调研:浅淡Django中多种序列化的方案及其性能
目前,web系统在前后端分离,通过API通信的大环境下,JSON序列化是后端必不可少的工作,在Jango中常用的序列化方案有多种,我很好奇它们之间有何种区别,什么情况下性能最佳,于是有了这次的调研。
- 首先弄清楚什么是序列化:
python已经集成了自己的序列化模块,如 json,其中的 json.dumps、和json.loads,就能实现字典和json字符串的转换。
实际上所谓的序列化,就是将字典转换成符合字典格式的字符串,反序列化则就是将其倒过来。
# type:dict
dict_object = {"id": 1, "name": "王二狗", "age": 18}
# type:str
json_str = '{"id": 1, "name": "王二狗", "age": 18}'- 介绍序列化方案前,展示下我定义的model:
from django.db import models
class PersonInfo(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=20)
age = models.IntegerField()
hireDate = models.DateField()
def __str__(self):
return str(self.id)
class Meta:
verbose_name = '人员信息'
class Vocation(models.Model):
id = models.AutoField(primary_key=True)
job = models.CharField(max_length=20)
title = models.CharField(max_length=20)
payment = models.IntegerField()
name_id = models.IntegerField()
def __str__(self):
return str(self.id)
class Meta:
verbose_name = '职业信息'
- Djano中自带的序列化方案和常见的第三方序列化方案:
- JsonResponse
- from django.core import serializers
- from rest_framework import serializers
其中,前两种,是Django自带的序列化方案,后者则是rest_framwork中所带的序列化方案,当然想要序列化还有很多方案,这里只列出几种常用的。
- 基础介绍:
JsonResponse 使用起来十分简单,只要将你要返回的内容以字典的形式传入其中,就能给前端返回相对应的Json字符串,如下图。
class TestView(View):
sql = "SELECT * FROM index_vocation"
column_list = ['id', 'job', 'title', 'payment', 'name_id']
def get(self, request):
raws, sql_code = django_sql(self.sql, dict_keys=self.column_list, types='list_dict')
return JsonResponse(data={'data': raws}, json_dumps_params={'ensure_ascii': False}, status=sql_code)其中的django_sql是我自己封装的一个数据库查询模块,它会执行SQL,并将结果格式化成:列表包裹着字典的形式 [{}...],结果如下:

这里需要注意的是,json_dumps_params={'ensure_ascii': False} 这个参数,如果不关闭的话,它会将返回参数中的中文,转换成ascii码。
from django.core import serializers:
serializers是django中自带的序列化方法,用法如下:
class TestViewDjango(View):
def get(self, request):
result = Vocation.objects.all()
data = serializers.serialize('json', result, ensure_ascii=False)
return HttpResponse(content=data, status=200)serializers.serialize() 的必填参数有两个。其一是你需要序列化的格式,输入的是字符串,这里用的是json,此外还支持xml等格式的转换。其二是你需要转换的内容,必须是一个 QuerySet 对象,也就是你从 ORM 中直接获取的数据集对象,而后面的 ensure_ascii=False ,上面刚讲过,不再介绍。
执行结果如下:

可见这种序列化方案,得到的结果比较乱,还带有很多不需要的数据内容,转换起来挺麻烦。
from rest_framework import serializers:
这个是Django中用于编写 REST FULL API 的成熟框架:django_rest_framework,所带的序列化方案,它需要你自己定义序列化模型:
from rest_framework import serializers
from .models import PersonInfo, Vocation
class MySerializer(serializers.Serializer):
id = serializers.IntegerField(read_only=True)
job = serializers.CharField(max_length=10)
title = serializers.CharField(max_length=10)
payment = serializers.IntegerField()
name_id = serializers.IntegerField()当然你也可以直接继承你的model,用法和Django的FORM模块极为相似,不懂的可以看一下官方文档,不过多介绍,之后是view.py中的代码。
from rest_framework.response import Response
from index.serializers import MySerializer
class TestViewRest(APIView):
def get(self, request):
result = Vocation.objects.all()
serializer = MySerializer(instance=result, many=True)
return Response(serializer.data)其中 instance 是你需要序列化的对象,这里也是一个 QuerySet 对象,而后面的 many =True 是指序列化多个数据对象,与上面的 Vocation.objects.all() 匹配,如果你这里是 Vocation.objects.first(),则就该使用 many = False。
而return中使用的Response,也是rest_framwork定义的特殊返回函数,它只支持由rest_framwork框架自己序列化的内容,同时它能美化返回结果。
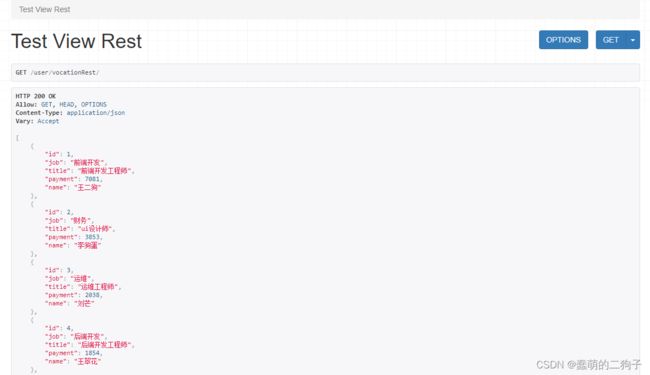
执行结果如下,某种层次来说,这已经有点像是个接口文档了,rest_framwork 也确实可以根据接口自己生成接口文档:

- 性能测试
接下来,我们来看看这三种序列化的方法的性能究竟如何,我们先往数据库里插入100条数据,通过 line_profiler(一个统计函数耗时的包,我有文章单独介绍过如何使用) 进行序列化性能测试,结果如下。
sql + JsonResponse :0.0381s
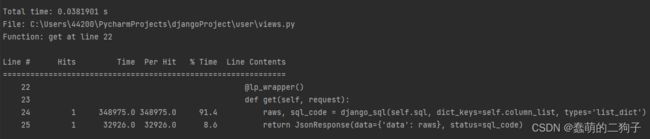
ORM + Django serializers : 0.1446s
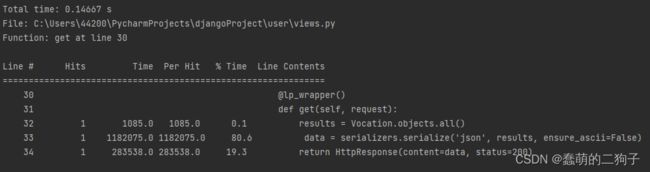
ORM + django_rest_framework serializers : 0.0424s

根据耗时可见,第一种方式的性能和后两者远不在同一个等级,后续我们加入更多的数据,进行测试,统计了表如下。
| 数据量:100 | 数据量:1000 | 数据量:10000 | 数据量:100000 | |
| JsonResponse | 0.0381s | 0.0861s | 0.4029s | 2.8002s |
| Django serializers | 0.1446s | 0.4086s | 4.5337s | 24.083s |
| rest_framework | 0.0424s | 0.2608s | 2.4303s | 15.752s |
十万条数据:

由此可见,django自带的序列化方案性能很不理想,虽然在较少的数据量下,三者给用户的体验并没有多大区别,而且一次性序列化十几万数据在正常的生产模式中也几乎不可见,但这却并不能掩饰它们的性能差异,哪怕是极为成熟的第三方框架 rest_framwork 性能也并非十分的理想。
- 基于外键的性能测试
上面的测试,只是在一种比较理想的模型下进行的,实际的开发情况下,还会有很多其他影响性能的因素,这里我们先试试外键对序列化性能的影响。
目标:name_id 改为名为 name 的外键,使用另外一个表(PersonInfo)的用户名字,替代序列化中的 name_id。
首先修改model:
from django.db import models
class PersonInfo(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=20)
age = models.IntegerField()
hireDate = models.DateField()
# 这里需要改一下
def __str__(self):
return self.name
class Meta:
verbose_name = '人员信息'
class Vocation(models.Model):
id = models.AutoField(primary_key=True)
job = models.CharField(max_length=20)
title = models.CharField(max_length=20)
payment = models.IntegerField()
# 原来的 name_id 改成外键
name = models.ForeignKey(PersonInfo, on_delete=models.Case, db_column='name')
def __str__(self):
return str(self.id)
class Meta:
verbose_name = '职业信息'
这里需要注意的有两点:
Vocation 中的外键中必须要自己重新命名列名,也就是: db_column='name' ,不然修改后的数据库列名会变成 name_id,这会影响返回的结果。
其次是需要重写 PersonInfo 的 __str__() 方法,让直接调用 PersonInfo 的实例化对象时候,返回的是用户名字,这会影响到 rest_framwork 序列化时候的内容。
修改:SQL + JsonResponse:
这里只需要修改一下SQL,使用 JOIN 从另一表中获取到用户的名字
class TestView(View):
sql = "SELECT a.id, a.job, a.title, a.payment, b.name FROM index_vocation AS a LEFT JOIN index_Personinfo " \
"AS b ON a.name_id = b.id"
column_list = ['id', 'job', 'title', 'payment', 'name']
def get(self, request):
raws, sql_code = django_sql(self.sql, dict_keys=self.column_list, types='list_dict')
return JsonResponse(data={'data': raws}, status=sql_code)结果如下:

修改:Django serializers
class TestViewDjango(View):
def get(self, request):
results = Vocation.objects.all()
for result in results:
result.name_id = result.name.name
data = serializers.serialize('json', results, ensure_ascii=False)
return HttpResponse(content=data, status=200)这里有一个大大大坑,需要着重记录一下。
这里要解释下 Vocation 实例对象,也就是上文中的 result 的 name_id 属性是从哪里来的。因为 model 中根本没有定义这个属性。实际上还是 Django ORM 会给外键列名加上 _id 后缀导致的,这里我们重新命名外键的列名为 name ,不然数据库中这一列也会以 name_id 命名。
何以见得?直接打印下 QureySet 内部的值。
results = Vocation.objects.all().valeus()
print(results)
但 name_id 不会影响到 Django serializers 序列化的内容,如下图。

经过测试,我发现这里只会以你定义外键时候的名字做为序列化基础。
也就是 name = models.ForeignKey(PersonInfo, on_delete=models.Case, db_column='name') 这行伪代码中最左边这个 name ,而右边这个 db_column='name' 我认为是无影响的,因在不设置它时候,数据库里的列名是 name_id,但序列化后依旧是 name,有兴趣的同学可以自己试试。
最后得到结果:

修改:rest_framwork 的序列化类
from rest_framework import serializers
from .models import PersonInfo, Vocation
class MySerializer(serializers.Serializer):
id = serializers.IntegerField(read_only=True)
job = serializers.CharField(max_length=10)
title = serializers.CharField(max_length=10)
payment = serializers.IntegerField()
# 把原来的 name_id 改成了 name
name = serializers.CharField(max_length=10)结果如下:
记录在外键下的序列化耗时:
| 数据量:100 | 数据量:1000 | 数据量:10000 | 数据量:100000 | |
| JsonResponse | 0.0091s | 0.0434s | 0.2958s | 3.1124s |
| Django serializers | 0.5234s | 6.77842s | 23.740s | 240.11s |
| rest_framework | 0.3249s | 5.99866s | 27.343s | 217.31s |
首先,为什么使用了JOIN 的 SQL 的耗时会比之前的少,那是因为之前的SQL使用了 SELECT *,而后面的SQL明确给出了列名。
后续的测试数据,已经无需多说了,十万条十的时候,我等的快睡着了,相比不带外键,耗时接近提升了十倍。
- 为什么会出现这种情况呢?
分析一下函数的计时情况。

可见里面最耗时的地方是将外键的值,重新赋值到 result.name_id 所制。而在reset_framwork中则是在 Response 阶段导致了大量的耗时。

我们首先调研下第二套方案的性能问题,我们尝试修改函数:
class TestViewDjango(View):
def get(self, request):
results = Vocation.objects.all().values()
return JsonResponse(data={'data': list(results)}, status=200)在不用外键的情况下,直接提取values 然后通过 JsonResponse 序列化,10W数据居然只要2.2s!和之前的24s相比,简直就是起飞,可见 JsonResponse 的性能,可以说是碾压 Djano serializers。

那我想用过这种方法加入外键的值,我要怎么做呢,继续修改函数:
class TestViewDjango(View):
def get(self, request):
results = Vocation.objects.all().values()
new_results_list = []
for result in list(results):
name_id = result.get('name_id')
person_info_object = PersonInfo.objects.get(id=name_id)
del (result['name_id'])
result['name'] = person_info_object.name
new_results_list.append(result)
return JsonResponse(data={'data': new_results_list}, status=200)耗时如下:

所以你发现了啥?238s秒和之前的240s,为何会如此的接近?
实际上问题也在于这里,那就是 ORM 的惰性查询,它并不会一次把外键中所有的 name 给你查出来,而是每一次你要获取 外键中的 name 的时候,都需要进行一次查询,10w条数据,等于查询了10W次,而我上面的代码等于还原了这个过程,所以能快起来,那就真的是有鬼了。
至于 rest_framwork 使用外键的时候,为什么会这么慢,也同样是因为这个原因,但框架似乎做过优化,比我们直接粗暴的查询,要快了那么一点点。
但真实的开发环境中,是不会处理这么大量的数据的,开发者会用到分页,先说到这,这文章已经足够长了,再写下去怕是没人看了。
总结:
1、单从序列化来看,JsonRespense 的性能无疑是最佳的。
2、序列化的过程中,能不用外键就绝对不用外键,如果你用SQL,请注意防注入。
3、对于序列化数据较少的情况下,编写规范的 REST FULL API时,我还是推荐使用
rest_framewrok,它还有很多其他的强大功能,能大大减少你的工作量。