Yarn WebUI使用各指标详解
转载专用:
读到了好文章,用于分享收藏,侵权删。
转发自大佬:大Null,http://program-park.top/2022/02/10/hadoop_38/目录
前言
1.WebUI V1使用指南
1.1 首页
1.2 应用程序分析
2. HistoryServer服务
2.1 JobHistoryServer管理MR应用
2.1.1 提交MR应用程序
2.1.2 MR运行历史信息
2.1.3 JobHistoryServer运行流程
2.2 JobHistoryServer WebUI
2.2.1首页
2.2.2 JobHistoryServer构建说明
2.2.3 MR应用程序查看
2.2.4 JobHistoryServer配置
2.2.5 JobHistoryServer本地日志
2.2.6 JobHistoryServer堆栈信息
3. TimelineServer服务
3.1 启用Timeline服务
3.2 启动Timeline服务
前言
YARN 提供 WEB UI 服务,在 Hadoop 2.9.0 版本中,提供新 WebUI V2 服务,可提供对运行在 YARN 框架上的应用程序的可视化。
1.WebUI V1使用指南
与 HDFS 一样,YARN 也提供了一个 WebUI 服务,可以使用 YARN Web 用户界面监视群集、队列、应用程序、服务、流活动和节点信息。还可以查看集群详细配置的信息,检查各种应用程序和服务的日志。
1.1 首页
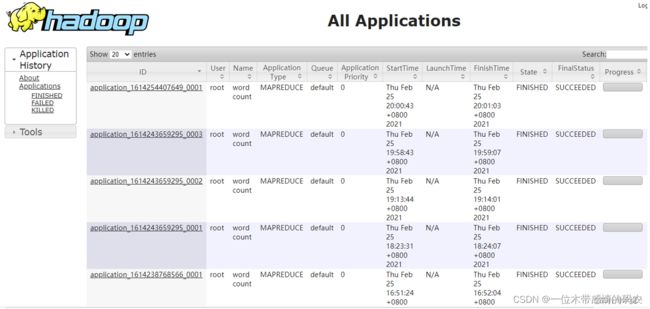
浏览器输入http://hadoop2:8088/访问 YARN WebUI 服务,华为MRS则是通过FI跳转,页面打开后,以列表形式展示已经运行完成的各种应用程序,如 MapReduce 应用、Spark 应用、Flink 应用等,与点击页面左侧 Application 栏目红线框 Applications 链接显示的内容一致。

1.2 应用程序分析
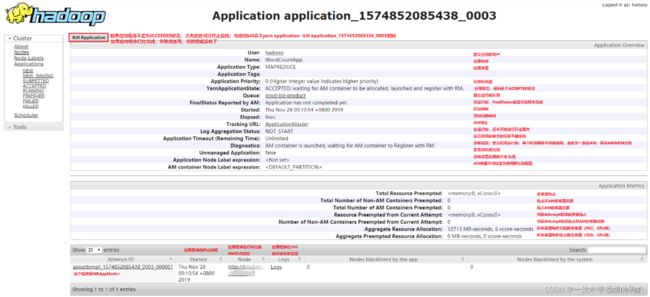
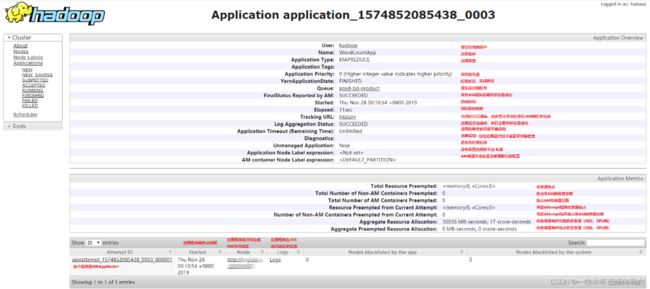
当点击任意一个应用程序时,会打开一个新页面,并展示这个应用程序的运行信息。以 MR 应用为例,如果应用程序正在运行,打开的页面如下图所示;如果应用程序已经运行完成,打开的页面如下图所示。
- ①正在运行的MR应用程序
②运行完成的MR应用程序
2. HistoryServer服务
YARN 中提供了一个叫做 JobHistoryServer 的守护进程,它属于 YARN 集群的一项系统服务,仅存储已经运行完成的 MapReduce 应用程序的作业历史信息,并不会存储其他类型(如Spark、Flink等)应用程序的作业历史信息。
- 当启用 JobHistoryServer 服务时,仍需要开启日志聚合功能,否则每个 Container 的运行日志是存储在 NodeManager 节点本地,查看日志时需要访问各个 NodeManager 节点,不利于统一管理和分析。
- 当开启日志聚合功能后 AM 会自动收集每个 Container 的日志,并在应用程序完成后将这些日志移动到文件系统,例如 HDFS。然后通过 JHS 的 WebUI 服务来提供用户使用和应用恢复。
2.1 JobHistoryServer管理MR应用
当提交运行 MapReduce 程序在 YARN 上运行完成以后,将应用运行日志数据上传到 HDFS 上,此时 JobHistoryServer 服务可以从 HDFS 上读取运行信息,在 WebUI 进行展示,具体流程如下。
2.1.1 提交MR应用程序
使用 yarn jar 提交运行官方自带词频统计 WordCount 程序到 YARN 上运行,命令如下:
yarn jar .../hadoop-3.3.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /input /output
2.1.2 MR运行历史信息
MR 应用程序在运行时,是通过 AM(MRAppMaster 类)将日志写到 HDFS 中,会生成.jhist、.summary和_conf.xml文件。其中.jhist文件是 MR 程序的计数信息,.summary文件是作业的摘要信息,_conf.xml文件是 MR 程序的配置信息。
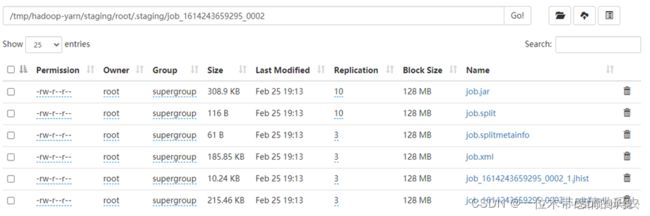
- MR应用程序启动时的资源信息
MR应用程序启动时,会把作业信息存储到${yarn.app.mapreduce.am.staging-dir}/${user}/.staging/${job_id}目录下。
yarn.app.mapreduce.am.staging-dir:/tmp/hadoop-yarn/staging(默认)
- MR应用程序运行完成时生成的信息
MR应用程序运行完成后,作业信息会被临时移动到${mapreduce.jobhistory.intermediate-done-dir}/${user}目录下。
mapreduce.jobhistory.intermediate-done-dir:/mr-history/intermediate(配置)
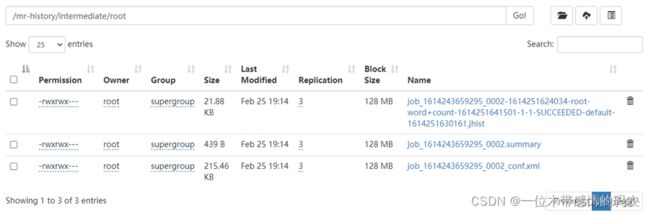
- MR应用程序最终的作业信息
等待${mapreduce.jobhistory.move.interval-ms}配置项的值(默认 180000 毫秒= 3 分钟)后,会把${mapreduce.jobhistory.intermediate-done-dir}/${user}下的作业数据移动到${mapreduce.jobhistory.done-dir}/${year}/${month}/${day}/${serialPart}目录下。此时.summary文件会被删除,因为.jhist文件提供了更详细的作业历史信息。
JHS 服务中的作业历史信息不是永久存储的,在默认情况下,作业历史清理程序默认按照 86400000 毫秒(一天)的频率去检查要删除的文件,只有在文件早于mapreduce.jobhistory.max-age-ms(一天)时才进行删除。JHS 的历史文件的移动和删除操作由 HistoryFileManager 类完成。
mapreduce.jobhistory.intermediate-done-dir:/mr-history/intermediate(配置)
mapreduce.jobhistory.intermediate-done-dir:/mr-history/done(配置)
mapreduce.jobhistory.cleaner.enable: true(默认) mapreduce.jobhistory.cleaner.interval-ms:
86400000(1天) mapreduce.jobhistory.max-age-ms: 86400000(1天)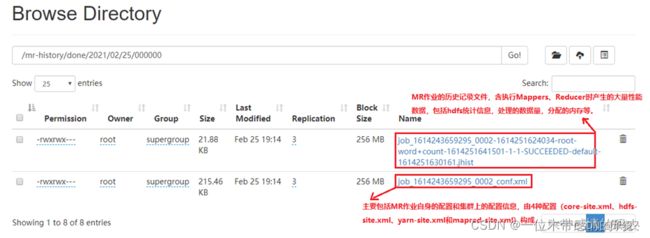
2.1.3 JobHistoryServer运行流程
- 客户端提交 MR 应用程序到 RM;
- 在/tmp/logs/
/logs/application_timestamp_xxxx 中创建应用程序文件夹; - MR 作业在群集上的 YARN 中运行;
- MR 作业完成,在提交作业的作业客户上报告作业计数器;
- 将计数器信息(.jhist文件)和job_conf.xml文件写入/user/history/done_intermediate/
/job_timestamp_xxxx - 然后将.jist文件和job_conf.xml从/user/history/done_intermediate/
/ 移动到/user/history/done目录下; - 来自每个 NM 的 Container 日志汇总到/tmp/logs/<用户ID>/logs/application_timestamp_xxxx;
2.2 JobHistoryServer WebUI
JobHistoryServer 服务 WebUI 界面相关说明:
2.2.1首页
浏览器输入:http://hadoop1:19888 访问 JHS 服务,页面打开后,以列表形式展示已经运行完成的 MR 应用程序,与点击页面左侧 Application 栏目红线框 jobs 链接显示的内容一致。
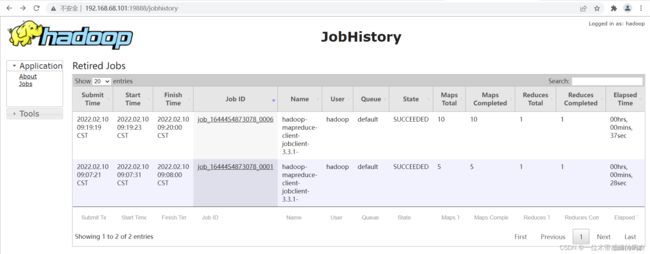
2.2.2 JobHistoryServer构建说明
浏览器输入 http://hadoop1:19888/jobhistory/about 地址或者在点击页面左侧 Application 栏目下红线框 about 链接后会展示 JHS 服务的构建版本信息和启动时间。

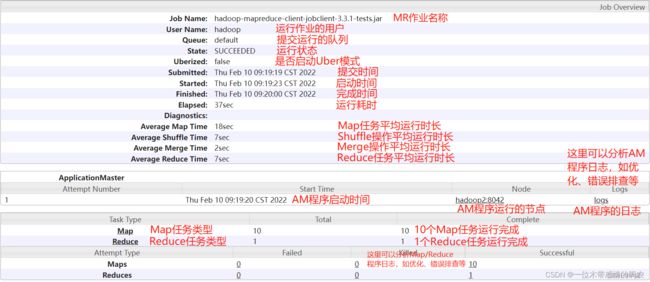
2.2.3 MR应用程序查看
在 JHS 作业列表点击任意一个作业:
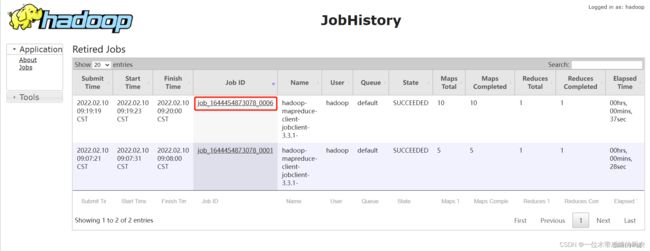
作业信息查看:
2.2.4 JobHistoryServer配置
浏览器输入 http://hadoop1:19888/conf 或点击页面左侧 Tools 栏目中的红线框 configuration 链接会打开 JHS 的所需配置页面,在配置页面中,主要有集群自定义配置(core-site.xml、hdfs-site.xml、yarn-site.xml和mapred-site.xml)和集群默认配置(core-default.xml、hdfs-default.xml、yarn-default.xml和mapred-default.xml)两种。
2.2.5 JobHistoryServer本地日志
浏览器输入 http://hadoop1:19888/logs/ 地址或点击页面左侧 Tools 栏目中的红线框 local logs 链接会打开 JHS 服务的所在节点的 log 文件列表页面。
2.2.6 JobHistoryServer堆栈信息
浏览器输入 http://hadoop1:19888/stacks 地址或点击页面左侧 Tools 栏目中的红线框 Server stacks 链接会打开 JHS 服务的堆栈转储信息。stacks 功能会统计 JHS 服务的后台线程数、每个线程的运行状态和详情。这些线程有 MoveIntermediateToDone 线程、JHS 的 10020 RPC 线程、JHS 的 10033 Admin 接口线程、HDFS 的
StatisticsDataReferenceCleaner 线程、JHS 服务度量系统的计时器线程、DN 的 Socket 输入流缓存线程和 JvmPauseMonitor 线程等。

3. TimelineServer服务
由于Job History Server仅对MapReduce应用程序提供历史信息支持,其他应用程序的历史信息需要分别提供单独的HistoryServer才能查询和检索。例如 Spark 的 Application 需要通过 Spark 自己提供的org.apache.spark.deploy.history.HistoryServer来解决应用历史信息。
为了解决这个问题,YARN 新增了Timeline Server组件,以通用的方式存储和检索应用程序当前和历史信息。
到目前,有 V1、V1.5 和 V2 共三个版本,V1 仅限于写入器/读取器和存储的单个实例,无法很好地扩展到小型群集之外;V2 还处于 alpha 状态,所以这里以 V1.5 进行讲解。
| 版本 |
说明 |
| V1 |
基于LevelDB实现。 |
| V1.5 |
在V1的基础上改进了扩展性。 |
| V2 |
1.使用更具扩展性的分布式写入器体系结构和可扩展的后端存储。 2.将数据的收集(写入)与数据的提供(读取)分开。它使用分布式收集器,每个YARN应用程序实质上是一个收集器。读取器是专用于通过REST API服务查询的单独实例。 3.使用HBase作为主要的后备存储,因为Apache HBase可以很好地扩展到较大的大小,同时保持良好的读写响应时间。 4.支持在流级别汇总指标。 |
Timeline Server是YARN的一个重要组件,用于收集和存储应用程序运行过程中产生的事件和元数据信息,而不仅针对Spark任务。它支持各种类型的事件和元数据,包括作业提交、任务开始、任务结束等,同时也支持自定义事件和属性。因此,Timeline Server不仅适用于Spark应用程序,也适用于其他类型的应用程序,如MapReduce、Tez、Spark Streaming等。
TimelineServer功能更强大,可以记录第三方计算引擎的记录,但不是替代JobHistoryServer。两者是功能间的互补关系。
官方文档:
Apache Hadoop 3.1.4 – The YARN Timeline Server
Apache Hadoop 3.1.4 – The YARN Timeline Service v.2
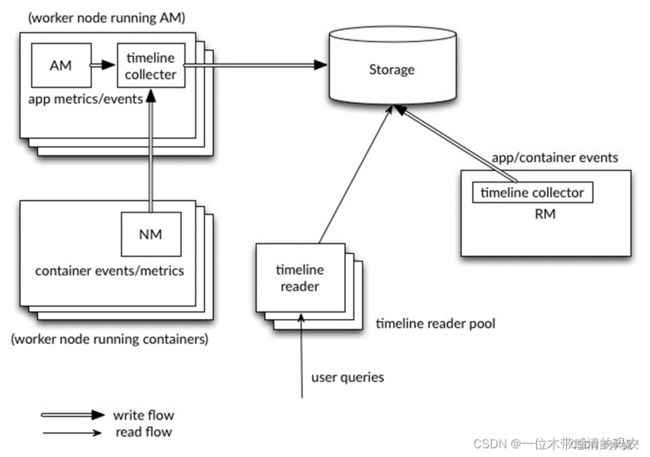
YARN Timeline Service v.2 服务架构图如下:
3.1 启用Timeline服务
在yarn-site.xml配置文件中添加如下属性,启动 Timeline Server 服务功能:
yarn.timeline-service.enabled
true
yarn.timeline-service.hostname
192.168.68.102
设置YARN Timeline服务地址
yarn.timeline-service.address
192.168.68.102:10200
设置YARN Timeline服务启动RPC服务器的地址,默认端口10200
yarn.timeline-service.webapp.address
192.168.68.102:8188
设置YARN Timeline服务WebUI地址
yarn.resourcemanager.system-metrics-publisher.enabled
true
设置RM是否发布信息到Timeline服务器
yarn.timeline-service.generic-application-history.enabled
true
设置是否Timelinehistory-servic中获取常规信息,如果为否,则是通过RM获取
同步yarn-site.xml文件到集群其他机器,并重启 YARN 服务。
3.2 启动Timeline服务
在上述配置中指定的 Timeline 服务位于hadoop2节点上,需要在hadoop2节点的 shell 客户端中启动,如果在非hadoop2节点上启动时会报错。
启动命令如下:yarn --daemon start timelineserver
在浏览器中输入:http://192.168.68.102:8188/applicationhistory