python3基础知识复习 --异步IO(asyncio,aiohttp)
异步IO
-
同步IO模型:等待每个IO完成再进行下一步,一旦碰到IO堵塞当前线程就会导致其他代码无法执行。而且他的代码是无法实现异步IO模型的。
-
异步IO模型:代码只发出IO指令,并不等待结果,之后通过一个消息循环,主线程不断地重复“读取消息-处理消息”这一过程,当IO返回结果时再通知CPU处理。
-
IO问题指的是CPU高速执行能力和IO设备的龟速严重不匹配,多线程和多进程只是解决这一问题的一种方法。异步IO模型是另一种方法。
-
对于大多数IO密集型的应用程序,使用异步IO将大大提升系统的多任务处理能力。
-
协程Coroutine
- 协程又称微线程,纤程
- 子程序: 就是函数,在所有语言中都是层级调用A–>B–>C–>B–>A, 通过栈实现,一个线程执行一个子程序。子程序的调用总是一个入口,一次返回,顺序是明确的。
- 协程的调用与子程序不同,它看上去也是子程序,但执行过程中,在子程序内部可中断,然后转而执行别的子程序,在适当的时候再返回来接着执行。但注意,在一个子程序中中断,去执行其他子程序,不是函数调用,有点类似CPU的中断。
- 协程特点是只在一个线程执行,相比多线程的效率更高(没有线程切换的开销), 然后不需要多线程的锁机制,因为只有一个线程就没有同时写变量冲突,控制共享资源不加锁,只需判断状态。
- 多进程+协程,既充分利用多核CPU,又充分发挥协程的高效率,可获得极高的性能。
- Python对协程的支持是通过generator实现的。
yield不但可以返回一个值,它还可以接收调用者发出的参数。
协程例子:
def consumer():
r = ''
while True:
n = yield r # 赋值语句,先计算 = 右边的yield语句,yield执行完以后,进入暂停,而赋值语句在下一次启动生成器的时候首先被执行
if not n:
return
print('[CONSUMER] Consuming %s...' % n)
r = '200 OK'
def produce(c):
c.send(None) # 等同于next(generator)的功能
n = 0
while n < 5:
n = n + 1
print('[PRODUCER] Producing %s...' % n)
r = c.send(n) # yield接收调用者发出的参数
print('[PRODUCER] Consumer return: %s' % r)
c.close()
c = consumer()
produce(c)
但注意,在一个生成器函数未启动之前,是不能传递值进去。也就是说在使用c.send(n)之前,必须先使用c.send(None)或者next(c)来返回生成器的第一个值。
执行过程:
第一步:执行 c.send(None),启动生成器返回第一个值,n = yield r,此时 r 为空,n 还未赋值,然后生成器暂停,等待下一次启动。
第二步:生成器返回空值后进入暂停,produce(c) 接着往下运行,进入While循环,此时 n 为1,所以打印:
[PRODUCER] Producing 1...
第三步:produce(c) 往下运行到 r = c.send(1),再次启动生成器,并传入了参数1,而生成器从上次n的赋值语句开始执行,n 被赋值为1,n存在,if 语句不执行,然后打印:
[CONSUMER] Consuming 1...
接着r被赋值为'200 OK',然后又进入循环,执行n = yield r,返回生成器的第二个值,'200 OK',然后生成器进入暂停,等待下一次启动。
第四步:生成器返回'200 OK'进入暂停后,produce(c)往下运行,进入r的赋值语句,r被赋值为'200 OK',接着往下运行,打印:
[PRODUCER] Consumer return: 200 OK
以此类推…
当n为5跳出循环后,使用c.close() 结束生成器的生命周期,然后程序运行结束。
asyncio模块
- 使用yield from和@asyncio.coroutine实现协程
在Python3.4中,协程都是通过使用yield from和asyncio模块中的@asyncio.coroutine来实现的。asyncio专门被用来实现异步IO操作。(协程底层就是用生成器实现的)
(1)什么是yield from?和yield有什么区别?
yield在生成器中有中断的功能,可以传出值,也可以从函数外部接收值,而yield from的实现就是简化了yield操作。可以从生成器中依次取出,而且内部已经实现大部分异常处理。
titles = ['P','J','C+']
def generator_1(titles):
yield titles
def generator_2(titles):
yield from titles
for title in generator_1(titles):
print('生成器1:',title)
for title in generator_2(titles):
print('生成器2:',title)
>>>生成器1: ['P', 'J', 'C+']
生成器2: P
生成器2: J
生成器2: C+
### Summary ###
yield from titles
# 等价于下面的
for title in titles:
yield title
(2)如何结合@asyncio.coroutine实现协程
在协程中,只要是和IO任务类似的、耗费时间的任务都需要使用yield from来进行中断,达到异步功能!
我们在上面那个同步IO任务的代码中修改成协程的用法如下:
import time
import asyncio
@asyncio.coroutine # 标志协程的装饰器
def taskIO_1():
print('开始运行IO任务1...')
yield from asyncio.sleep(2) # asyncio模块提供的生成器函数表示该任务耗时2s,在此处中断
print('IO任务1已完成,耗时2s')
return taskIO_1.__name__
@asyncio.coroutine # 标志协程的装饰器
def taskIO_2():
print('开始运行IO任务2...')
yield from asyncio.sleep(3) # 假设该任务耗时3s,中断
print('IO任务2已完成,耗时3s')
return taskIO_2.__name__
@asyncio.coroutine # 标志协程的装饰器
def main(): # 调用方
tasks = [taskIO_1(), taskIO_2()] # 把所有任务添加到task中
done,pending = yield from asyncio.wait(tasks) # 子生成器
for r in done: # done和pending都是一个任务,所以返回结果需要逐个调用result()
print('协程无序返回值:'+ r.result())
if __name__ == '__main__':
start = time.time()
loop = asyncio.get_event_loop() # 创建一个事件循环对象loop
try:
loop.run_until_complete(main()) # 完成事件循环,直到最后一个任务结束
finally:
loop.close() # 结束事件循环
print('所有IO任务总耗时%.5f秒' % float(time.time()-start))
执行结果如下:
开始运行IO任务1...
开始运行IO任务2...
IO任务1已完成,耗时2s
IO任务2已完成,耗时3s
协程无序返回值:taskIO_2
协程无序返回值:taskIO_1
所有IO任务总耗时3.00209秒
【执行过程】:
-
上面代码先通过get_event_loop()获取了一个标准事件循环loop(因为是一个,所以协程是单线程)
-
然后,我们通过run_until_complete(main())来运行协程(此处把调用方协程main()作为参数,调用方负责调用其他委托生成器),run_until_complete的特点就像该函数的名字,直到循环事件的所有事件都处理完才能完整结束。
-
进入调用方协程,我们把多个任务[taskIO_1()和taskIO_2()]放到一个task列表中,可理解为打包任务。
-
现在,我们使用asyncio.wait(tasks)来获取一个awaitable objects即可等待对象的集合(此处的aws是协程的列表),并发运行传入的aws,同时通过yield from返回一个包含(done, pending)的元组,done表示已完成的任务列表,pending表示未完成的任务列表;如果使用asyncio.as_completed(tasks)则会按完成顺序生成协程的迭代器(常用于for循环中),因此当你用它迭代时,会尽快得到每个可用的结果。【此外,当轮询到某个事件时(如taskIO_1()),直到遇到该任务中的yield from中断,开始处理下一个事件(如taskIO_2())),当yield from后面的子生成器完成任务时,该事件才再次被唤醒】
-
因为done里面有我们需要的返回结果,但它目前还是个任务列表,所以要取出返回的结果值,我们遍历它并逐个调用result()取出结果即可。(注:对于asyncio.wait()和asyncio.as_completed()返回的结果均是先完成的任务结果排在前面,所以此时打印出的结果不一定和原始顺序相同,但使用gather()的话可以得到原始顺序的结果集,两者更详细的案例说明见此)
-
最后我们通过loop.close()关闭事件循环。
综上所述:协程的完整实现是靠①事件循环+②协程。
async/await
为了简化并更好地标识异步IO(避免协程和生成器混淆),从Python 3.5开始引入了新的语法async和await,可以让coroutine的代码更简洁易读。
请注意,async和await是针对coroutine的新语法,要使用新的语法,只需要做两步简单的替换:
- 把
@asyncio.coroutine替换为async; - 把
yield from替换为await。
import time
import asyncio
async def taskIO_1():
print('开始运行IO任务1...')
await asyncio.sleep(2) # 假设该任务耗时2s
print('IO任务1已完成,耗时2s')
return taskIO_1.__name__
async def taskIO_2():
print('开始运行IO任务2...')
await asyncio.sleep(3) # 假设该任务耗时3s
print('IO任务2已完成,耗时3s')
return taskIO_2.__name__
async def main(): # 调用方
tasks = [taskIO_1(), taskIO_2()] # 把所有任务添加到task中
done,pending = await asyncio.wait(tasks) # 子生成器
for r in done: # done和pending都是一个任务,所以返回结果需要逐个调用result()
print('协程无序返回值:'+r.result())
if __name__ == '__main__':
start = time.time()
loop = asyncio.get_event_loop() # 创建一个事件循环对象loop
try:
loop.run_until_complete(main()) # 完成事件循环,直到最后一个任务结束
finally:
loop.close() # 结束事件循环
print('所有IO任务总耗时%.5f秒' % float(time.time()-start))
多进程和多线程是内核级别的程序,而协程是函数级别的程序,是可以通过程序员进行调用的。以下是协程特性的总结:
| 协程 | 属性 |
|---|---|
| 所需线程 | 单线程 (因为仅定义一个loop,所有event均在一个loop中) |
| 编程方式 | 同步 |
| 实现效果 | 异步 |
| 是否需要锁机制 | 否 |
| 程序级别 | 函数级 |
| 实现机制 | 事件循环+协程 |
| 总耗时 | 最耗时事件的时间 |
| 应用场景 | IO密集型任务等 |
其他资料:
-
Async IO in Python: A Complete Walkthrough – Real Python
-
tqdm库实现进度条,这个协程就像asyncio.wait一样工作,不过会显示一个代表完成度的进度条。详情见:python进度可视化
aiohttp
asyncio可以实现单线程并发IO操作, 用在服务器端,比如web服务器处理多个http连接,用单线程+coroutine实现多用户的高并发支持。 asyncio实现了TCP、UDP、SSL等协议,aiohttp则是基于asyncio实现的HTTP框架。
Welcome to AIOHTTP — aiohttp 3.8.1 documentation
Client example:
import aiohttp
import asyncio
async def main():
async with aiohttp.ClientSession() as session:
async with session.get('http://python.org') as response:
print("Status:", response.status)
print("Content-type:", response.headers['content-type'])
html = await response.text()
print("Body:", html[:15], "...")
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
This prints:
Status: 200
Content-type: text/html; charset=utf-8
Body: ...
Server Example:
需求:然后编写一个HTTP服务器,分别处理以下URL:
/- 首页返回b';Index
'/hello/{name}- 根据URL参数返回文本hello, %s!。
代码如下:
"""Django style"""
import asyncio
from aiohttp import web
async def index(request):
await asyncio.sleep(0.5) # 假装去做其他事
return web.Response(body=b'Index
', content_type = 'text/html')
async def hello(request):
await asyncio.sleep(0.5)
text = 'hello, %s!
' % request.match_info['name'] # 得到网址上的输入
return web.Response(body=text.encode('utf-8'))
async def init(loop):
app = web.Application(loop=loop)
app.router.add_route('GET', '/', index)
app.router.add_route('GET', '/hello/{name}', hello)
srv = await loop.create_server(app.make_handler(), '127.0.0.1', 8000)
print('Server started at http://127.0.0.1:8000...')
return srv
loop = asyncio.get_event_loop()
loop.run_until_complete(init(loop))
loop.run_forever()
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""Flasky style"""
import asyncio
from aiohttp import web
routes = web.RouteTableDef()
@routes.get('/')
async def index(request):
await asyncio.sleep(1)
return web.Response(body = b'Index
', content_type = 'text/html')
@routes.get('/signin')
async def signin_form(request):
await asyncio.sleep(1)
form = \
"""
"""
return web.Response(body = form.encode('utf-8'), content_type = 'text/html')
@routes.post('/signin')
async def signin(request):
data = await request.post() # 得到表单数据
if data['username'] == 'admin' and data['password'] == 'password':
return web.Response(body = b'Hello admin
', content_type='text/html')
else:
return web.Response(body = b'Bad username or password
', content_type = 'text/html')
def main():
app = web.Application()
app.add_routes(routes)
web.run_app(app, host='127.0.0.1', port='8000') # 不指定 host:port时,默认为0.0.0.0:8080
if __name__ == "__main__":
main()
Python实战异步爬虫(协程)+分布式爬虫(多进程)_SL_World的博客-CSDN博客_python异步爬虫
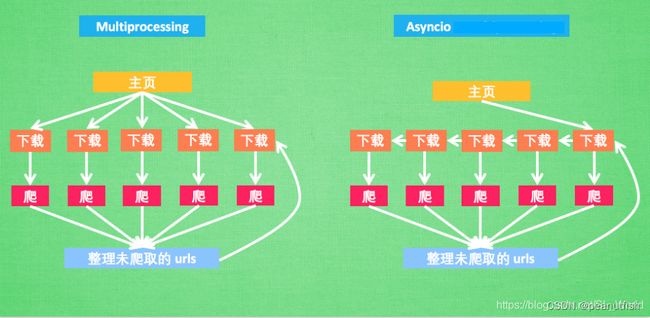
NOTE: 例子中给的AAAI顶会中10篇论文已经不能用了,我这里用python的网站代替。
-
普通版爬虫(这里提供了3中解析网页方法,xpath(lxml), beautifulsoup, re)
#!/usr/bin/env python3 # -*- coding: utf-8 -*- import time import requests from lxml import etree from bs4 import BeautifulSoup import re import logging urls = [ 'https://docs.python.org/zh-cn/3/library/intro.html', 'https://docs.python.org/zh-cn/3/library/functions.html', 'https://docs.python.org/zh-cn/3/library/constants.html', 'https://docs.python.org/zh-cn/3/library/stdtypes.html', 'https://docs.python.org/zh-cn/3/library/exceptions.html', 'https://docs.python.org/zh-cn/3/library/text.html', 'https://docs.python.org/zh-cn/3/library/string.html', 'https://docs.python.org/zh-cn/3/library/re.html', 'https://docs.python.org/zh-cn/3/library/difflib.html', 'https://docs.python.org/zh-cn/3/library/textwrap.html' ] # method1: xpath def get_title(url, cnt): response = requests.get(url) html = response.content # 根据网页的结构不同,xpath语句不同 title = etree.HTML(html).xpath('//title/text()') print('The %dth title: %s' % (cnt, ''.join(title))) """ # method2: beautifulsoup --速度最慢(要导入全html) def get_title(url, cnt): response = requests.get(url) html = response.content bs = BeautifulSoup(html, 'html.parser') print('The %dth title: %s' % (cnt, bs.title.string)) """ """ # method3 RE def get_title(url, cnt): response = requests.get(url) response.encoding = 'utf-8' # 按照utf-8解码response html = response.text r = re.compile(r'(.+) ') result = r.findall(html) print('The %dth title: %s' % (cnt, ''.join(result))) """ def main(): start1 = time.time() i = 0 for url in urls: i += 1 start = time.time() get_title(url, i) print('The %d th title used: %.5fs' % (i, float(time.time() - start))) print('Total used %.5f s for all sites' % float(time.time() - start1)) if __name__ == "__main__": try: main() except Exception as e: logging.exception(e) -
协程版爬虫(aiohttp)
#!/usr/bin/env python3 # -*- coding: utf-8 -*- import time import requests from lxml import etree import aiohttp import asyncio import logging urls = [ 'https://docs.python.org/zh-cn/3/library/intro.html', 'https://docs.python.org/zh-cn/3/library/functions.html', 'https://docs.python.org/zh-cn/3/library/constants.html', 'https://docs.python.org/zh-cn/3/library/stdtypes.html', 'https://docs.python.org/zh-cn/3/library/exceptions.html', 'https://docs.python.org/zh-cn/3/library/text.html', 'https://docs.python.org/zh-cn/3/library/string.html', 'https://docs.python.org/zh-cn/3/library/re.html', 'https://docs.python.org/zh-cn/3/library/difflib.html', 'https://docs.python.org/zh-cn/3/library/textwrap.html' ] # method1: xpath async def get_title(url): async with aiohttp.ClientSession() as session: async with session.get(url) as response: html = await response.text() title = etree.HTML(html).xpath('//title/text()') print('The title: %s' % (''.join(title))) def main(): loop = asyncio.get_event_loop() tasks = [get_title(url) for url in urls] loop.run_until_complete(asyncio.wait(tasks)) loop.close() if __name__ == "__main__": start = time.time() try: main() except Exception as e: logging.exception(e) print('Total used: %.5fs' % float(time.time() - start)) -
多进程版爬虫
#!/usr/bin/env python3 # -*- coding: utf-8 -*- import time import requests from lxml import etree import logging import multiprocessing urls = [ 'https://docs.python.org/zh-cn/3/library/intro.html', 'https://docs.python.org/zh-cn/3/library/functions.html', 'https://docs.python.org/zh-cn/3/library/constants.html', 'https://docs.python.org/zh-cn/3/library/stdtypes.html', 'https://docs.python.org/zh-cn/3/library/exceptions.html', 'https://docs.python.org/zh-cn/3/library/text.html', 'https://docs.python.org/zh-cn/3/library/string.html', 'https://docs.python.org/zh-cn/3/library/re.html', 'https://docs.python.org/zh-cn/3/library/difflib.html', 'https://docs.python.org/zh-cn/3/library/textwrap.html' ] # method1: xpath def get_title(url, cnt): response = requests.get(url) h = response.content title = etree.HTML(h).xpath('//title/text()') print('The %dth title: %s' % (cnt, ''.join(title))) def main(): print('There are %d cores in this PC' % multiprocessing.cpu_count()) p = multiprocessing.Pool(4) i = 0 for url in urls: i += 1 start = time.time() p.apply_async(get_title, args=(url, i)) p.close() # 关闭pool p.join() # 运行完所有子程序后才往后走 if __name__ == "__main__": start = time.time() try: main() except Exception as e: logging.exception(e) print('Total used %.5f s for all sites' % float(time.time() - start)) -
协程+多进程版爬虫(协程处理网页下载+多进程处理网页解析–最快)
#!/usr/bin/env python3 # -*- coding: utf-8 -*- import time import requests from lxml import etree import aiohttp import asyncio import logging import multiprocessing urls = [ 'https://docs.python.org/zh-cn/3/library/intro.html', 'https://docs.python.org/zh-cn/3/library/functions.html', 'https://docs.python.org/zh-cn/3/library/constants.html', 'https://docs.python.org/zh-cn/3/library/stdtypes.html', 'https://docs.python.org/zh-cn/3/library/exceptions.html', 'https://docs.python.org/zh-cn/3/library/text.html', 'https://docs.python.org/zh-cn/3/library/string.html', 'https://docs.python.org/zh-cn/3/library/re.html', 'https://docs.python.org/zh-cn/3/library/difflib.html', 'https://docs.python.org/zh-cn/3/library/textwrap.html' ] htmls = [] """协程处理网页下载""" # method1: xpath async def get_html(url): async with aiohttp.ClientSession() as session: async with session.get(url) as response: html = await response.text() htmls.append(html) def main_get_html(): loop = asyncio.get_event_loop() tasks = [get_html(url) for url in urls] loop.run_until_complete(asyncio.wait(tasks)) loop.close() """多进程处理网页解析""" def parse_html(html, cnt): title = etree.HTML(html).xpath('//title/text()') print('The %dth html got its title: %s' % (cnt, ''.join(title))) def multi_parse_html(): p = multiprocessing.Pool(4) i = 0 for html in htmls: i += 1 p.apply_async(parse_html, args=(html, i)) p.close() p.join() if __name__ == "__main__": start = time.time() try: main_get_html() multi_parse_html() except Exception as e: logging.exception(e) print('Total used: %.5fs' % float(time.time() - start))