LLVM笔记1
参考:https://www.bilibili.com/video/BV1D84y1y73v/?share_source=copy_web&vd_source=fc187607fc6ec6bbd2c74a3d0d7484cf
文章目录
- 零、入门名词解释
-
- 1. Compiler & Interpreter
- 2. AOT静态编译和JIT动态解释的编译方式
- 3. Pass
- 4. Intermediate Representations中间表达
- 5. 编译器基本构成
- 一、GCC编译流程
- 二、LLVM编译技术
-
- 1. LLVM设计架构
- 2. LLVM IR
-
- 2.1 IR语法
- 2.2 IR三种表达形式
- 2.3 IR内存模型
- 3. LLVM前端
-
- 3.1 词法分析
- 3.2 语法分析
- 3.3 语义分析
- 4. LLVM优化
-
- 4.1 发现Pass
- 4.2 Pass依赖
- 4.3 Pass API
- 5. LLVM后端
- 5.1 指令选择
- 5.2 指令调度
- 5.3 寄存器分配
- 5.4 指令调度
- 5.5 代码输出
- 发展
零、入门名词解释
1. Compiler & Interpreter
将程序从高级语言翻译到机器语言,得到一个可运行的文件。

2. AOT静态编译和JIT动态解释的编译方式
3. Pass
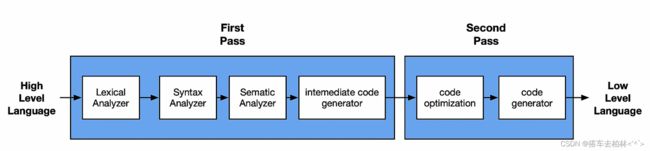
对源程序的一次完整扫描或处理。从高级语言到低级语言或者IR会经过几次Pass。比如下图第一个Pass是词法分析、语法分析、语义分析(图片里中间代码生成拼错了)。
4. Intermediate Representations中间表达
可以是数据结构或者定义好的代码,能让编译器或者虚拟机表达源码就行。
5. 编译器基本构成
- 前端:词法语法分析,将源代码转化为抽象语法树。
- 优化:对前端得到的IR优化,使得更高效。
- 后端:将优化的IR转化为针对各自平台的机器代码。比如X86、ARM、GPU上执行的机器码是不同的。

一、GCC编译流程
- 预处理(前端):读入源代码,响应预处理指令和替换宏定义,删除程序中的注释和多余空白符。会把引用的头文件和自己写的hello.c文件都放在hello.i文件中。
- 编译(优化):语法分析和词法分析,以及大量优化。hello.s中都是汇编指令。
- 汇编(后端):则是将汇编指令转为机器语言。
- 链接(后端):链接程序用到的目标文件、各种依赖的库文件,生成可执行文件,以二进制形式存储在磁盘中。

二、LLVM编译技术
1. LLVM设计架构
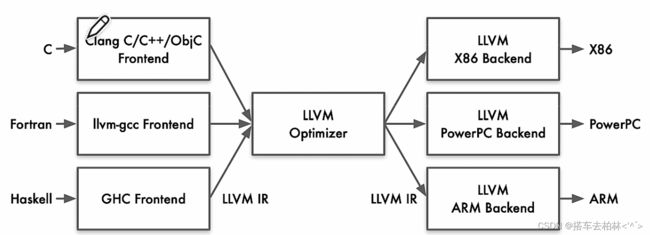
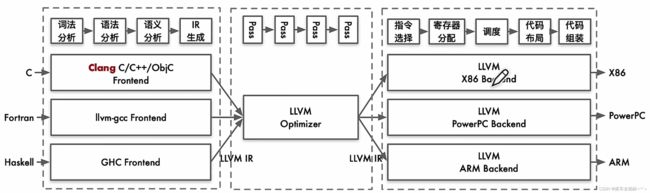
利用IR做中转,将前端和优化和后端分离开。不同于GCC的前后端没有解耦,LLVM增加一种新的语言时只用实现一个新的编译前端,优化和后端都能复用。
clang -E -c hello.c -o hello.i
clang -emit-llvm hello.c -S -o hello.ll #这里是导出为IR模式
llc hello.ll -o hello.s #这里导出的是汇编语言了
clang hello.s -o hello #这里得到可执行的二进制文件

2. LLVM IR
2.1 IR语法
;表示注释
@全局变量开头
%局部变量开头
alloca在函数栈中分配内存
store写入
load读取
i32 32位4字节
align字节对齐(计算机中内存大小的基本单位是字节(byte),理论上来讲,可以从任意地址访问某种基本数据类型,但是实际上,计算机并非逐字节大小读写内存,而是以2,4,或8的 倍数的字节块来读写内存,如此一来就会对基本数据类型的合法地址作出一些限制,即它的地址必须是2,4或8的倍数。那么就要求各种数据类型按照一定的规则在空间上排列,这就是对齐。)
- IR假设寄存器数量无限。
- 指令都是三地址形式,
操作码OP 第一操作数地址A1 第二操作数地址A2 结果地址A3。 - 不使用固定的命名寄存器,都是用
%字符命名临时寄存器。
2.2 IR三种表达形式
这三种中间格式是完全等价的:
- 在内存中的编译中间语言(无法通过文件的形式得到的指令类等)
- 在硬盘上存储的二进制中间语言( 格式为.bc )
- 人类可读的代码语言(格式为.Il )
2.3 IR内存模型
如果在编译器的优化层对LLVM的IR进行操作,写一个定制的优化pass,就需要了解LLVM IR内存模型。
● LLVM IR文件的基本单位称为module;
● 一个module中可以拥有多个顶层实体,比如function和global variable;
● 一个function define中至少有一个basicblock(就是花括号);
● 每个basicblock中有若干instruction ,并且都以terminator instruction(写作ret,就是return的意思)结尾。
void test( int a, int b){
int c=a*b + 100;
}
1 ; Function Attrs: noinline nounwind optnone ssp uwtable
2 define void @test(i32, i32) #2 { ;有个全局函数@test (a,b)
3 %3 = alloca 132,align 4 ;局部变量C
4 %4 = alloca i32,align 4 ;局部变量d
5 %5 = alloca i32, align 4 ;局部变量e
6 store i32 %0, i32*%3,align 4 ;%0赋值给3C=a
7 store i32%1,i32*%4,align 4 ;%1赋值给%4d=b
8 %6=load i32, i32*%3, align 4 ;读取%3 ,赋值给%6就是函数参数a
9 %7=load i32, i32* %4 , align 4 ;读取%4 ,赋值给%7就是函数参数b
10 %8=mul nsw i32%6, %7 ;a*b
11 %9=add nsw i32%8, 100 ;a*b+100
12 store i32%9, i32*%5, align 4 ;参数%9赋值给%5 e ===>就是转换前函数写的int c变量
ret void
3. LLVM前端
3.1 词法分析
前端的第一个步骤处理源代码的文本输入,将语言结构分解为一组单词和标记,去除注释、空白、制表符等。每个单词或者标记必须属于语言子集,语言的保留字被变换为编译器内部表示。
3.2 语法分析
分组标记以形成表达式、语句、函数体等。检查-组标记是否有意义 ,考虑代码物理布局,未分析代码的意思,就像英语中的语法分析,不关心你说了什么,只考虑句子是否正确,并输出语法树( AST )。

3.3 语义分析
借助符号表检验代码没有违背语言类型系统。符号表存储标识符和其各自的类型之间的映射,以及其它内容。类型检查的一-种直觉的方法是,在解析之后,遍历AST的同时从符号表收集关于类型的信息。
4. LLVM优化
4.1 发现Pass
优化通常由分析Pass和转换Pass组成:
- 分析Pass :负责发掘性质和优化机会;
- 转换Pass :生成必需的数据结构,后续为后者所用;
4.2 Pass依赖
在转换Pass和分析Pass之间,有两种主要的依赖类型:
- 显式依赖:转换Pass需要一种分析,则Pass管理器自动地安排它所依赖的分析Pass在它之前运行;
DominatorTree &DT = getAnalysis<DominatorTree>(Func);
- 隐式依赖:转换或者分析Pass要求IR代码运用特定表达式。需要手动地以正确的顺序把这个Pass加到Pass队列中,通过命令行工具( clang或者opt )或者Pass管理器。
4.3 Pass API
Pass类是实现优化的主要资源。然而,我们从不直接使用它,而是通过清楚的子类使用它。当实现一个Pass时,你应该选择适合你的Pass的最佳粒度,适合此粒度的最佳子类,例如基于函数、模块、循环、强联通区域,等等。常见的这些子类如下:
● ModulePass (一个模块)
● FunctionPass(一个函数)
● BasicBlockPass (某几条指令)
5. LLVM后端
也是由多个Pass链接,分为必要Pass和非必要Pass,下面介绍一些必要Pass
5.1 指令选择
- 内存中LLVM IR变换为目标特定SelectionDAG节点;
- DAG有向无环图,IR变成图后表示单一的一个计算节点,图的节点是具体执行的指令,边是数据流依赖关系。。每个DAG能够表示单一基本块的计算。
5.2 指令调度
第1次指令调度( Instruction Scheduling ) ,也称为前寄存器分配(RA)调度。
●对指令排序,同时尝试发现尽可能多的指令层次的并行;
●然后指令被变换为MachineInstr三地址表示。
5.3 寄存器分配
LLVM IR寄存器集是无限的,这个性质一直保持着,直到寄存器分配( Register Allocation )
●寄存器分配将无限的虚拟寄存器引用转换为有限的目标特定的寄存器集;
●寄存器不够时挤出( spill )到内存。
5.4 指令调度
第2次指令调度,也称为后寄存器分配(RA)调度。
●此时可获得真实的寄存器信息,某些类型寄存器存在延迟,它们可被用以改进指令顺序。
5.5 代码输出
- 代码输出阶段将指令从MachineInstr表示变换为MCInst实例;
- 新的表示更适合汇编器和链接器,可以输出汇编代码或者输出二进制块特定目标代码格式。
发展
XLA (加速线性代数)是一种针对特定领域的线性代数编译器。
Julia面向科学计算的高性能动态编程语言,使用LLVM JIT编译。LLVM JIT编译器通常不断地分析正在执行的代码,并且识别代码的一部分 ,使得从编译中获得的性能加速超过编译该代码的性能开销。