plt
from keras.callbacks import EarlyStopping, ReduceLROnPlateau
"1.模型建立"
# 1.卷积层,输入图片大小(96, 96, 3), 卷积核个数16,卷积核大小(5, 5), 激活函数'relu'
conv_layer1 = Conv2D(input_shape=(96, 96, 3), filters=16, kernel_size=(5, 5), activation='relu')
# 2.最大池化层,池化层大小(2, 2), 步长为2
max_pool1 = MaxPool2D(pool_size=(2, 2), strides=2)
# 3.卷积层,卷积核个数32,卷积核大小(5, 5), 激活函数'relu'
conv_layer2 = Conv2D(filters=32, kernel_size=(5, 5), activation='relu')
# 4.最大池化层,池化层大小(2, 2), 步长为2
max_pool2 = MaxPool2D(pool_size=(2, 2), strides=2)
# 5.卷积层,卷积核个数64,卷积核大小(5, 5), 激活函数'relu'
conv_layer3 = Conv2D(filters=64, kernel_size=(5, 5), activation='relu')
# 6.最大池化层,池化层大小(2, 2), 步长为2
max_pool3 = MaxPool2D(pool_size=(2, 2), strides=2)
# 7.卷积层,卷积核个数128,卷积核大小(5, 5), 激活函数'relu'
conv_layer4 = Conv2D(filters=128, kernel_size=(5, 5), activation='relu')
# 8.最大池化层,池化层大小(2, 2), 步长为2
max_pool4 = MaxPool2D(pool_size=(2, 2), strides=2)
# 9.展平层
flatten_layer = Flatten()
# 10.Dropout层, Dropout(0.2)
third_dropout = Dropout(0.2)
# 11.全连接层/隐藏层1,240个节点, 激活函数'relu'
hidden_layer1 = Dense(240, activation='relu')
# 12.全连接层/隐藏层2,84个节点, 激活函数'relu'
hidden_layer3 = Dense(84, activation='relu')
# 13.Dropout层, Dropout(0.2)
fif_dropout = Dropout(0.5)
# 14.输出层,输出节点个数5, 激活函数'softmax'
output_layer = Dense(5)
model = Sequential([conv_layer1, max_pool1, conv_layer2, max_pool2,
conv_layer3, max_pool3, conv_layer4, max_pool4,
flatten_layer, third_dropout, hidden_layer1,
hidden_layer3, fif_dropout, output_layer])
"2.模型编译"
# 模型编译,2分类:binary_crossentropy
model.compile(optimizer=optimizers.Adam(lr=1e-3),
loss=losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.summary() # 模型统计
# 回调机制 动态调整学习率
reduce = ReduceLROnPlateau(monitor='val_accuracy', # 设置监测的值为val_accuracy
patience=2, # 设置耐心容忍次数为2
verbose=1, #
factor=0.5, # 缩放学习率的值为0.5,学习率将以lr = lr*factor的形式被减少
min_lr=0.000001 # 学习率最小值0.000001
) # 监控val_accuracy增加趋势
# 生成器对象1: 归一化
gen = ImageDataGenerator(rescale=1 / 255.0)
# 生成器对象2: 归一化 + 数据加强
gen1 = ImageDataGenerator(
rescale=1 / 255.0,
rotation_range=5, # 图片随机旋转的角度5度
width_shift_range=0.1,
height_shift_range=0.1, # 水平和竖直方向随机移动0.1
shear_range=0.1, # 剪切变换的程度0.1
zoom_range=0.1, # 随机放大的程度0.1
fill_mode='nearest') # 当需要进行像素填充时选择最近的像素进行填充
# 拼接训练和验证的两个路径
train_path = os.path.join(sys.path[0], 'data', 'train')
val_path = os.path.join(sys.path[0], 'data', 'val')
print('训练数据路径: ', train_path)
print('验证数据路径: ', val_path)
# 训练和验证的两个迭代器
train_iter = gen1.flow_from_directory(train_path, # 训练train目录路径
target_size=(96, 96), # 目标图像大小统一尺寸96
batch_size=8, # 设置每次加载到内存的图像大小
class_mode='categorical', # 设置分类模型(默认one-hot编码)
shuffle=True) # 是否打乱
val_iter = gen.flow_from_directory(val_path, # 测试val目录路径
target_size=(96, 96), # 目标图像大小统一尺寸96
batch_size=8, # 设置每次加载到内存的图像大小
class_mode='categorical', # 设置分类模型(默认one-hot编码)
shuffle=True) # 是否打乱
"3.模型训练"
# 模型的训练, model.fit
result = model.fit(train_iter, # 设置训练数据的迭代器
epochs=30, # 循环次数30次
validation_data=val_iter, # 验证数据的迭代器
callbacks=[reduce], # 回调机制设置为reduce
validation_freq=1)
"4.模型保存"
# 保存训练好的模型
model.save('my_bkm.h5')
"5.模型训练时的可视化"
# 显示训练集和验证集的acc和loss曲线
acc = result.history['accuracy'] # 获取模型训练中的accuracy
val_acc = result.history['val_accuracy'] # 获取模型训练中的val_accuracy
loss = result.history['loss'] # 获取模型训练中的loss
val_loss = result.history['val_loss'] # 获取模型训练中的val_loss
# 绘值acc曲线
plt.figure(1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.savefig('my_bkm_acc.png', dpi=600)
# 绘制loss曲线
plt.figure(2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.savefig('my_bkm_loss.png', dpi=600)
plt.show() # 将结果显示出来
5. 宝可梦的迁移学习
from tensorflow import keras
from keras.models import Sequential
from keras.layers import Dense, Conv2D, Flatten, Dropout, MaxPool2D, BatchNormalization
from keras import optimizers, losses
from keras.preprocessing.image import ImageDataGenerator
import sys, os # 目录结构
import matplotlib.pyplot as plt
from keras.callbacks import EarlyStopping, ReduceLROnPlateau
"1.模型建立"
net = keras.applications.DenseNet121(weights='imagenet', include_top=False,
pooling='max') # 这里使用了自带的DenseNet121网络 你也可以用keras.Sequential DIY模型
net.trainable = False
cnn_net = keras.Sequential([
net,
Dense(1024, activation='relu'),
BatchNormalization(), # BN层 标准化数据
Dropout(rate=0.2),
Dense(5)])
# 其要进行转换为array矩阵,其实际格式是(batch,height,width,C)
cnn_net.build(input_shape=(None, 96, 96, 3))
cnn_net.summary()
# 回调机制
reduce = ReduceLROnPlateau(monitor='val_accuracy', # 设置监测的值为val_accuracy
patience=2, # 设置耐心容忍次数为2
verbose=1, #
factor=0.5, # 缩放学习率的值为0.5,学习率将以lr = lr*factor的形式被减少
min_lr=0.000001 # 学习率最小值0.000001
) # 监控val_accuracy增加趋势
"2.模型编译"
cnn_net.compile(optimizer=optimizers.Adam(lr=1e-3),
loss=losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
# 生成器对象1: 归一化
gen = ImageDataGenerator(rescale=1 / 255.0)
# 生成器对象2: 归一化 + 数据加强
gen1 = ImageDataGenerator(
rescale=1 / 255.0,
rotation_range=5, # 图片随机旋转的角度5度
width_shift_range=0.1,
height_shift_range=0.1, # 水平和竖直方向随机移动0.1
shear_range=0.1, # 剪切变换的程度0.1
zoom_range=0.1, # 随机放大的程度0.1
fill_mode='nearest') # 当需要进行像素填充时选择最近的像素进行填充
# 拼接训练和验证的两个路径
train_path = os.path.join(sys.path[0], 'data', 'train')
val_path = os.path.join(sys.path[0], 'data', 'val')
print('训练数据路径: ', train_path)
print('验证数据路径: ', val_path)
# 训练和验证的两个迭代器
train_iter = gen1.flow_from_directory(train_path, # 训练train目录路径
target_size=(96, 96), # 目标图像大小统一尺寸96
batch_size=8, # 设置每次加载到内存的图像大小
class_mode='categorical', # 设置分类模型(默认one-hot编码)
shuffle=True) # 是否打乱
val_iter = gen.flow_from_directory(val_path, # 测试val目录路径
target_size=(96, 96), # 目标图像大小统一尺寸96
batch_size=8, # 设置每次加载到内存的图像大小
class_mode='categorical', # 设置分类模型(默认one-hot编码)
shuffle=True) # 是否打乱
"3.模型训练"
# 模型的训练, model.fit
result = cnn_net.fit(train_iter, # 设置训练数据的迭代器
epochs=10, # 循环次数10次
validation_data=val_iter, # 验证数据的迭代器
callbacks=[reduce], # 回调机制设置为reduce
validation_freq=1)
"4.模型保存"
# 保存训练好的模型
cnn_net.save('my_bkm_2.h5')
"5.模型训练时的可视化"
# 显示训练集和验证集的acc和loss曲线
acc = result.history['accuracy'] # 获取模型训练中的accuracy
val_acc = result.history['val_accuracy'] # 获取模型训练中的val_accuracy
loss = result.history['loss'] # 获取模型训练中的loss
val_loss = result.history['val_loss'] # 获取模型训练中的val_loss
# 绘值acc曲线
plt.figure(1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.savefig('my_bkm_acc_2.png', dpi=600)
# 绘制loss曲线
plt.figure(2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.savefig('my_bkm_loss_2.png', dpi=600)
plt.show() # 将结果显示出来

