Mysql存储层优化整理总结
存储层优化主要包括:“存储引擎”选取、字段类型选取、三范式与逆范式等。
目录
一、存储引擎简介:
二、常用的存储引擎:
Myisam:
数据文件:
数据存储:
并发性:
数据压缩(压缩后只能进行“查”操作,不能进行“增、删、改”操作):
数据解压缩:
Innodb:
数据文件:
共享“数据、索引”文件:
数据存储:
并发性:
Myisam和Innodb对比:
Memory:
Archive:
三、字段类型的选取规则
因字段来表结构拆分:
① 定长与变长分离:
②常用字段和不常用字段要分离:
一定要选取占据空间小的字段:
优先选择运行速度快的字段:
varchar(M):
char(M):
varchar与char的对比:
其他各字段比较:
①字段类型优先级:
②列的特点分析:
③ 够用就行,不要慷慨 (如smallint,varchar(M)):
④ 尽量避免用NULL
⑤Enum列的具体说明
优先整型存储:
①把时间信息都变为整型的进行存储:
②使用集合、枚举类型:
③ip地址也可以转换为整型存储:
四、三范式与逆范式
三范式三条规则:
逆范式:
一、存储引擎简介:
存储数据的格式,就是存储引擎。存储数据的格式不一样,体现的特性也不一样,实际项目需要根据业务要求选取适当的存储引擎。
二、常用的存储引擎:
查看存储引擎"show engines;":

① Myisam:特性有表锁,全文索引等。
② Innodb:特性有事务,行(记录)锁,外键等。
③ Memory:特性有内存存储引擎,速度快、数据容易丢失等。
Myisam:
数据文件:
每个“Myisam存储引擎”数据表有三个文件组成:结构文件(*.frm)、索引文件(*.MYI)、数据文件(*.MYD)。
创建一个Myisam存储引擎数据表:

在硬盘中查看该数据表的组成文件:
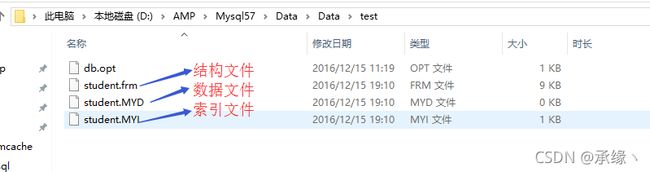
三个组成文件支持物理的“复制/粘贴”操作以实现数据的备份/还原操作。
数据存储:
数据不按照主键大小顺序进行写入存储,从而数据写入速度非常快:
主键没有大小顺序写4条记录

查看写入的数据:

并发性:
并发性(在短时间之内多人对该数据表进行操作),此引擎的不是很好。其锁机制为“表锁”,同时操作其他记录有影响。
数据压缩(压缩后只能进行“查”操作,不能进行“增、删、改”操作):
适用于压缩数据不频繁发生变化的数据,例如全国的地区信息等。
Myisam引擎的数据表如果存储的数据非常多,会导致操作数据比较慢,占据大量硬盘空间此时我们可以使用对数据表进行压缩来解决。
首先可以将一张表的内存中的数据刷新到磁盘中:flush table xxx;
例如此时查看一张数据表文件大小为150MB+:
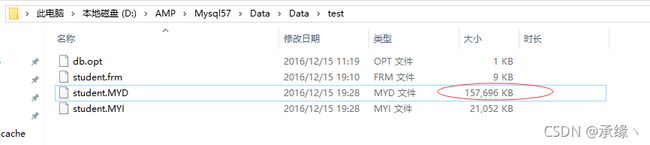
使用Mysql自带的压缩工具:myisampack.exe 表名;:
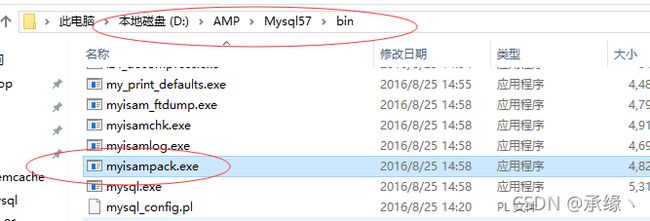

压缩之后,最好再flush一下表,把数据表给更新下,内存和硬盘同步数据。

查看压缩后数据文件的大小:

接下来需要重建索引,myisamchk.exe -rq 表名;:


再更新表:

此时索引文件也会更新:

Myisam数据表的压缩,是更底层的一个技术实现,底层压缩,会影响正常使用,只能进行“读”操作,不能进行”写(增/删/改)”操作。


数据解压缩:
想要再次操作需要将上一步压缩的数据表进行解压缩myisamchk.exe --unpack 表名:
解压缩不需要再手动重建索引,因为索引会自动重建。


Innodb:
数据文件:
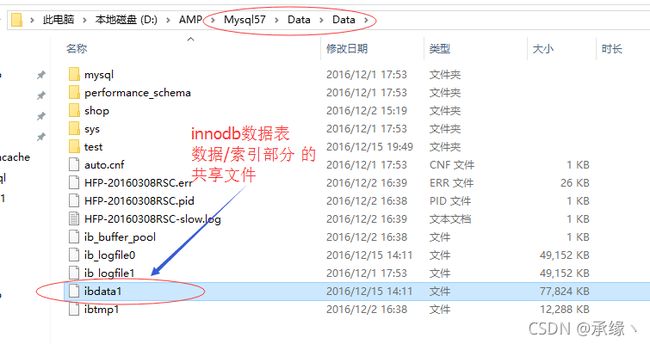
Innodb数据表的组成与Myisam有所不同,数据部分和索引部分共用一个文件(*.ibd或ibdata1)。
一个innodb数据表根据数据库版本不同,默认组成文件不一样:
mysql57:版本默认:是一个*.frm结构文件、一个数据/索引文件*.ibd。(每个innodb数据表有独立的*.ibd文件)。
mysql55:版本默认:是一个*.frm结构文件、一个大的数据/索引文件ibdata1。(数据库全部的innodb数据表共享一个ibdata1文件,该ibdata1文件汇总全部的数据/索引内容)。
*.ibd:每个innodb数据表的”数据/索引”文件名称,每个数据表都有一个。
ibdata1:数据库中全部的innodb”数据/索引内容”汇总文件(该文件如果处理不当,会影响数据库中全部innodb数据表的正常使用,相对不太安全)。
系统里边有全局变量可以针对*.ibd和ibdata1进行设置。
创建一个innodb引擎的数据表:

文件组成如下:
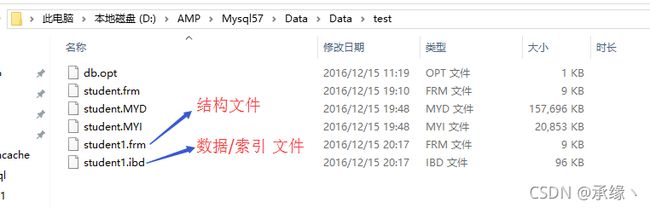
innodb数据表不能直接进行文件的复制/粘贴进行备份还原,如上图的frm和ibd文件不支持直接复制/粘贴操作实现数据备份/还原。但是可以使用如下指令达成相同目的:
备份:
mysqldump -uroot -p密码 数据库名字 > /backup.sql
还原:
mysql -uroot -p密码 数据库 < /backup.sql
共享“数据、索引”文件:
mysql5.7版本对创建的每个innodb数据表的数据/索引文件都实现独立存储,为*.ibd,使得每个数据表相对都比较安全。
不推荐:如果想要数据库中全部的innodb数据表的 数据/索引部分 共享一个文件ibdata1,可以通过如下方式设置
> show variables like ‘innodb_file_per_table%’; //查看
> set global innodb_file_per_table=1; //数据/索引部分 设置独立文件
> set global innodb_file_per_table=0; //数据/索引部分 设置共享文件
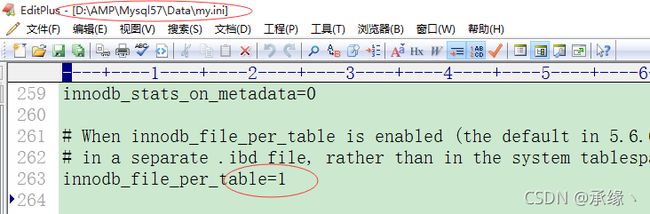
(innodb_file_per_table全局变量也可以在my.ini中修改,使得永久生效)
修改全局变量,使得全部innodb数据表的数据/索引内容共享一个ibdata1文件:


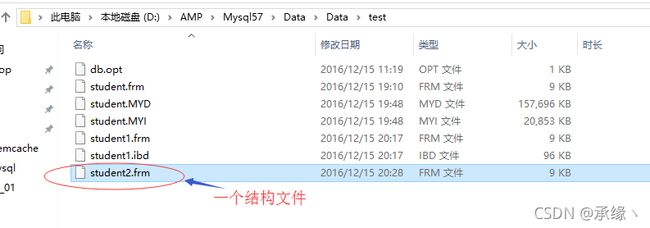

也可以修改mysql配置文件my.ini,然后重启mysql使得全局变量永久生效:
数据存储:
给innodb引擎的数据表写入数据时候,数据会根据主键大小按顺序进行存储,速度上逊于Myisam:

查询发现:

并发性:
比较好,并发性高,多人同时请求,速度快、效率高。
锁机制:行锁,每次只锁住一条记录信息。
Myisam和Innodb对比:
myisam: 写入数据非常快,适合使用场合dedecms、discuz、微博系统等写入、读取操作多的系统。
innodb: 适合业务逻辑比较强的系统,修改操作较多的,例如crm、办公系统、商城系统等。
Memory:
内存存储引擎:
特点:内部数据运行速度非常快,临时存储一些信息
缺点:服务器如果断电,就会清空该存储引擎的全部数据
Archive:
文档存储引擎,类似myisam存储引擎。一般适合存储日志性质的数据信息,因为不需要考虑信息的前后关系所以数据写入速度比较快。
三、字段类型的选取规则
因字段来表结构拆分:
拆分表结构,如核心字段都用int,char,enum等定长结构。非核心字段,或用到text,超长的varchar,拆出来单放一张表。
① 定长与变长分离:
如 id int,占4个字节; char(4) 占4个字符长度,也是定长,即每一单元值占的字节是固定的。
核心且常用字段,宜建成定长,放在一张表。
而varchar,text,blob这种变长字段,适合单放一张表,用主键与核心表关联起来。
②常用字段和不常用字段要分离:
需要结合具体业务来分析,分析字段的查询场景,,查询频度低的字段,单拆出来。
一定要选取占据空间小的字段:
例如下面的int型:

人的年龄适合使用tinyint类型,乌龟的年龄使用smallint类型。数据表主键id值在没有超过1600万的时候,就可以使用无符号mediumint类型。
优先选择运行速度快的字段:
varchar(M):
M取值范围1-21844字符 (65535字节空间大小)。
字母或数字都占据1个字节,最多可以存储65535-2=65533个(需要留两个字节存储内容的长度)。
utf-8字符集的汉字,每个汉字占据3个字节,最多可以存储65535/3=21845-1=21844个汉字(理论值,实际没有这么多)(21845-1作用是留下一个位置存储汉字内容的长度)。
gbk字符集汉字(每个汉字占据2个字节)最多可以存储65535/2=32767.5-1=32766个(留下一个字符存储汉字长度)。
char(M):
M取值范围1-255字符。
每个字母、数字或汉字都占据一个字符,理论上每种数字、字母或汉字最多可以存储255个。
每个汉字(utf-8字符集)占据3个字节,理论上最对可以存储255个(实际测试可以存储253个)。
varchar与char的对比:
char() 的运行速度快 ,例如char(20) 实际存储16个字符,分配20个字符空间。
varchar()运行速度稍慢,例如varchar(20) 实际存储16个字符,分配16个字符空间。
char类型不给计算内容长度,把所有空间都进行分配。速度快,浪费空间。
varchar类型给计算内容长度,根据内容长度适当分配空间。速度慢,节省空间。
内容长度固定,就选取char类型,例如存储手机号码:char(11)。
内容长度不固定,就选取varchar类型,类型存储邮箱:varchar(64)。
如果单纯追求速度,就可以选取char类型的。
其他各字段比较:
①字段类型优先级:
整型 > date,time > enum,char > varchar > blob
②列的特点分析:
整型:定长,没有国家/地区之分,没有字符集的差异。
time:定长,运算快,节省空间。但是考虑考虑时区。
enum:能起来约束值的目的,内部用整型来存储,但与char联查时内部要经历串与值的转化。
char:定长,需要考虑字符集和(排序)校对集。
varchar:不定长,要考虑字符集的转换与排序时的校对集,速度较慢。
text/Blob:不定长,将导致查询等过程中无法使用内存临时表。
性别: 以utf8为例:
char(1),3个字长字节。
enum(‘男’,’女’); // 内部转成数字来存,多了一个转换过程。
tinyint() ,// 0 1 2 // 定长1个字节。
③ 够用就行,不要慷慨 (如smallint,varchar(M)):
原因: 大的字段浪费内存,影响速度。
以年龄为例 tinyint: unsigned not null,可以存储255岁,足够用了,如果使用int则浪费了3个字节。
其实如果varchar(10),varchar(300)存储的内容相同,但在表联查时,varchar(300)要花更多内存。
④ 尽量避免用NULL
NULL不利于索引,要用特殊的字节来标注。且它在磁盘上占据的空间其实更大。
例如:
建立两张字段相同的表,一个允许为Null,一个不允许为Null,各insert进1万条数据,查看索引文件的大小。可以发现:
为Null的索引要大些(在mysql5.5里,关于Null已经做了优化,大小区别已不明显),另外Null也不便于查询。
⑤Enum列的具体说明
enum列在内部是用整型来储存的。
enum列与enum列相关联速度最快。
enum列比(var)char 的弱势是在碰到与char关联时要转化,降低效率,速度要比enum->enum,char->char要慢。但有时也会这样用,在数据量特别大时,可以节省IO。
enum列比(var)char 的优势在于,无论enum(‘fldahfjhs’,’fftedfsga’)枚举的字符多长,内部都是用整型表示,在内存中产生的数据大小不变,而char型,却在内存中产生的数据越来越多,当查询的数据量越大时,enum的优势会越明显。
优先整型存储:
占据空间小、运行速度快,所以可以设法将数据存储为整型。
①把时间信息都变为整型的进行存储:
②使用集合、枚举类型:
他们底层内部使用的整型进行存储。
集合(多选):set(‘篮球1’,’排球2’,’足球4’,’棒球8’) 篮球,足球,棒球(13)
枚举(单选):enum(‘男1’,’女2’,’保密3’) 男 1
③ip地址也可以转换为整型存储:

四、三范式与逆范式
三范式三条规则:
① 字段的原子性,是唯一的,不能再拆分。
② 数据表每条记录都有一个主键,用于彼此区分。
③ 与数据库的冗余有关。一个表不能包含其他表的非关键字信息。也就是说你有其他表的主键作为自己的外键,就不能再拿其他字段。

逆范式:
一般设计 数据库/表 的时候要遵守数据库的三范式,但是有的时候处于综合方面的考虑,过于遵守三范式倒不利于项目的开发和维护,那么在这些地方就不要严格遵守三范式,不遵守三范式的行为就是逆范式。
例如:
在ecshop数据库中有两个数据表
分类表:
ecs_category :cat_id cat_name ...
商品表:
ecs_goods
:goods_id goods_name cat_id ...
需求:查询每个分类下商品的总数量是多少(内容:cat_id,cat_name,count)select c.cat_id,c.cat_name,count(g.goods_id) from ecs_goods g join ecs_category c on g.cat_id=c.cat_id group by c.cat_id

以上sql语句为了实现需求,需要做一个join的联合两个数据表的执行查询
(通常意义上,单表查询速度要明显快于join联表查询,并且单表查询消耗的资源更少)
如果系统里边类似上边这样的需求有很多,则join联表查询 要消耗很多资源。
现在做一个逆范式的设计,使得join联表查询可以变为单表查询
具体设计:
给ecs_category 数据表增加一个字段:
ecs_category: cat_id cat_name goods_count(商品数量/冗余字段)
需求:查询每个分类下商品的总数量是多少(内容:cat_id,cat_name,count)
SQL语句:select cat_id,cat_name,goods_count from ecs_category
以后商品的每次增加、减少都需要对goods_count进行维护。