【十万字的SpringCloud,你不来看看】
黑马笔记
目录
微服务和springcloud介绍
【1】服务集群
【2】技术导览
【3】认识微服务
1、单体架构
2、分布式架构
3、微服务是什么 解决分布式架构的缺点
【4】国内知名微服务治理SpringCloud 阿里巴巴Dubbo
【5】SpringCloud
【6】服务拆分和远程调用
【7】微服务中 提供者和消费者
Eureka 服务注册和发现
【1】介绍
【2】实践
【3】服务注册
1)引入依赖
2)配置文件
【3】服务发现
1)引入依赖
2)配置文件
3)服务拉取和负载均衡
Ribbon 负载均衡
【1】介绍
【2】Ribbon负载均衡实现 irule
【3】Ribbon饥饿加载
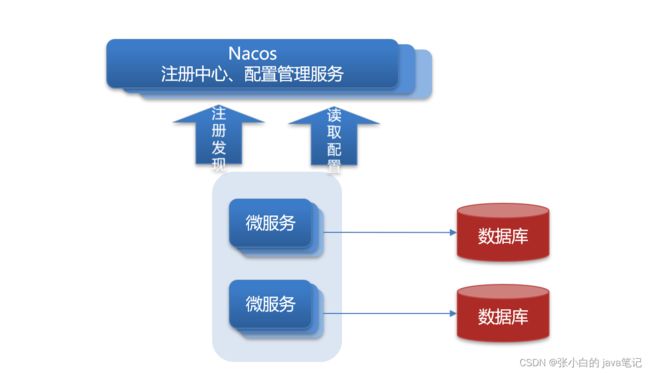
NACOS阿里巴巴注册中心
【1】介绍
【2】入门使用
服务多级存储模型
【3】Nacos的rule负载均衡
权重修改
【4】环境隔离——namespace
【5】Nacos和Eureka的区别
【6】Nacos配置管理
实现热更新
1.2.1.方式一
1.2.2.方式二
【7】多环境的配置 实现开发测试环境都一样
Feign远程调用
【1】Feign替代RestTemplate
3)编写Feign的客户端
2.2.1.配置文件方式
【2】Feign使用优化
【3】最佳实践 (公司得到的结果)
gateway:网关
【1】介绍
【2】网关入门
2)编写启动类
3)编写基础配置和路由规则
4)重启测试
【3】断言工厂
【4】过滤器工厂
3.4.2.请求头过滤器
3.4.3.默认过滤器
【5】全局过滤器GlobalFilter
【6】过滤器执行顺序
编辑
跨域问题解决
Hystrix 断路
【1】介绍
【2】服务降级
————————————————jemeter压测 20000线程
1、消费者处理降级
2、全局降级
【3】服务熔断
【4】服务监控
config 分布式配置中心
Docker
【1】介绍
【2】虚拟机和docker
【3】 docker架构 : 镜像和容器
【4】docker架构:DockerHub
【5】Docker 安装
0.安装Docker
1.CentOS安装Docker
1.1.卸载(可选)
1.2.安装docker
1.3.启动docker
1.4.配置镜像加速
【6】镜像操作
2.1.3.案例1-拉取、查看镜像
2.1.4.案例2-保存、导入镜像
【6】容器相关命令
【案例】进入容器 修改
【案例】redis容器
【7】挂载 ——不在容器里面更改数据((数据卷 数据管理
需求:创建一个数据卷,并查看数据卷在宿主机的目录位置
挂载容器文件
2.3.5.案例-给nginx挂载数据卷
【8】直接挂载到宿主机
【9】Docker自定义镜像
【10】如何构建Dockerfile语法
3.3.1.基于Ubuntu构建Java项目
3.3.2.基于java8构建Java项目
3.4.小结
【10】.Docker-Compose
4.1.初识DockerCompose
4.2.安装DockerCompose
4.3.部署微服务集群
4.3.1.compose文件
4.3.2.修改微服务配置
4.3.3.打包
4.3.4.拷贝jar包到部署目录
4.3.5.部署
【11】Docker镜像仓库
5.1.搭建私有镜像仓库
5.2.推送、拉取镜像
MQ 消息队列
【1】同步调用
【2】异步调用
【3】多种MQ技术对比:
【4】快速入门
2.1.安装RabbitMQ
RabbitMQ中的一些角色:
常见消息模型编辑
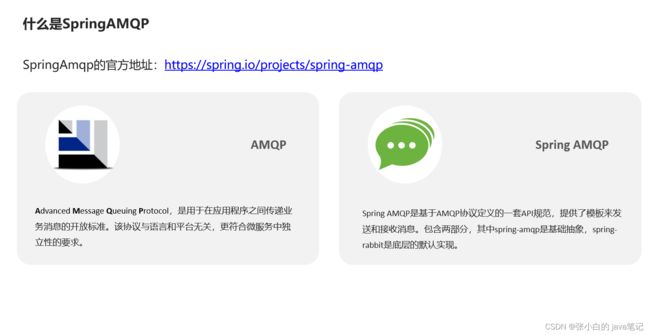
SpringAMQP
微服务和springcloud介绍
微服务是一种整体架构
SpringCloud使解决服务之间的调用
【1】服务集群

【2】技术导览
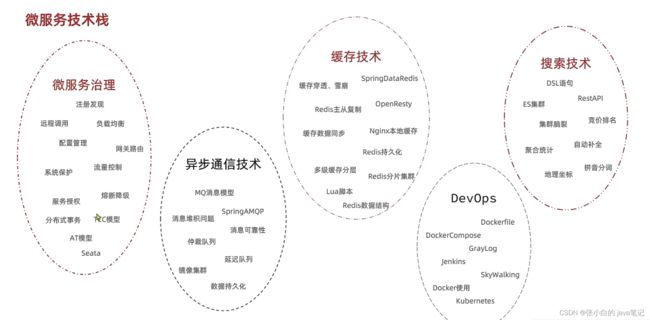

【3】认识微服务
1、单体架构
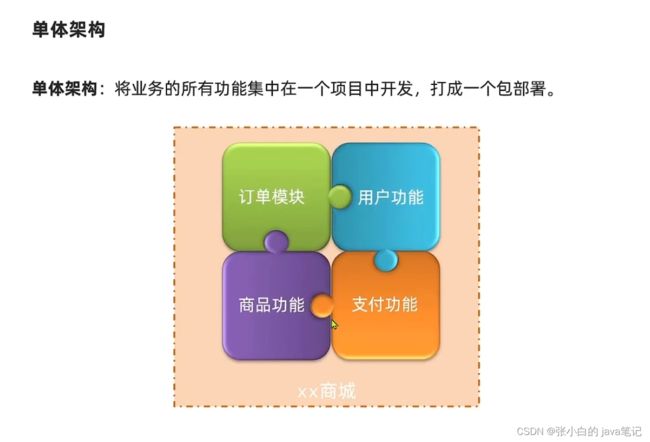
优点:
- 架构简单
- 部署成本低
缺点
- 耦合度高
————————————————
2、分布式架构

——————
拆分出现的问题:

3、微服务是什么 解决分布式架构的缺点

缺点 :更复杂的调用部署
【4】国内知名微服务治理SpringCloud 阿里巴巴Dubbo

企业需求
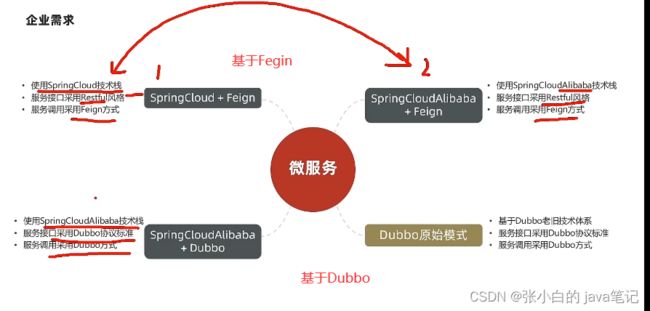
【5】SpringCloud
基本功能
SpringBoot的自动装配 实现框架集成

boot 和 cloud的兼容关系

【6】服务拆分和远程调用
不开发相同模块
数据库独立
暴露接口给其他服务调用
 案例讲解
案例讲解
导入demo 百度网盘 请输入提取码

配置自己的数据库信息
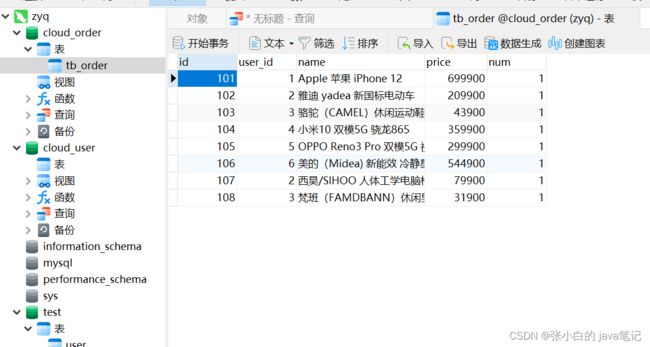 远程调用
远程调用
将服务作为发送请求的一方(类似前端ajax) 向一方发送请求 ,数据反会给服务调用方
 如何在java代码发送http请求
如何在java代码发送http请求
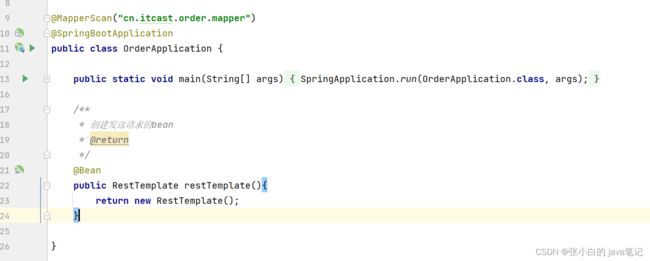
利用其发送请求得到信息封装 下面改成getUserId()
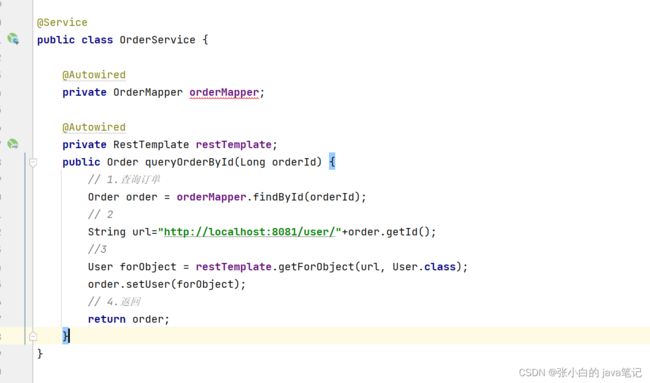 硬编码 高耦合 。。。。。。。。。。。。。。
硬编码 高耦合 。。。。。。。。。。。。。。
【7】微服务中 提供者和消费者

Eureka 服务注册和发现
【1】介绍

注册信息(每个服务启动时) 调用信息(找到服务 复杂均衡) 远程调用 心跳持续 30秒一次是调用者知道健康信息
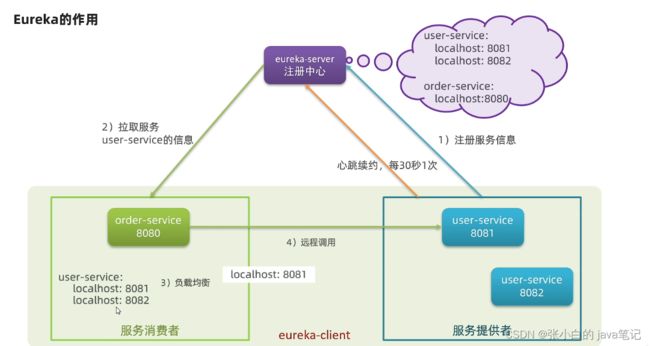

角色分配

【2】实践
搭建
新建一个Eureka服务
原工程新建模块 新建maven工程

添加依赖
创建main 启动

错误总结 中间停止了依赖的下载 导致没有下全 使得注解找不到
删除本地仓库依赖
添加yml文件
server:
port: 10086
spring:
application:
name: eureka-server #服务名称 为了将自己注册到自己身上 Eeruka自己也是一个微服务
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:10086/eurekaEureka 地址

【3】服务注册
service
下面,我们将user-service注册到eureka-server中去。
1)引入依赖
在user-service的pom文件中,引入下面的eureka-client依赖:
org.springframework.cloud spring-cloud-starter-netflix-eureka-client
2)配置文件
在user-service中,修改application.yml文件,添加服务名称、eureka地址:
spring: application: name: userservice eureka: client: service-url: defaultZone: http://127.0.0.1:10086/eureka
————————其他同理
注册列表服务 注意更改端口
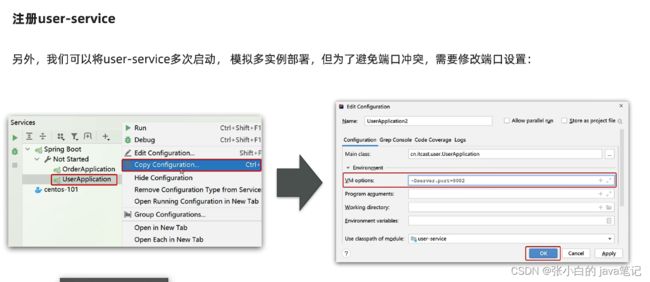


【3】服务发现
下面,我们将order-service的逻辑修改:向eureka-server拉取user-service的信息,实现服务发现。
1)引入依赖
之前说过,服务发现、服务注册统一都封装在eureka-client依赖,因此这一步与服务注册时一致。
在order-service的pom文件中,引入下面的eureka-client依赖:
org.springframework.cloud spring-cloud-starter-netflix-eureka-client
2)配置文件
服务发现也需要知道eureka地址,因此第二步与服务注册一致,都是配置eureka信息:
在order-service中,修改application.yml文件,添加服务名称、eureka地址:
spring: application: name: orderservice eureka: client: service-url: defaultZone: http://127.0.0.1:10086/eureka
3)服务拉取和负载均衡
最后,我们要去eureka-server中拉取user-service服务的实例列表,并且实现负载均衡。
不过这些动作不用我们去做,只需要添加一些注解即可。
————————————
解决ip端口不用的信息

访问
localhost:8080/order/101
localhost:8080/order/102


Ribbon 负载均衡
【1】介绍

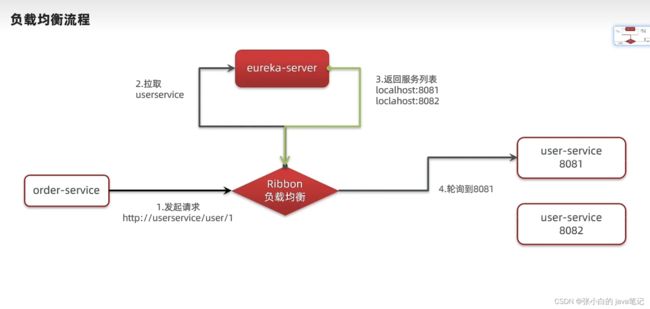
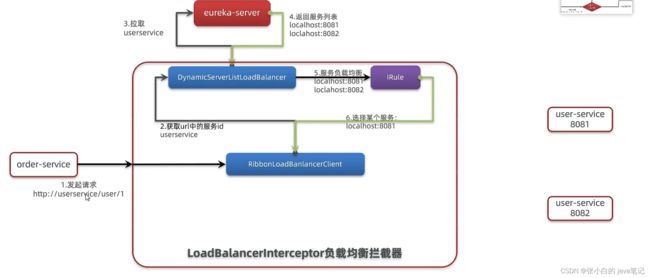
请求

 轮询调度 随机 等等
轮询调度 随机 等等

【2】Ribbon负载均衡实现 irule
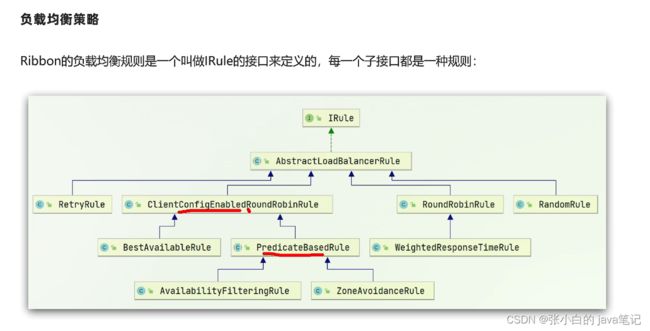

通过定义IRule实现可以修改负载均衡规则,有两种方式:
针对全部微服务
-
代码方式:在order-service中的OrderApplication类中,定义一个新的IRule:
@Bean
public IRule randomRule(){
return new RandomRule();
}
只针对userservice
-
配置文件方式:在order-service的application.yml文件中,添加新的配置也可以修改规则:
userservice: # 给某个微服务配置负载均衡规则,这里是userservice服务 ribbon: NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule # 负载均衡规则
【3】Ribbon饥饿加载
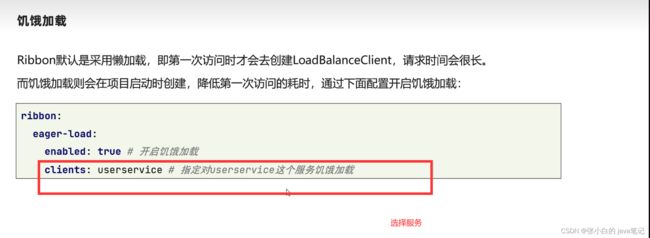
写在要调用别人的服务里面 以order的服务为例

NACOS阿里巴巴注册中心
【1】介绍
功能更多 支持配置中心
Nacos是SpringCloudAlibaba的组件,而SpringCloudAlibaba也遵循SpringCloud中定义的服务注册、服务发现规范。因此使用Nacos和使用Eureka对于微服务来说,并没有太大区别。
主要差异在于:
-
依赖不同
-
服务地址不同
# Nacos安装指南
# 1.Windows安装
开发阶段采用单机安装即可。
## 1.1.下载安装包
在Nacos的GitHub页面,提供有下载链接,可以下载编译好的Nacos服务端或者源代码:
GitHub主页:https://github.com/alibaba/nacos
GitHub的Release下载页:https://github.com/alibaba/nacos/releases
如图:

本课程采用1.4.1.版本的Nacos,课前资料已经准备了安装包:

windows版本使用`nacos-server-1.4.1.zip`包即可。
## 1.2.解压
将这个包解压到任意非中文目录下,如图:

目录说明:
- bin:启动脚本
- conf:配置文件
## 1.3.端口配置
Nacos的默认端口是8848,如果你电脑上的其它进程占用了8848端口,请先尝试关闭该进程。
**如果无法关闭占用8848端口的进程**,也可以进入nacos的conf目录,修改配置文件中的端口:

修改其中的内容:

## 1.4.启动
启动非常简单,进入bin目录,结构如下:

然后执行命令即可:
- windows命令:
```
startup.cmd -m standalone
```
执行后的效果如图:

## 1.5.访问
在浏览器输入地址:http://127.0.0.1:8848/nacos即可:

默认的账号和密码都是nacos,进入后:

# 2.Linux安装
Linux或者Mac安装方式与Windows类似。
## 2.1.安装JDK
Nacos依赖于JDK运行,索引Linux上也需要安装JDK才行。
上传jdk安装包:

上传到某个目录,例如:`/usr/local/`
然后解压缩:
```sh
tar -xvf jdk-8u144-linux-x64.tar.gz
```
然后重命名为java
配置环境变量:
```sh
export JAVA_HOME=/usr/local/java
export PATH=$PATH:$JAVA_HOME/bin
```
设置环境变量:
```sh
source /etc/profile
```
## 2.2.上传安装包
如图:

也可以直接使用课前资料中的tar.gz:

上传到Linux服务器的某个目录,例如`/usr/local/src`目录下:

## 2.3.解压
命令解压缩安装包:
```sh
tar -xvf nacos-server-1.4.1.tar.gz
```
然后删除安装包:
```sh
rm -rf nacos-server-1.4.1.tar.gz
```
目录中最终样式:

目录内部:

## 2.4.端口配置
与windows中类似
## 2.5.启动
在nacos/bin目录中,输入命令启动Nacos:
```sh
sh startup.sh -m standalone
```
# 3.Nacos的依赖
父工程:
```xml
com.alibaba.cloud
spring-cloud-alibaba-dependencies
2.2.5.RELEASE
pom
import
```
客户端:
```xml
com.alibaba.cloud
spring-cloud-starter-alibaba-nacos-discovery
```
最快速打开cmd窗口的办法是,直接在地址栏输入 cmd 回车 即可
单机模式 stndalone
【2】入门使用
直接父接pom添加依赖
注释eureka的依赖
添加依赖放在 服务中 所有服务
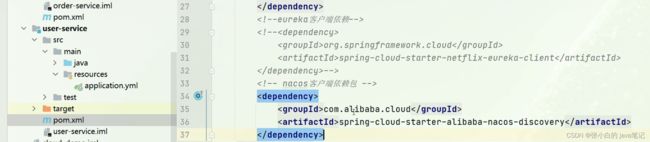
配置文件修改 所有服务
spring:
cloud:
nacos:
server-addr: localhost:8848

查看复杂均衡
服务多级存储模型

访问最近的集群最好
默认表示没有

添加
spring:
cloud:
nacos:
server-addr: localhost:8848
discovery:
cluster-name: HZ # 集群名称
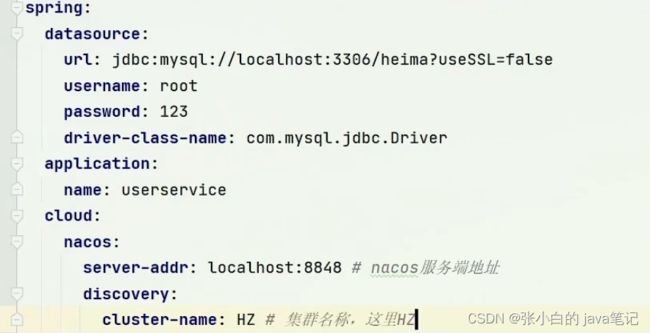
我们再次复制一个user-service启动配置,添加属性:
```sh
-Dserver.port=8083 -Dspring.cloud.nacos.discovery.cluster-name=SH
```
配置如图所示:


【3】Nacos的rule负载均衡
配置order的集群为HZ
试试访问的是不是最近的集群
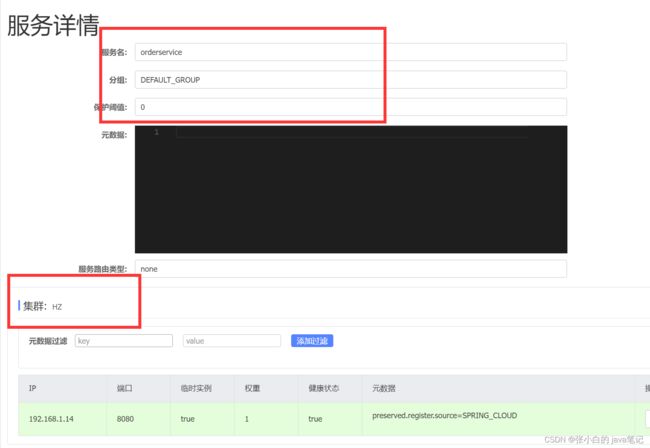
http://localhost:8080/order/101
http://localhost:8080/order/102
http://localhost:8080/order/103
就在所有user服务被访问 因为设置为轮询
修改复杂均衡规则
2)修改负载均衡规则
修改order-service的application.yml文件,修改负载均衡规则:
```yaml
userservice:
ribbon:
NFLoadBalancerRuleClassName: com.alibaba.cloud.nacos.ribbon.NacosRule # 负载均衡规则
```
当同集群的服务之间调用 集群中挂了 假设HZ的挂了 就将访问其他集群 但是会在日志中里记录。
权重修改
实际部署中会出现这样的场景:
服务器设备性能有差异,部分实例所在机器性能较好,另一些较差,我们希望性能好的机器承担更多的用户请求。
但默认情况下NacosRule是同集群内随机挑选,不会考虑机器的性能问题。
因此,Nacos提供了权重配置来控制访问频率,权重越大则访问频率越高。

在上图的编辑
修改权重
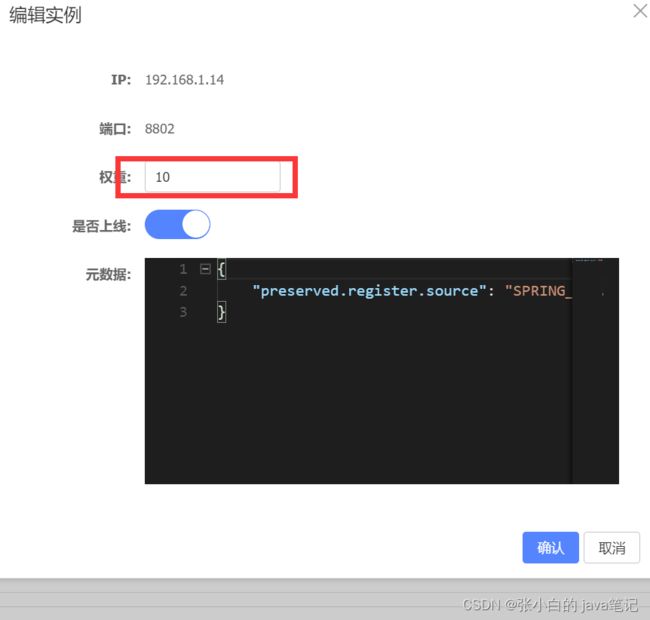
权重为0就是不访问服务
可以使用在服务升级 将某个服务权重没有 修改问一起更新。。
【4】环境隔离——namespace

Nacos提供了namespace来实现环境隔离功能。
-
nacos中可以有多个namespace
-
namespace下可以有group、service,想关性较高的服务放一个组等
-
不同namespace之间相互隔离,例如不同namespace的服务互相不可见
默认情况下,所有service、data、group都在同一个namespace,名为public:
我们可以点击页面新增按钮,添加一个namespace:
然后,填写表单:
就能在页面看到一个新的namespace:

给微服务配置namespace只能通过修改配置来实现。
例如,修改order-service的application.yml文件:
spring: cloud: nacos: server-addr: localhost:8848 discovery: cluster-name: HZ namespace: 492a7d5d-237b-46a1-a99a-fa8e98e4b0f9 # 命名空间,填ID
重启order-service后,访问控制台,可以看到下面的结果:
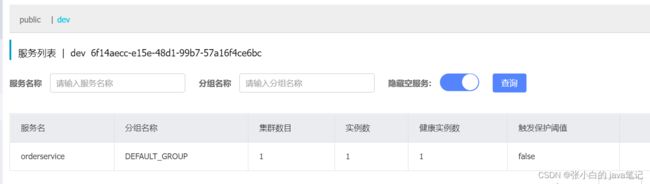
相互隔离了 找不到uesrseivice实例

【5】Nacos和Eureka的区别
默认都是临时实例



非临时实例会在被nacos主动询问是否还存活 宕机了就将他标记它不健康 等待活过来
nacos还会主动推出消息,告诉服务消费者。。
-
Nacos与eureka的共同点
-
都支持服务注册和服务拉取
-
都支持服务提供者心跳方式做健康检测
-
-
Nacos与Eureka的区别
-
Nacos支持服务端主动检测提供者状态:临时实例采用心跳模式,非临时实例采用主动检测模式
-
临时实例心跳不正常会被剔除,非临时实例则不会被剔除
-
Nacos支持服务列表变更的消息推送模式,服务列表更新更及时
-
Nacos集群默认采用AP方式,当集群中存在非临时实例时,采用CP模式;Eureka采用AP方式(没学到 ap cp)
-
【6】Nacos配置管理
配置的热更新 保证多个服务的配置更新
核心配置配置在nacos上面 更改会通知微服务
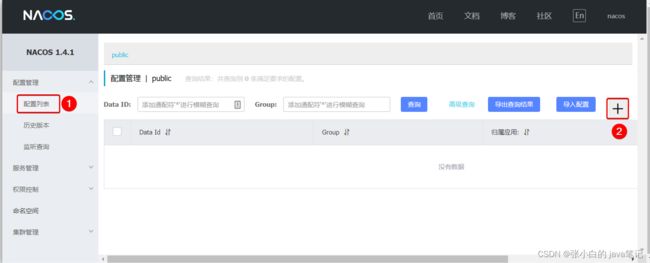 注意在public下创建 因为user服务在这个下面
注意在public下创建 因为user服务在这个下面

记得发布
配置服务的拉取

 不生效是不是没构建项目成功 重新构建
不生效是不是没构建项目成功 重新构建
查看读取
@Slf4j
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private UserService userService;
@Value("${pattern.dateformat}")
private String dateformat;
@GetMapping("now")
public String now(){
return LocalDateTime.now().format(DateTimeFormatter.ofPattern(dateformat));
}
// ...略
}
实现热更新
我们最终的目的,是修改nacos中的配置后,微服务中无需重启即可让配置生效,也就是配置热更新。
要实现配置热更新,可以使用两种方式:
1.2.1.方式一
在@Value注入的变量所在类上添加注解@RefreshScope:
1.2.2.方式二
使用@ConfigurationProperties注解代替@Value注解。
在user-service服务中,添加一个类,读取patterrn.dateformat属性:
package cn.itcast.user.config;
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;
@Component
@Data
@ConfigurationProperties(prefix = "pattern")
public class PatternProperties {
private String dateformat;
}
在UserController中使用这个类代替@Value:
完整代码:
package cn.itcast.user.web;
import cn.itcast.user.config.PatternProperties;
import cn.itcast.user.pojo.User;
import cn.itcast.user.service.UserService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
@Slf4j
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private UserService userService;
@Autowired
private PatternProperties patternProperties;
@GetMapping("now")
public String now(){
return LocalDateTime.now().format(DateTimeFormatter.ofPattern(patternProperties.getDateformat()));
}
// 略
}
【7】多环境的配置 实现开发测试环境都一样
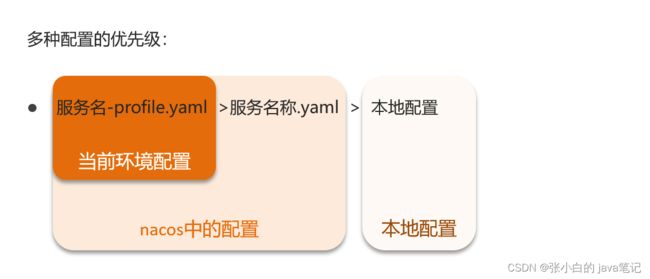
其实微服务启动时,会去nacos读取多个配置文件,例如:
- `[spring.application.name]-[spring.profiles.active].yaml`,例如:userservice-dev.yaml
- `[spring.application.name].yaml`,例如:userservice.yaml
而`[spring.application.name].yaml`不包含环境,因此可以被多个环境共享。
我们在nacos中添加一个userservice.yaml文件:
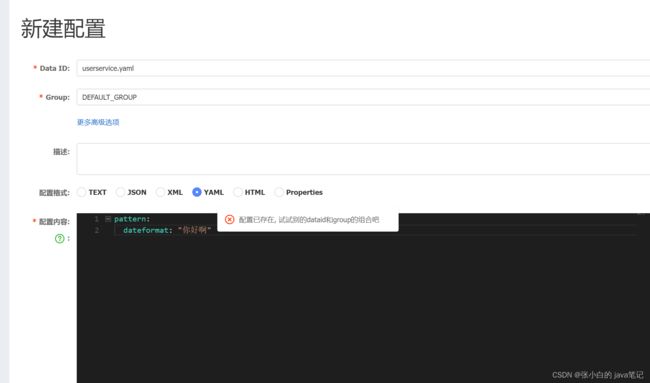
在user-service服务中,修改PatternProperties类,读取新添加的属性:

在user-service服务中,修改UserController,方法添加代码:

![]()
修改UserApplication2这个启动项,改变其profile值:

查看结果
——————————
读取的顺序

Feign远程调用
先来看我们以前利用RestTemplate发起远程调用的代码:
存在下面的问题:
•代码可读性差,编程体验不统一
•参数复杂URL难以维护
Feign是一个声明式的http客户端,官方地址:GitHub - OpenFeign/feign: Feign makes writing java http clients easier
其作用就是帮助我们优雅的实现http请求的发送,解决上面提到的问题。
【1】Feign替代RestTemplate
Fegin的使用步骤如下:
### 1)引入依赖
我们在order-service服务的pom文件中引入feign的依赖:
```xml
```
### 2)添加注解
在order-service的启动类添加注解开启Feign的功能:

3)编写Feign的客户端
在order-service中新建一个接口,内容如下:
package cn.itcast.order.client;
import cn.itcast.order.pojo.User;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
@FeignClient("userservice")
public interface UserClient {
@GetMapping("/user/{id}")
User findById(@PathVariable("id") Long id);
}
这个客户端主要是基于SpringMVC的注解来声明远程调用的信息,比如:
-
服务名称:userservice
-
请求方式:GET
-
请求路径:/user/{id}
-
请求参数:Long id
-
返回值类型:User
这样,Feign就可以帮助我们发送http请求,无需自己使用RestTemplate来发送了。
### 4)测试
修改order-service中的OrderService类中的queryOrderById方法,使用Feign客户端代替RestTemplate:

调用出错 两个服务还隔离呢

2.2.1.配置文件方式
基于配置文件修改feign的日志级别可以针对单个服务:
feign: client: config: userservice: # 针对某个微服务的配置 loggerLevel: FULL # 日志级别
也可以针对所有服务:
feign: client: config: default: # 这里用default就是全局配置,如果是写服务名称,则是针对某个微服务的配置 loggerLevel: FULL # 日志级别
而日志的级别分为四种:
-
NONE:不记录任何日志信息,这是默认值。
-
BASIC:仅记录请求的方法,URL以及响应状态码和执行时间
-
HEADERS:在BASIC的基础上,额外记录了请求和响应的头信息
-
FULL:记录所有请求和响应的明细,包括头信息、请求体、元数据。
### 2.2.2.Java代码方式
也可以基于Java代码来修改日志级别,先声明一个类,然后声明一个Logger.Level的对象:
```java
public class DefaultFeignConfiguration {
@Bean
public Logger.Level feignLogLevel(){
return Logger.Level.BASIC; // 日志级别为BASIC
}
}
```
如果要**全局生效**,将其放到启动类的@EnableFeignClients这个注解中:
```java
@EnableFeignClients(defaultConfiguration = DefaultFeignConfiguration .class)
```
如果是**局部生效**,则把它放到对应的@FeignClient这个注解中:
```java
@FeignClient(value = "userservice", configuration = DefaultFeignConfiguration .class)
```
【2】Feign使用优化
Feign底层发起http请求,依赖于其它的框架。其底层客户端实现包括:
•URLConnection:默认实现,不支持连接池
•Apache HttpClient :支持连接池
•OKHttp:支持连接池
因此提高Feign的性能主要手段就是使用连接池代替默认的URLConnection。
这里我们用Apache的HttpClient来演示。
1)引入依赖
在order-service的pom文件中引入Apache的HttpClient依赖:
io.github.openfeign feign-httpclient
2)配置连接池
在order-service的application.yml中添加配置:
feign: client: config: default: # default全局的配置 loggerLevel: BASIC # 日志级别,BASIC就是基本的请求和响应信息 httpclient: enabled: true # 开启feign对HttpClient的支持 max-connections: 200 # 最大的连接数 max-connections-per-route: 50 # 每个路径的最大连接数
参数来连接使用jemeter去测速度什么值合适
接下来,在FeignClientFactoryBean中的loadBalance方法中打断点:
Debug方式启动order-service服务,可以看到这里的client,底层就是Apache HttpClient:
总结,Feign的优化:
1.日志级别尽量用basic
2.使用HttpClient或OKHttp代替URLConnection
① 引入feign-httpClient依赖
② 配置文件开启httpClient功能,设置连接池参数
【3】最佳实践 (公司得到的结果)


下面时一种方法 但是不推荐

模块抽取
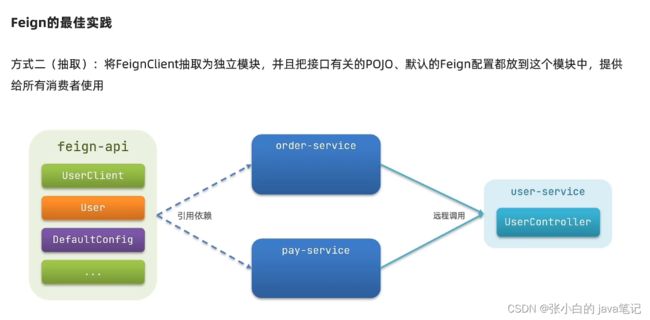

2
 3
3
cn.itcast.demo feign-api 1.0
更改导包
添加扫描 没扫描到 添加class

——————解决扫描包问题
方式一:
指定Feign应该扫描的包:
```java
@EnableFeignClients(basePackages = "cn.itcast.feign.clients")
```
方式二:
指定需要加载的Client接口:
```java
@EnableFeignClients(clients = {UserClient.class})
```
gateway:网关
【1】介绍
对身份验证
权限管控
服务路由 负载均衡
请求限流

【2】网关入门

创建服务:
引入依赖:
org.springframework.cloud spring-cloud-starter-gateway com.alibaba.cloud spring-cloud-starter-alibaba-nacos-discovery
2)编写启动类
package cn.itcast.gateway;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class GatewayApplication {
public static void main(String[] args) {
SpringApplication.run(GatewayApplication.class, args);
}
}
3)编写基础配置和路由规则
创建application.yml文件,内容如下:
server: port: 10010 # 网关端口 spring: application: name: gateway # 服务名称 cloud: nacos: server-addr: localhost:8848 # nacos地址 gateway: routes: # 网关路由配置 - id: user-service # 路由id,自定义,只要唯一即可 # uri: http://127.0.0.1:8081 # 路由的目标地址 http就是固定地址 uri: lb://userservice # 路由的目标地址 lb就是负载均衡,后面跟服务名称 predicates: # 路由断言,也就是判断请求是否符合路由规则的条件 - Path=/user/** # 这个是按照路径匹配,只要以/user/开头就符合要求
我们将符合Path 规则的一切请求,都代理到 uri参数指定的地址。
本例中,我们将 /user/**开头的请求,代理到lb://userservice,lb是负载均衡,根据服务名拉取服务列表,实现负载均衡。
4)重启测试
重启网关,访问http://localhost:10010/user/1时,符合/user/**规则,请求转发到uri:http://userservice/user/1,得到了结果:

【3】断言工厂
不止可以对路径做断言
我们在配置文件中写的断言规则只是字符串,这些字符串会被Predicate Factory读取并处理,转变为路由判断的条件
例如Path=/user/**是按照路径匹配,这个规则是由
org.springframework.cloud.gateway.handler.predicate.PathRoutePredicateFactory类来
处理的,像这样的断言工厂在SpringCloudGateway还有十几个:
| 名称 | 说明 | 示例 |
|---|---|---|
| After | 是某个时间点后的请求 | - After=2037-01-20T17:42:47.789-07:00[America/Denver] |
| Before | 是某个时间点之前的请求 | - Before=2031-04-13T15:14:47.433+08:00[Asia/Shanghai] |
| Between | 是某两个时间点之前的请求 | - Between=2037-01-20T17:42:47.789-07:00[America/Denver], 2037-01-21T17:42:47.789-07:00[America/Denver] |
| Cookie | 请求必须包含某些cookie | - Cookie=chocolate, ch.p |
| Header | 请求必须包含某些header | - Header=X-Request-Id, \d+ |
| Host | 请求必须是访问某个host(域名) | - Host=.somehost.org,.anotherhost.org |
| Method | 请求方式必须是指定方式 | - Method=GET,POST |
| Path | 请求路径必须符合指定规则 | - Path=/red/{segment},/blue/** |
| Query | 请求参数必须包含指定参数 | - Query=name, Jack或者- Query=name |
| RemoteAddr | 请求者的ip必须是指定范围 | - RemoteAddr=192.168.1.1/24 |
| Weight | 权重处理 |
只需要掌握Path这种路由工程就可以了。自己几个匹配就行了
不生效的话 404
【4】过滤器工厂
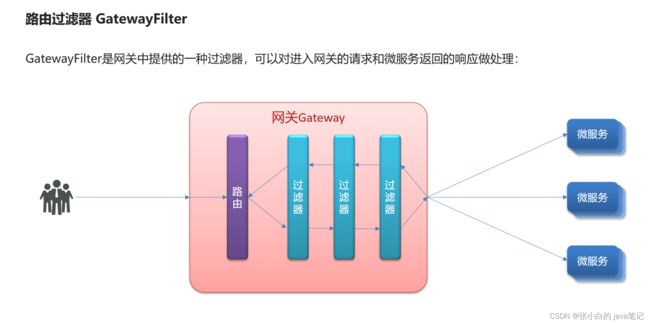
Spring提供了31种不同的路由过滤器工厂。例如:
| 名称 | 说明 |
|---|---|
| AddRequestHeader | 给当前请求添加一个请求头 |
| RemoveRequestHeader | 移除请求中的一个请求头 |
| AddResponseHeader | 给响应结果中添加一个响应头 |
| RemoveResponseHeader | 从响应结果中移除有一个响应头 |
| RequestRateLimiter | 限制请求的流量 |
3.4.2.请求头过滤器
下面我们以AddRequestHeader 为例来讲解。
需求:给所有进入userservice的请求添加一个请求头:Truth=itcast is freaking awesome!
只需要修改gateway服务的application.yml文件,添加路由过滤即可:
spring: cloud: gateway: routes: - id: user-service uri: lb://userservice predicates: - Path=/user/** filters: # 过滤器 - AddRequestHeader=Truth, Itcast is freaking awesome! # 添加请求头
当前过滤器写在userservice路由下,因此仅仅对访问userservice的请求有效。
3.4.3.默认过滤器
如果要对所有的路由都生效,则可以将过滤器工厂写到default下。格式如下:
spring: cloud: gateway: routes: - id: user-service uri: lb://userservice predicates: - Path=/user/** default-filters: # 默认过滤项 - AddRequestHeader=Truth, Itcast is freaking awesome!
【5】全局过滤器GlobalFilter
全局过滤器的作用也是处理一切进入网关的请求和微服务响应,与GatewayFilter的作用一样。区别在于GatewayFilter通过配置定义,处理逻辑是固定的;而GlobalFilter的逻辑需要自己写代码实现。
自己可以在代码里控制逻辑
定义方式是实现GlobalFilter接口。
public interface GlobalFilter {
/**
* 处理当前请求,有必要的话通过{@link GatewayFilterChain}将请求交给下一个过滤器处理
*
* @param exchange 请求上下文,里面可以获取Request、Response等信息
* @param chain 用来把请求委托给下一个过滤器 过滤器链
* @return {@code Mono} 返回标示当前过滤器业务结束
*/
Mono filter(ServerWebExchange exchange, GatewayFilterChain chain);
}
在filter中编写自定义逻辑,可以实现下列功能:
-
登录状态判断
-
权限校验
-
请求限流等
自定义过滤器——————
需求:定义全局过滤器,拦截请求,判断请求的参数是否满足下面条件:
- 参数中是否有authorization,
- authorization参数值是否为admin
如果同时满足则放行,否则拦截
//
package cn.itcast.gateway.filters;
import org.springframework.cloud.gateway.filter.GatewayFilterChain;
import org.springframework.cloud.gateway.filter.GlobalFilter;
import org.springframework.core.annotation.Order;
import org.springframework.http.HttpStatus;
import org.springframework.stereotype.Component;
import org.springframework.web.server.ServerWebExchange;
import reactor.core.publisher.Mono;
@Order(-1)//设置过滤其的执行顺序
@Component
public class AuthorizeFilter implements GlobalFilter {
@Override
public Mono filter(ServerWebExchange exchange, GatewayFilterChain chain) {
// 1.获取请求参数
MultiValueMap params = exchange.getRequest().getQueryParams();
// 2.获取authorization参数
String auth = params.getFirst("authorization");
// 3.校验
if ("admin".equals(auth)) {
// 放行
return chain.filter(exchange);
}
// 4.拦截
// 4.1.禁止访问,设置状态码
exchange.getResponse().setStatusCode(HttpStatus.FORBIDDEN);
// 4.2.结束处理
return exchange.getResponse().setComplete();
}
} 使用网关地址测试

localhost:10010/user/1?authorization=admin

【6】过滤器执行顺序
三种过滤器都是实现gatewayfilter

跨域问题解决


使用Vscode将此页面打开 启动此前端服务 发送请求
Document
spring:
cloud:
gateway:
globalcors: # 全局的跨域处理
add-to-simple-url-handler-mapping: true # 解决options请求被拦截问题
corsConfigurations:
'[/**]':
allowedOrigins: # 允许哪些网站的跨域请求
- "http://localhost:8090"
- "http://www.leyou.com"
allowedMethods: # 允许的跨域ajax的请求方式
- "GET"
- "POST"
- "DELETE"
- "PUT"
- "OPTIONS"
allowedHeaders: "*" # 允许在请求中携带的头信息
allowCredentials: true # 是否允许携带cookie
maxAge: 360000 # 这次跨域检测的有效期
出现跨域 将此域ip配置到网关配置文件中
Hystrix 断路
【1】介绍
一、背景介绍
1、服务雪崩
分布式系统环境下,服务间类似依赖非常常见,一个业务调用通常依赖多个基础服务。如下图,
如果各个服务正常运行,那大家齐乐融融,高高兴兴的,但是如果其中一个服务崩坏掉会出现什么样的情况呢?如下图,
当Service A的流量波动很大,流量经常会突然性增加!那么在这种情况下,就算Service A能扛得住请求,Service B和Service C未必能扛得住这突发的请求。
此时,如果Service C因为抗不住请求,变得不可用。那么Service B的请求也会阻塞,慢慢耗尽Service B的线程资源,Service B就会变得不可用。紧接着,Service A也会不可用。
So,简单地讲。一个服务失败,导致整条链路的服务都失败的情形,我们称之为服务雪崩。
————
2、引起雪崩的原因和服务雪崩的三个阶段
原因大致有四:
1、硬件故障;
2、程序Bug;
3、缓存击穿(用户大量访问缓存中没有的键值,导致大量请求查询数据库,使数据库压力过大);
4、用户大量请求;
服务雪崩的第一阶段: 服务不可用;
第二阶段:调用端重试加大流量(用户重试/代码逻辑重试);
第三阶段:服务调用者不可用(同步等待造成的资源耗尽)
————————————————
3、解决方案
1) 应用扩容(扩大服务器承受力)
加机器
升级硬件
2)流量控制(超出限定流量,返回类似重试页面让用户稍后再试)
限流
关闭重试
3) 缓存
将用户可能访问的数据大量的放入缓存中,减少访问数据库的请求。
4)服务降级
服务接口拒绝服务
页面拒绝服务
延迟持久化
随机拒绝服务
5) 服务熔断
————————————————
服务降级:对方服务不可用了你要给别人一个信息。
服务器忙 来不及处理 不让客户端等待,立即返回一个友好提示。
(超时 异常 熔断。。。 )
服务熔断:达到最大服务器 直接拒绝访问 。。。
服务限流:高并发 限制流量 秒杀场景严禁一起来
————————
Hystrix是一个库,通过添加延迟容忍和容错逻辑,帮助你控制这些分布式服务之间的交互。Hystrix通过隔离服务之间的访问点、停止级联失败和提供回退选项来实现这一点,所有这些都可以提高系统的整体弹性。
————————
以项目案例开始,快速入门(使用IDEA)
场景假设1( 服务提供方报错) : 在服务提供端中因为访问不到数据库中的数据(比如数据不存在,或是数据库压力过大,查询请求队列中),在这种情况下,服务提供方这边如何实现服务降级,以防止服务雪崩.
【2】服务降级
1/、、
使用IDEA新建一个 microservice-provider-hystrix 工程
因为此工程要受到Hystrix保护,所以加入依赖.
2、、
在microservice-provider-hystrix 工程的启动类上启用断路器
在启动类上加入注解
@EnableCircuitBreaker //启用断路器
注意: 这里其实也可以使用 spring cloud应用中的@SpringCloudApplication注解,因为它已经自带了这些注解,源码如下:
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@SpringBootApplication
@EnableDiscoveryClient
@EnableCircuitBreaker
public @interface SpringCloudApplication {
}
2、、也可以使用配置文件配置

3、、
在 ProductController中加入断路逻辑
@RequestMapping("/get/{id}")
@HystrixCommand(fallbackMethod="errorCallBack" value=3000) //errorCallBack方法兜底 模仿没有这个数据时,服务降级 value直接限制时间
public Object get(@PathVariable("id") long id){
Product p=this.productService.findById(id);
if( p==null){
throw new RuntimeException("查无此产品");
}
return p;
}
//指定一个降级的方法
public Object errorCallBack( @PathVariable("id") long id ){
return id+"不存在,error";
}
启动provider服务后测试
小结: 服务降级 由服务提供方 处理
————————————————
jemeter压测 20000线程

自设端口路径


tomcat线程数都去处理了下面的 可能上面的方法就需要等待
微服务调用微服务出现卡顿
1、消费者处理降级
场景假设2: 因为网络抖动,或服务端维护导致的服务暂时不可用,此时是客户端联接不到服务器,因为feign有重试机制,这样会导致系统长时间不响应,那么在这种情况上如何通过 feign+hystrix 在服务的消费方实现服务熔断(回退机制)呢?
首先确认一下我们使用的客户端是 microservice-consumer-feign , feign中自带了 hystrix,但并没有启动,所以要配置启用hystrix,修改 application.yml
feign:
hystrix:
enabled: true
我们的服务消费方的feign操作接口位于 microservice-interface中,所以要在这里配置
建立一个包 fallback,用于存回退处理类 IProductClientServiceFallbackFactory,这个类有出现请求异常时的处理
package com.yc.springcloud2.fallback;
import com.yc.springcloud2.bean.Product;
import com.yc.springcloud2.service.IProductClientService;
import feign.hystrix.FallbackFactory;
import java.util.List;
@Component //必须被spring 托管
public class IProductClientServiceFallbackFactory implements FallbackFactory
@Override
public IProductClientService create(Throwable throwable) {
//这里提供请求方法出问题时回退处理机制
return new IProductClientService(){
@Override
public Product getProduct(long id) {
Product p=new Product();
p.setProductId(999999999L);
p.setProductDesc("error");
return p;
}
@Override
public List
return null;
}
@Override
public boolean addPorduct(Product product) {
return false;
}
};
}
}
在业务接口上加入 fallbackFactory属性指定异常处理类
@FeignClient(name="MICROSERVICE-PROVIDER-PRODUCT",
configuration = FeignClientConfig.class,
fallbackFactory = IProductClientServiceFallbackFactory.class) // 配置要按自定义的类FeignClientConfig
public interface IProductClientService {}
启动 microservice-consumer-feign客户端进行测试, 在测试时,尝试关闭生产端,看它是否回退
小结: 服务熔断在消费端 处理
意思:服务消费方 自己的服务没有在规定时间处理完 就可以自己降级返回
————————————————
2、全局降级
不用使每个方法都有降级 避免代码混乱 代码膨胀
加在controller上 注解的值就是全局的follback方法
![]()
有自己降级方法的优先使用自己的降级
给服务提供者添加统配降级
在service接口上定义 代码看起来方便
【3】服务熔断

【4】服务监控
config 分布式配置中心
coofig 被nocas替代
Docker
【1】介绍
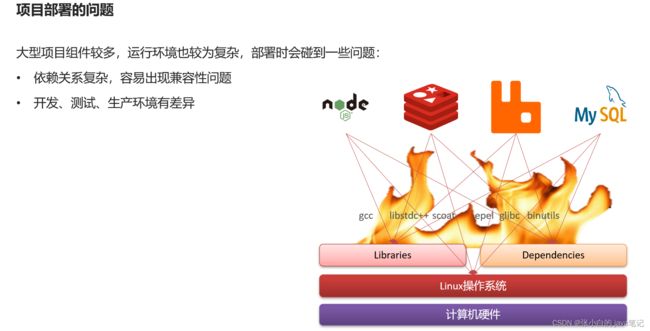
微服务虽然具备各种各样的优势,但服务的拆分通用给部署带来了很大的麻烦。
- 分布式系统中,依赖的组件非常多,不同组件之间部署时往往会产生一些冲突。
- 在数百上千台服务中重复部署,环境不一定一致,会遇到各种问题
例如一个项目中,部署时需要依赖于node.js、Redis、RabbitMQ、MySQL等,这些服务部署时所需要的函数库、依赖项各不相同,甚至会有冲突。给部署带来了极大的困难。
_____________________
而Docker确巧妙的解决了这些问题,Docker是如何实现的呢?
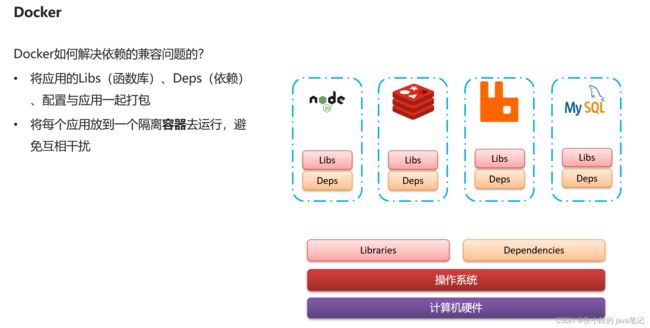
Docker为了解决依赖的兼容问题的,采用了两个手段:
- 将应用的Libs(函数库)、Deps(依赖)、配置与应用一起打包
- 将每个应用放到一个隔离**容器**去运行,避免互相干扰
操作系统

为什么不能跨系统运行呢
函数库不同
 Docker
Docker
解决将函数库打包 直接使用linux内核来执行
### 1.1.4.小结
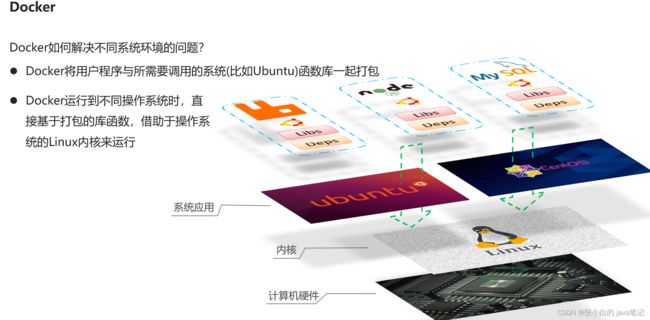
Docker如何解决大型项目依赖关系复杂,不同组件依赖的兼容性问题?
- Docker允许开发中将应用、依赖、函数库、配置一起**打包**,形成可移植镜像
- Docker应用运行在容器中,使用沙箱机制,相互**隔离**
Docker如何解决开发、测试、生产环境有差异的问题?
- Docker镜像中包含完整运行环境,包括系统函数库,仅依赖系统的Linux内核,因此可以在任意Linux操作系统上运行
Docker是一个快速交付应用、运行应用的技术,具备下列优势:
- 可以将程序及其依赖、运行环境一起打包为一个镜像,可以迁移到任意Linux操作系统
- 运行时利用沙箱机制形成隔离容器,各个应用互不干扰
- 启动、移除都可以通过一行命令完成,方便快捷
【2】虚拟机和docker
两者有什么差异呢?
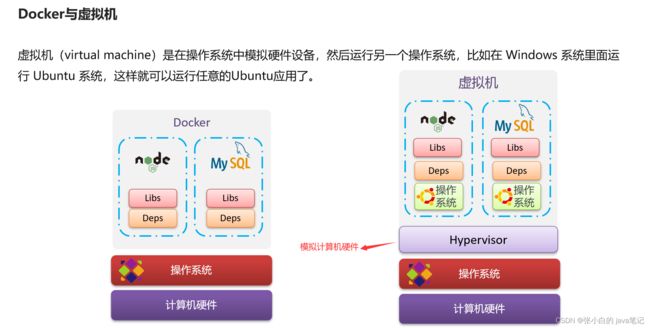
**虚拟机**(virtual machine)是在操作系统中**模拟**硬件设备,然后运行另一个操作系统,比如在 Windows 系统里面运行 Ubuntu 系统,这样就可以运行任意的Ubuntu应用了。
**Docker**仅仅是封装函数库,并没有模拟完整的操作系统,如图:
区别
只需要软件运行的相关函数库和依赖

小结:
Docker和虚拟机的差异:
- docker是一个系统进程;虚拟机是在操作系统中的操作系统
- docker体积小、启动速度快、性能好;虚拟机体积大、启动速度慢、性能一般
【3】 docker架构 : 镜像和容器
Docker中有几个重要的概念:
**镜像(Image)**:Docker将应用程序及其所需的依赖、函数库、环境、配置等文件打包在一起,称为镜像。
**容器(Container)**:镜像中的应用程序运行后形成的进程就是**容器**,只是Docker会给容器进程做隔离,对外不可见。
一切应用最终都是代码组成,都是硬盘中的一个个的字节形成的**文件**。只有运行时,才会加载到内存,形成进程。
而**镜像**,就是把一个应用在硬盘上的文件、及其运行环境、部分系统函数库文件一起打包形成的文件包。这个文件包是只读的。
**容器**呢,就是将这些文件中编写的程序、函数加载到内存中允许,跑起来,形成进程,只不过要隔离起来。因此一个镜像可以启动多次,形成多个容器进程。
【4】docker架构:DockerHub

【5】Docker 安装
买一个云服务器
0.安装Docker
Docker 分为 CE 和 EE 两大版本。CE 即社区版(免费,支持周期 7 个月),EE 即企业版,强调安全,付费使用,支持周期 24 个月。
Docker CE 分为 stable test 和 nightly 三个更新频道。
官方网站上有各种环境下的 安装指南,这里主要介绍 Docker CE 在 CentOS上的安装。
1.CentOS安装Docker
Docker CE 支持 64 位版本 CentOS 7,并且要求内核版本不低于 3.10, CentOS 7 满足最低内核的要求,所以我们在CentOS 7安装Docker。
1.1.卸载(可选)
如果之前安装过旧版本的Docker,可以使用下面命令卸载:
yum remove docker \ docker-client \ docker-client-latest \ docker-common \ docker-latest \ docker-latest-logrotate \ docker-logrotate \ docker-selinux \ docker-engine-selinux \ docker-engine \ docker-ce
1.2.安装docker
首先需要大家虚拟机联网,安装yum工具
yum install -y yum-utils \ device-mapper-persistent-data \ lvm2 --skip-broken
然后更新本地镜像源:
# 设置docker镜像源 yum-config-manager \ --add-repo \ https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo sed -i 's/download.docker.com/mirrors.aliyun.com\/docker-ce/g' /etc/yum.repos.d/docker-ce.repo yum makecache fast
然后输入命令:
yum install -y docker-ce
docker-ce为社区免费版本。稍等片刻,docker即可安装成功。
1.3.启动docker
Docker应用需要用到各种端口,逐一去修改防火墙设置。非常麻烦,因此建议大家直接关闭防火墙!
启动docker前,一定要关闭防火墙后!!
启动docker前,一定要关闭防火墙后!!
启动docker前,一定要关闭防火墙后!!
# 关闭 systemctl stop firewalld # 禁止开机启动防火墙 systemctl disable firewalld
通过命令启动docker:
systemctl start docker # 启动docker服务 systemctl stop docker # 停止docker服务 systemctl restart docker # 重启docker服务
然后输入命令,可以查看docker版本:
docker -v
如图:
1.4.配置镜像加速
docker官方镜像仓库网速较差,我们需要设置国内镜像服务:
参考阿里云的镜像加速文档:阿里云登录 - 欢迎登录阿里云,安全稳定的云计算服务平台
【6】镜像操作
首先来看下镜像的名称组成:
-
镜名称一般分两部分组成:[repository]:[tag]。
-
在没有指定tag时,默认是latest,代表最新版本的镜像
如图:
这里的mysql就是repository,5.7就是tag,合一起就是镜像名称,代表5.7版本的MySQL镜像。


docker --help 查看命令
docker images --help 查看相关imager命令
2.1.3.案例1-拉取、查看镜像
需求:从DockerHub中拉取一个nginx镜像并查看
1)首先去镜像仓库搜索nginx镜像,比如DockerHub:
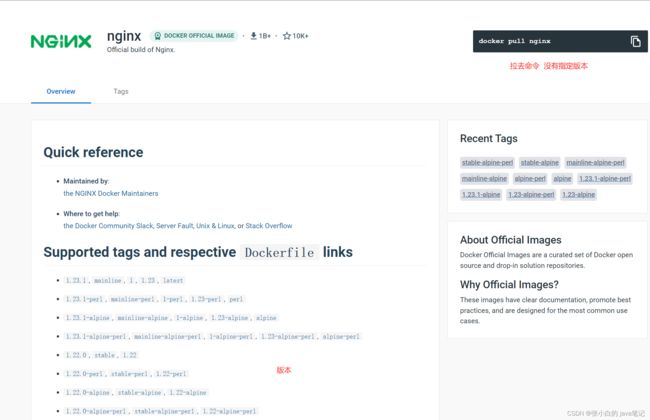
2)根据查看到的镜像名称,拉取自己需要的镜像,通过命令:docker pull nginx
3)通过命令:docker images 查看拉取到的镜像

2.1.4.案例2-保存、导入镜像
需求:利用docker save将nginx镜像导出磁盘,然后再通过load加载回来
1)利用docker xx --help命令查看docker save和docker load的语法
例如,查看save命令用法,可以输入命令:
docker save --help 结果:
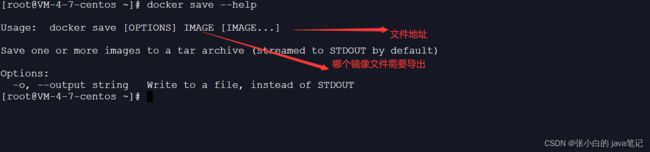
命令格式:
docker save -o [保存的目标文件名称] [镜像名称]
2)使用docker save导出镜像到磁盘
运行命令:
docker save -o nginx.tar nginx:latest
ll 查看是否成功
结果如图:

3)使用docker load加载镜像
先删除本地的nginx镜像:
docker rmi nginx:latest
然后运行命令,加载本地文件:
docker load -help查看
docker load -i nginx.tar
结果:

### 2.1.5.练习
需求:去DockerHub搜索并拉取一个Redis镜像
目标:
1)去DockerHub搜索Redis镜像
2)查看Redis镜像的名称和版本
3)利用docker pull命令拉取镜像
4)利用docker save命令将 redis:latest打包为一个redis.tar包
5)利用docker rmi 删除本地的redis:latest
6)利用docker load 重新加载 redis.tar文件
【6】容器相关命令

容器保护三个状态:
- 运行:进程正常运行
- 暂停:进程暂停,CPU不再运行,并不释放内存
- 停止:进程终止,回收进程占用的内存、CPU等资源 start重新开始
其中:
- docker run:创建并运行一个容器,处于运行状态
- docker pause:让一个运行的容器暂停
- docker unpause:让一个容器从暂停状态恢复运行
- docker stop:停止一个运行的容器
- docker start:让一个停止的容器再次运行
- docker rm:删除一个容器
——————————



-d 一直后台运行 不关掉的意思
-p 使用docker的端口代替容器端口
————————
docker ps
查看
![]()

Welcome to nginx! http://81.68.76.47/ ________
http://81.68.76.47/ ________
docker logs 容器名 查看日志
docker logs -f 容器名 跟踪日志
【案例】进入容器 修改
**需求**:进入Nginx容器,修改HTML文件内容,添加“传智教育欢迎您”
**提示**:进入容器要用到docker exec命令。
**步骤**:
1)进入容器。进入我们刚刚创建的nginx容器的命令为:
```sh
docker exec -it mn bash
```
命令解读:
- docker exec :进入容器内部,执行一个命令
- -it : 给当前进入的容器创建一个标准输入、输出终端,允许我们与容器交互
- mn :要进入的容器的名称
- bash:进入容器后执行的命令,bash是一个linux终端交互命令 可以使用linux命令
容器内部会模拟一个独立的Linux文件系统,看起来如同一个linux服务器一样:

2)进入nginx的HTML所在目录 /usr/share/nginx/html
容器内部会模拟一个独立的Linux文件系统,看起来如同一个linux服务器一样:

nginx的环境、配置、运行文件全部都在这个文件系统中,包括我们要修改的html文件。
只有作者知道文件在哪
查看DockerHub网站中的nginx页面,可以知道nginx的html目录位置在`/usr/share/nginx/html`
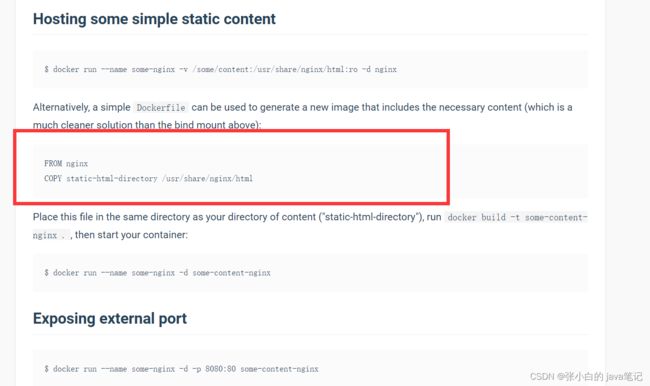
我们执行命令,进入该目录:
```sh
cd /usr/share/nginx/html
```
查看目录下文件:
3)修改index.html的内容
容器内没有vi(vim)命令,无法直接修改,我们用下面的命令来修改:
```sh
sed -i -e 's#Welcome to nginx#凤凰传奇#g' -e 's#
```
在浏览器访问自己的虚拟机地址,例如我的是:Welcome to nginx!http://81.68.76.47/,即可看到结果:
docker run命令的常见参数有哪些?
- --name:指定容器名称
- -p:指定端口映射
- -d:让容器后台运行
查看容器日志的命令:
- docker logs
- 添加 -f 参数可以持续查看日志
查看容器状态:
- docker ps
- docker ps -a 查看所有容器,包括已经停止的
删除容器
docker rm (-help可查看强制删除)
exit 退出容器——————————
![]()
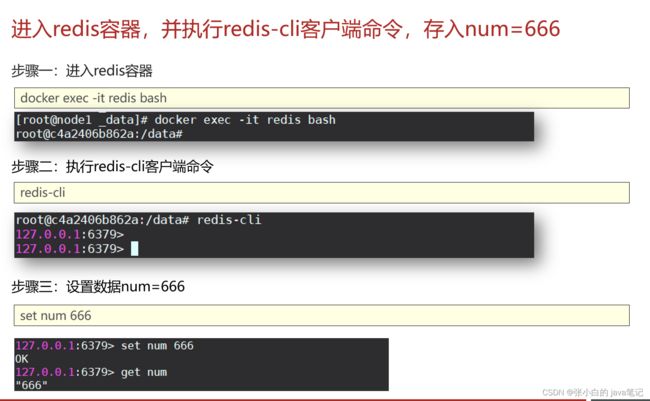
【案例】redis容器


【7】挂载 ——不在容器里面更改数据((数据卷 数据管理
在之前的nginx案例中,修改nginx的html页面时,需要进入nginx内部。并且因为没有编辑器,修改文件也很麻烦。
这就是因为容器与数据(容器内文件)耦合带来的后果。
要解决这个问题,必须将数据与容器解耦,这就要用到数据卷了。


做映射了 就不用在容器修改了
容器可以访问volumes volumes不影响原来容器 一个volumes可以挂载多个文件
——————————

需求:创建一个数据卷,并查看数据卷在宿主机的目录位置
① 创建数据卷
docker volume create html
② 查看所有数据
docker volume ls
结果:
③ 查看数据卷详细信息卷
docker volume inspect html
结果:
可以看到,我们创建的html这个数据卷关联的宿主机目录为/var/lib/docker/volumes/html/_data目录。真实存储的地址
小结:
数据卷的作用:
-
将容器与数据分离,解耦合,方便操作容器内数据,保证数据安全
数据卷操作:
-
docker volume create:创建数据卷
-
docker volume ls:查看所有数据卷
-
docker volume inspect:查看数据卷详细信息,包括关联的宿主机目录位置
-
docker volume rm:删除指定数据卷
-
docker volume prune:删除所有未使用的数据卷
挂载容器文件
我们在创建容器时,可以通过 -v 参数来挂载一个数据卷到某个容器内目录,命令格式如下:
docker run \ --name mn \ -v html:/root/html \ -p 8080:80 nginx \
这里的-v就是挂载数据卷的命令:
-
-v html:/root/htm:把html数据卷挂载到容器内的/root/html这个目录中
2.3.5.案例-给nginx挂载数据卷
需求:创建一个nginx容器,修改容器内的html目录内的index.html内容
分析:上个案例中,我们进入nginx容器内部,已经知道nginx的html目录所在位置/usr/share/nginx/html ,我们需要把这个目录挂载到html这个数据卷上,方便操作其中的内容。
提示:运行容器时使用 -v 参数挂载数据卷
步骤:
① 创建容器并挂载数据卷到容器内的HTML目录
docker run --name mn -v html:/usr/share/nginx/html -p 80:80 -d nginx
② 进入html数据卷所在位置,并修改HTML内容
# 查看html数据卷的位置 docker volume inspect html # 进入该目录 cd /var/lib/docker/volumes/html/_data # 修改文件 vi index.html
也可使用本软件打开 index.html 修改 找到地址
删除容器 删除卷
docker rm -f mn
docker volume prune
没有创建html数据卷 创建容器时可直接创建
docker run --name mn -v html:/usr/share/nginx/html -p 80:80 -d nginx
【8】直接挂载到宿主机
容器不仅仅可以挂载数据卷,也可以直接挂载到宿主机目录上。关联关系如下:
- 带数据卷模式:宿主机目录 --> 数据卷 ---> 容器内目录
- 直接挂载模式:宿主机目录 ---> 容器内目录
如图:
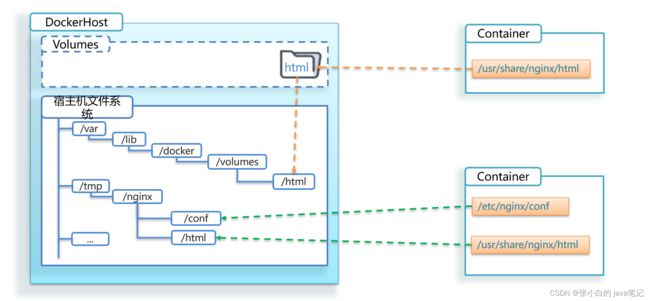
实现思路如下:
1)在将课前资料中的mysql.tar文件(hub上拉取也可以)上传到虚拟机,通过load命令加载为镜像
2)创建目录/tmp/mysql/data midir -p /tmp/mysql/data
3)创建目录/tmp/mysql/conf,midir -p /tmp/mysql/conf 。将课前资料提供的hmy.cnf文件拖到到/tmp/mysql/conf(云服务器使用命令执行)
4)去DockerHub查阅资料,创建并运行MySQL容器,要求:
① 挂载/tmp/mysql/data到mysql容器内数据存储目录
② 挂载/tmp/mysql/conf/hmy.cnf到mysql容器的配置文件
③ 设置MySQL密码
$ docker run \
--name some-mysql
-p 3306:3306
-v /tmp/mysql/conf/hmy.cnf:
-v /tmp/mysql/data:
-e MYSQL_ROOT_PASSWORD=my-secret-pw
-d \
mysql:8.0【9】Docker自定义镜像
## .镜像结构
镜像是将应用程序及其需要的系统函数库、环境、配置、依赖打包而成。
我们以MySQL为例,来看看镜像的组成结构:

简单来说,镜像就是在系统函数库、运行环境基础上,添加应用程序文件、配置文件、依赖文件等组合,然后编写好启动脚本打包在一起形成的文件。
我们要构建镜像,其实就是实现上述打包的过程。

【10】如何构建Dockerfile语法
3.3.1.基于Ubuntu构建Java项目
需求:基于Ubuntu镜像构建一个新镜像,运行一个java项目
-
步骤1:新建一个空文件夹docker-demo
-
步骤2:拷贝课前资料中的docker-demo.jar文件到docker-demo这个目录
-
步骤3:拷贝课前资料中的jdk8.tar.gz文件到docker-demo这个目录
-
步骤4:拷贝课前资料提供的Dockerfile到docker-demo这个目录
其中的内容如下:
# 指定基础镜像 FROM ubuntu:16.04 # 配置环境变量,JDK的安装目录 ENV JAVA_DIR=/usr/local # 拷贝jdk和java项目的包 COPY ./jdk8.tar.gz $JAVA_DIR/ COPY ./docker-demo.jar /tmp/app.jar # 安装JDK RUN cd $JAVA_DIR \ && tar -xf ./jdk8.tar.gz \ && mv ./jdk1.8.0_144 ./java8 # 配置环境变量 ENV JAVA_HOME=$JAVA_DIR/java8 ENV PATH=$PATH:$JAVA_HOME/bin # 暴露端口 EXPOSE 8090 # 入口,java项目的启动命令 ENTRYPOINT java -jar /tmp/app.jar
-
步骤5:进入docker-demo
将准备好的docker-demo上传到虚拟机任意目录,然后进入docker-demo目录下
-
步骤6:运行命令:
docker build -t javaweb:1.0 .
最后访问 http://192.168.150.101:8090/hello/count,其中的ip改成你的虚拟机ip
3.3.2.基于java8构建Java项目
虽然我们可以基于Ubuntu基础镜像,添加任意自己需要的安装包,构建镜像,但是却比较麻烦。所以大多数情况下,我们都可以在一些安装了部分软件的基础镜像上做改造。
例如,构建java项目的镜像,可以在已经准备了JDK的基础镜像基础上构建。
需求:基于java:8-alpine镜像,将一个Java项目构建为镜像
实现思路如下:
-
① 新建一个空的目录,然后在目录中新建一个文件,命名为Dockerfile
-
② 拷贝课前资料提供的docker-demo.jar到这个目录中
-
③ 编写Dockerfile文件:
-
a )基于java:8-alpine作为基础镜像
-
b )将app.jar拷贝到镜像中
-
c )暴露端口
-
d )编写入口ENTRYPOINT
内容如下:
FROM java:8-alpine COPY ./app.jar /tmp/app.jar EXPOSE 8090 ENTRYPOINT java -jar /tmp/app.jar
-
-
④ 使用docker build命令构建镜像
-
⑤ 使用docker run创建容器并运行
3.4.小结
小结:
-
Dockerfile的本质是一个文件,通过指令描述镜像的构建过程
-
Dockerfile的第一行必须是FROM,从一个基础镜像来构建
-
基础镜像可以是基本操作系统,如Ubuntu。也可以是其他人制作好的镜像,例如:java:8-alpine
【10】.Docker-Compose
Docker Compose可以基于Compose文件帮我们快速的部署分布式应用,而无需手动一个个创建和运行容器!
4.1.初识DockerCompose
Compose文件是一个文本文件,通过指令定义集群中的每个容器如何运行。格式如下:
version: "3.8" services: mysql: image: mysql:5.7.25 environment: MYSQL_ROOT_PASSWORD: 123 volumes: - "/tmp/mysql/data:/var/lib/mysql" - "/tmp/mysql/conf/hmy.cnf:/etc/mysql/conf.d/hmy.cnf" web: build: . ports: - "8090:8090"
上面的Compose文件就描述一个项目,其中包含两个容器:
-
mysql:一个基于
mysql:5.7.25镜像构建的容器,并且挂载了两个目录 -
web:一个基于
docker build临时构建的镜像容器,映射端口时8090
DockerCompose的详细语法参考官网:Compose specification | Docker Documentation
其实DockerCompose文件可以看做是将多个docker run命令写到一个文件,只是语法稍有差异。
4.2.安装DockerCompose
参考课前资料
4.3.部署微服务集群
需求:将之前学习的cloud-demo微服务集群利用DockerCompose部署
实现思路:
① 查看课前资料提供的cloud-demo文件夹,里面已经编写好了docker-compose文件
② 修改自己的cloud-demo项目,将数据库、nacos地址都命名为docker-compose中的服务名
③ 使用maven打包工具,将项目中的每个微服务都打包为app.jar
④ 将打包好的app.jar拷贝到cloud-demo中的每一个对应的子目录中
⑤ 将cloud-demo上传至虚拟机,利用 docker-compose up -d 来部署
4.3.1.compose文件
查看课前资料提供的cloud-demo文件夹,里面已经编写好了docker-compose文件,而且每个微服务都准备了一个独立的目录:
内容如下:
version: "3.2" services: nacos: image: nacos/nacos-server environment: MODE: standalone ports: - "8848:8848" mysql: image: mysql:5.7.25 environment: MYSQL_ROOT_PASSWORD: 123 volumes: - "$PWD/mysql/data:/var/lib/mysql" - "$PWD/mysql/conf:/etc/mysql/conf.d/" userservice: build: ./user-service orderservice: build: ./order-service gateway: build: ./gateway ports: - "10010:10010"
可以看到,其中包含5个service服务:
-
nacos:作为注册中心和配置中心-
image: nacos/nacos-server: 基于nacos/nacos-server镜像构建 -
environment:环境变量-
MODE: standalone:单点模式启动
-
-
ports:端口映射,这里暴露了8848端口
-
-
mysql:数据库-
image: mysql:5.7.25:镜像版本是mysql:5.7.25 -
environment:环境变量-
MYSQL_ROOT_PASSWORD: 123:设置数据库root账户的密码为123
-
-
volumes:数据卷挂载,这里挂载了mysql的data、conf目录,其中有我提前准备好的数据
-
-
userservice、orderservice、gateway:都是基于Dockerfile临时构建的
查看mysql目录,可以看到其中已经准备好了cloud_order、cloud_user表:
查看微服务目录,可以看到都包含Dockerfile文件:
内容如下:
FROM java:8-alpine COPY ./app.jar /tmp/app.jar ENTRYPOINT java -jar /tmp/app.jar
4.3.2.修改微服务配置
因为微服务将来要部署为docker容器,而容器之间互联不是通过IP地址,而是通过容器名。这里我们将order-service、user-service、gateway服务的mysql、nacos地址都修改为基于容器名的访问。
如下所示:
spring: datasource: url: jdbc:mysql://mysql:3306/cloud_order?useSSL=false username: root password: 123 driver-class-name: com.mysql.jdbc.Driver application: name: orderservice cloud: nacos: server-addr: nacos:8848 # nacos服务地址
4.3.3.打包
接下来需要将我们的每个微服务都打包。因为之前查看到Dockerfile中的jar包名称都是app.jar,因此我们的每个微服务都需要用这个名称。
可以通过修改pom.xml中的打包名称来实现,每个微服务都需要修改:
app org.springframework.boot spring-boot-maven-plugin
打包后:
4.3.4.拷贝jar包到部署目录
编译打包好的app.jar文件,需要放到Dockerfile的同级目录中。注意:每个微服务的app.jar放到与服务名称对应的目录,别搞错了。
user-service:
order-service:
gateway:
4.3.5.部署
最后,我们需要将文件整个cloud-demo文件夹上传到虚拟机中,理由DockerCompose部署。
上传到任意目录:
部署:
进入cloud-demo目录,然后运行下面的命令:
docker-compose up -d
【11】Docker镜像仓库
5.1.搭建私有镜像仓库
参考课前资料《CentOS7安装Docker.md》
5.2.推送、拉取镜像
推送镜像到私有镜像服务必须先tag,步骤如下:
① 重新tag本地镜像,名称前缀为私有仓库的地址:192.168.150.101:8080/
docker tag nginx:latest 192.168.150.101:8080/nginx:1.0
② 推送镜像
docker push 192.168.150.101:8080/nginx:1.0
③ 拉取镜像
docker pull 192.168.150.101:8080/nginx:1.0
MQ 消息队列
同步通讯 一对一聊天 视频聊天
异步通讯 多对多 文字聊天
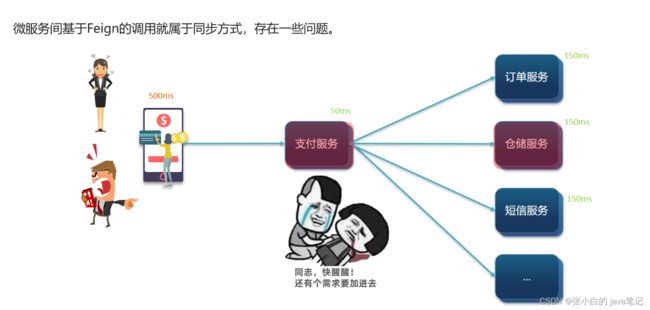
浪费资源
挂掉就没了
### 1.1.1.同步通讯
我们之前学习的Feign调用就属于同步方式,虽然调用可以实时得到结果,但存在下面的问题:
总结:
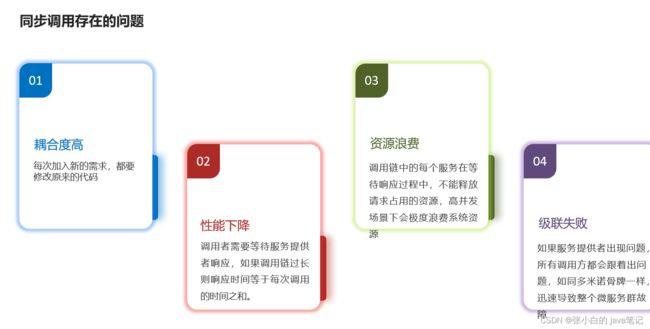
【1】同步调用
的优点:
- 时效性较强,可以立即得到结果
同步调用的问题:
- 耦合度高
- 性能和吞吐能力下降
- 有额外的资源消耗
- 有级联失败问题
【2】异步调用




异步调用则可以避免上述问题:
我们以购买商品为例,用户支付后需要调用订单服务完成订单状态修改,调用物流服务,从仓库分配响应的库存并准备发货。
在事件模式中,支付服务是事件发布者(publisher),在支付完成后只需要发布一个支付成功的事件(event),事件中带上订单id。
订单服务和物流服务是事件订阅者(Consumer),订阅支付成功的事件,监听到事件后完成自己业务即可。
为了解除事件发布者与订阅者之间的耦合,两者并不是直接通信,而是有一个中间人(Broker)。发布者发布事件到Broker,不关心谁来订阅事件。订阅者从Broker订阅事件,不关心谁发来的消息。
Broker 是一个像数据总线一样的东西,所有的服务要接收数据和发送数据都发到这个总线上,这个总线就像协议一样,让服务间的通讯变得标准和可控。
好处:
-
吞吐量提升:无需等待订阅者处理完成,响应更快速
-
故障隔离:服务没有直接调用,不存在级联失败问题
-
调用间没有阻塞,不会造成无效的资源占用
-
耦合度极低,每个服务都可以灵活插拔,可替换
-
流量削峰:不管发布事件的流量波动多大,都由Broker接收,订阅者可以按照自己的速度去处理事件
缺点:
-
架构复杂了,业务没有明显的流程线,不好管理
-
需要依赖于Broker的可靠、安全、性能
好在现在开源软件或云平台上 Broker 的软件是非常成熟的,比较常见的一种就是我们今天要学习的MQ技术。
【3】多种MQ技术对比:
MQ,中文是消息队列(MessageQueue),字面来看就是存放消息的队列。也就是事件驱动架构中的Broker。
比较常见的MQ实现:
-
ActiveMQ
-
RabbitMQ
-
RocketMQ
-
Kafka
几种常见MQ的对比:
| RabbitMQ | ActiveMQ | RocketMQ | Kafka | |
|---|---|---|---|---|
| 公司/社区 | Rabbit | Apache | 阿里 | Apache |
| 开发语言 | Erlang | Java | Java | Scala&Java |
| 协议支持 | AMQP,XMPP,SMTP,STOMP | OpenWire,STOMP,REST,XMPP,AMQP | 自定义协议 | 自定义协议 |
| 可用性 | 高 | 一般 | 高 | 高 |
| 单机吞吐量 | 一般 | 差 | 高 | 非常高 |
| 消息延迟 | 微秒级 | 毫秒级 | 毫秒级 | 毫秒以内 |
| 消息可靠性 | 高 | 一般 | 高 | 一般 |
追求可用性:Kafka、 RocketMQ 、RabbitMQ
追求可靠性:RabbitMQ、RocketMQ
追求吞吐能力:RocketMQ、Kafka
追求消息低延迟:RabbitMQ、Kafka
【4】快速入门
2.1.安装RabbitMQ
# RabbitMQ部署指南
# 1.单机部署
我们在Centos7虚拟机中使用Docker来安装。
## 1.1.下载镜像
方式一:在线拉取
``` sh
docker pull rabbitmq:3-management
```
方式二:从本地加载
在课前资料已经提供了镜像包:

上传到虚拟机中后,使用命令加载镜像即可:
```sh
docker load -i mq.tar
```
## 1.2.安装MQ
执行下面的命令来运行MQ容器:
```sh
docker run \
-e RABBITMQ_DEFAULT_USER=itcast \
-e RABBITMQ_DEFAULT_PASS=123321 \
--name mq \
--hostname mq1 \
-p 15672:15672 \ (管理平台端口)
-p 5672:5672 \ (消息管理端口)
-d \
rabbitmq:3-management
```
# 2.集群部署
接下来,我们看看如何安装RabbitMQ的集群。
## 2.1.集群分类
在RabbitMQ的官方文档中,讲述了两种集群的配置方式:
- 普通模式:普通模式集群不进行数据同步,每个MQ都有自己的队列、数据信息(其它元数据信息如交换机等会同步)。例如我们有2个MQ:mq1,和mq2,如果你的消息在mq1,而你连接到了mq2,那么mq2会去mq1拉取消息,然后返回给你。如果mq1宕机,消息就会丢失。
- 镜像模式:与普通模式不同,队列会在各个mq的镜像节点之间同步,因此你连接到任何一个镜像节点,均可获取到消息。而且如果一个节点宕机,并不会导致数据丢失。不过,这种方式增加了数据同步的带宽消耗。
我们先来看普通模式集群。
## 2.2.设置网络
首先,我们需要让3台MQ互相知道对方的存在。
分别在3台机器中,设置 /etc/hosts文件,添加如下内容:
```
192.168.150.101 mq1
192.168.150.102 mq2
192.168.150.103 mq3
```
并在每台机器上测试,是否可以ping通对方:
服务器 - 轻量应用服务器 - 控制台 (tencent.com)
腾讯云防火墙配置 防止端口问题

账号密码在上面
其他信息
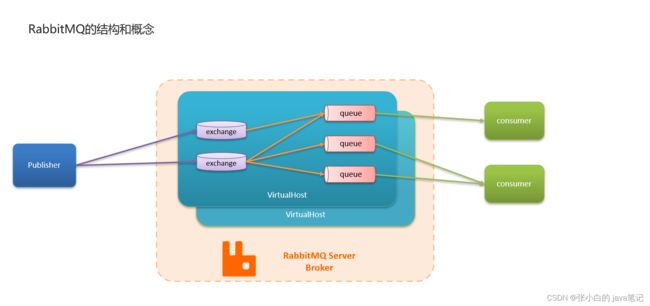
RabbitMQ中的一些角色:
- publisher:生产者
- consumer:消费者
- exchange个:交换机,负责消息路由
- queue:队列,存储消息
- virtualHost:虚拟主机,隔离不同租户的exchange、queue、消息的隔离
常见消息模型
实践 导入




基本消息队列的消息发送流程:
1. 建立connection
2. 创建channel
3. 利用channel声明队列
4. 利用channel向队列发送消息
基本消息队列的消息接收流程:
1. 建立connection
2. 创建channel
3. 利用channel声明队列
4. 定义consumer的消费行为handleDelivery()
5. 利用channel将消费者与队列绑定
SpringAMQP
# .SpringAMQP
SpringAMQP是基于RabbitMQ封装的一套模板,并且还利用SpringBoot对其实现了自动装配,使用起来非常方便。
SpringAmqp的官方地址:https://spring.io/projects/spring-amqp
SpringAMQP提供了三个功能:
- 自动声明队列、交换机及其绑定关系
- 基于注解的监听器模式,异步接收消息
- 封装了RabbitTemplate工具,用于发送消