仅需6GB显存,拥有专属AI代码助手
清华GLM技术团队打造的多语言代码生成模型CodeGeeX近期更新了新的开源版本「CodeGeeX2-6B」。CodeGeeX2是多语言代码生成模型CodeGeeX的第二代模型,不同于一代 CodeGeeX ,CodeGeeX2 是基于 ChatGLM2 架构加入代码预训练实现。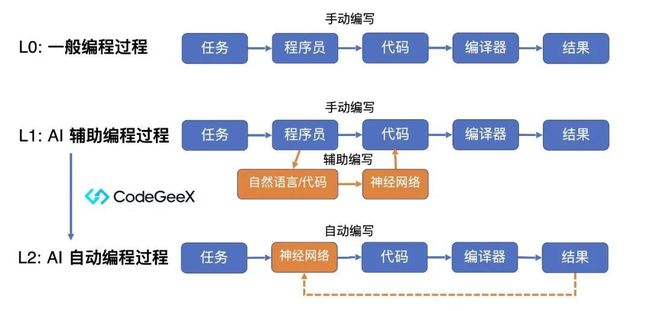 得益于 ChatGLM2 的更优性能,CodeGeeX2 在多项指标上取得性能提升(+107% > CodeGeeX),仅60亿参数即超过150亿参数的 StarCoder-15B 近10%。相较于一代模型,二代具有更强大的代码能力、更优秀的模型特性、更全面的AI编程助手和更开放的协议。
得益于 ChatGLM2 的更优性能,CodeGeeX2 在多项指标上取得性能提升(+107% > CodeGeeX),仅60亿参数即超过150亿参数的 StarCoder-15B 近10%。相较于一代模型,二代具有更强大的代码能力、更优秀的模型特性、更全面的AI编程助手和更开放的协议。
CodeGeeX2 特性
- 更强大的代码能力基于 ChatGLM2-6B 基座语言模型,CodeGeeX2-6B 进一步经过了 600B 代码数据预训练,相比一代模型,在代码能力上全面提升,HumanEval-X 评测集的六种编程语言均大幅提升 (Python +57%, C++ +71%, Java +54%, JavaScript +83%, Go +56%, Rust +321%),在Python上达到 35.9% 的 Pass@1 一次通过率,超越规模更大的 StarCoder-15B。
- 更优秀的模型特性继承 ChatGLM2-6B 模型特性,CodeGeeX2-6B 更好支持中英文输入,支持最大 8192 序列长度,推理速度较一代 CodeGeeX-13B 大幅提升,量化后仅需6GB显存即可运行,支持轻量级本地化部署。
- 更全面的AI编程助手CodeGeeX插件(VS Code, Jetbrains)后端升级,支持超过100种编程语言,新增上下文补全、跨文件补全等实用功能。结合 Ask CodeGeeX 交互式AI编程助手,支持中英文对话解决各种编程问题,包括且不限于代码解释、代码翻译、代码纠错、文档生成等,帮助程序员更高效开发。
- 更开放的协议CodeGeeX2-6B 权重对学术研究完全开放,可申请商业使用。
如何快速使用CodeGeeX2
GLM团队开发了支持 VS Code、 IntelliJ IDEA、PyCharm、GoLand、WebStorm、Android Studio 等IDE的 CodeGeeX 插件。在插件中,可以更直接地体验到 CodeGeeX2 模型在代码生成与补全、添加注释、代码翻译及技术问答方面的能力为开发效率带来的提升。插件下载:https://codegeex.cn/zh-CN/downloadGuide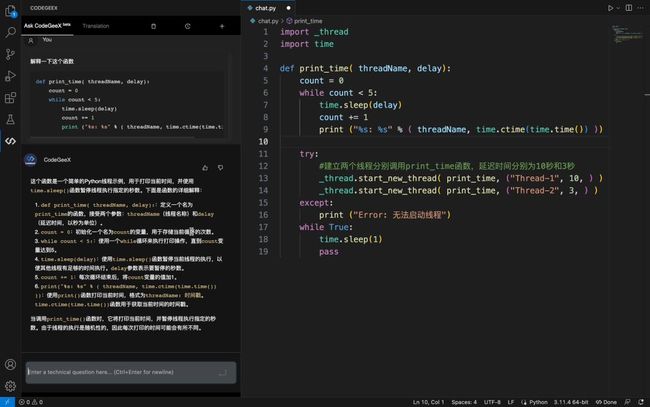
CodeGeeX2推理及量化教程
下载本仓库并使用pip安装环境依赖:
git clone https://github.com/THUDM/CodeGeeX2cd CodeGeeX2pip install -r requirements.txt使用transformers快速调用CodeGeeX2-6B:from transformers import AutoTokenizer, AutoModeltokenizer = AutoTokenizer.from_pretrained("THUDM/codegeex2-6b", trust_remote_code=True)model = AutoModel.from_pretrained("THUDM/codegeex2-6b", trust_remote_code=True, device='cuda') # 如使用CPU推理,device='cpu'model = model.eval()# CodeGeeX2支持100种编程语言,加入语言标签引导生成相应的语言prompt = "# language: Python\n# write a bubble sort function\n"inputs = tokenizer.encode(prompt, return_tensors="pt").to(model.device)outputs = model.generate(inputs, max_length=256, top_k=1) # 示例中使用greedy decoding,检查输出结果是否对齐response = tokenizer.decode(outputs[0])>>> print(response)# language: Python# write a bubble sort functiondef bubble_sort(list): for i in range(len(list) - 1): for j in range(len(list) - 1): if list[j] > list[j + 1]: list[j], list[j + 1] = list[j + 1], list[j] return listprint(bubble_sort([5, 2, 1, 8, 4]))CodeGeeX2目前支持在多种不同平台上进行推理,包括CPU推理,多卡推理,加速推理等。
- 多精度/量化推理
CodeGeeX2 使用BF16训练,推理时支持BF16/FP16/INT8/INT4,可以根据显卡显存选择合适的精度格式:
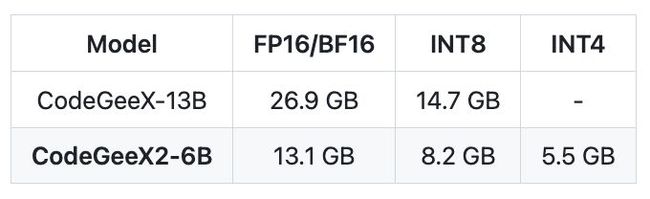 默认使用BF16精度进行推理,如显卡不支持BF16(❗️如使用错误的格式,推理结果将出现乱码),需要转换为FP16格式:model = AutoModel.from_pretrained(model_path, trust_remote_code=True).half().to("cuda")
默认使用BF16精度进行推理,如显卡不支持BF16(❗️如使用错误的格式,推理结果将出现乱码),需要转换为FP16格式:model = AutoModel.from_pretrained(model_path, trust_remote_code=True).half().to("cuda")
- 多GPU推理
用gpus.py实现多GPU推理:from gpus import load_model_on_gpusmodel = load_model_on_gpus("THUDM/codegeex2-6b", num_gpus=2)
- Mac推理
对于搭载了 Apple Silicon 或者 AMD GPU 的 Mac,可以使用 MPS 后端运行。参考 Apple 的官方说明安装 PyTorch-Nightly(正确的版本号应该是2.x.x.dev2023xxxx,如2.1.0.dev20230729):pip3 install --pre torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/nightly/cpu在 MacOS 上只支持从本地加载模型(提前下载权重codegeex2-6b,codegeex2-6b-int4),支持FP16/INT8/INT4格式,并使用 mps 后端:model = AutoModel.from_pretrained(model_path, trust_remote_code=True).half().to('mps')
- fastllm加速推理
可以使用fastllm对 CodeGeeX2 进行加速,fastllm是目前支持GLM架构的最快开源框架。首先安装fastllm_pytools:git clone https://github.com/ztxz16/fastllmcd fastllmmkdir buildcd build# 使用GPU编译,需要添加CUDA路径:export CUDA_HOME=/usr/local/cuda/bin:$PATH,export PATH=$PATH:$CUDA_HOME/bincmake .. -DUSE_CUDA=ON # 如果不使用GPU编译 cmake .. -DUSE_CUDA=OFFmake -jcd tools && python setup.py install # 确认安装是否成功,在python中 import fastllm_pytools 不报错
将huggingface转换成fastllm格式:
# 原本的调用代码from transformers import AutoTokenizer, AutoModeltokenizer = AutoTokenizer.from_pretrained("THUDM/codegeex2-6b", trust_remote_code=True)model = AutoModel.from_pretrained("THUDM/codegeex2-6b", trust_remote_code=True)# 加入下面这两行,将huggingface模型转换成fastllm模型from fastllm_pytools import llmmodel = llm.from_hf(model, tokenizer, dtype="float16") # dtype支持 "float16", "int8", "int4"
fastllm中模型接口和huggingface不完全相同,可以参考demo/run_demo.py中的相关实现:
model.direct_query = Trueoutputs = model.chat(tokenizer, prompt, max_length=out_seq_length, top_p=top_p, top_k=top_k, temperature=temperature)response = outputs[0]