【深度学习】采用自动编码器生成新图像
一、说明
你知道什么会很酷吗?如果我们不需要所有这些标记的数据来训练 我们的模型。我的意思是标记和分类数据需要太多的工作。 不幸的是,大多数现有模型从支持向量机到卷积神经网,没有它们,卷积神经网络就无法训练。无监督学习不需要标注。无监督学习从未标记推断函数 数据本身。最著名的无监督算法是K-Means,它具有 广泛用于将数据聚类到组中和 PCA,这是首选 降维解决方案。K-Means和PCA可能是最好的两个 曾经构思过的机器学习算法。让他们变得更好的是 他们的简单性。我的意思是,如果你抓住它们,你会说:“我为什么不这样做?
二、自动编码器。
为了更好地理解自动编码器,我将提供一些代码以及解释。请注意,我们将使用 Pytorch 来构建和训练我们的模型。
import torch
from torch import nn, optim
from torch.autograd import Variable
from torch.nn import functional as F自动编码器是简单的神经网络,它们的输出就是它们的输入。简单 就这样。他们的目标是学习如何重建输入数据。但是怎么样 有益的?诀窍在于它们的结构。网络的第一部分是我们 称为编码器。它接收输入并将其编码为潜在 较低维度的空间。第二部分(解码器)采用该向量和 对其进行解码以生成原始输入。

用于基于ECG的生物特征识别中异常值校正的自动编码器神经网络
中间的潜在向量是我们想要的,因为它是输入的压缩表示。并且应用非常丰富,例如:
-
压缩
-
降维
此外,很明显,我们可以应用它们来重现相同的内容,但 数据几乎没有不同,甚至更好。例如:
-
数据去噪:用嘈杂的图像馈送它们,并训练它们输出 图像相同,但没有噪点
-
训练数据增强
-
异常检测:在单个类上训练它们,以便每个异常都给出 重建误差大。
然而,自动编码器面临着与大多数神经网络相同的问题。他们 倾向于过度拟合,他们遭受梯度消失问题的困扰。有没有 溶液?
三、变分自动编码器 (VAE)
变分自动编码器是一个相当不错和优雅的努力。它 本质上增加了随机性,但并不完全正确。
让我们进一步解释一下。变分自动编码器经过训练以学习 对输入数据进行建模的概率分布,而不是对 映射输入和输出。然后,它从此分布中采样点 并将它们馈送到解码器以生成新的输入数据样本。但是等一下 分钟。当我听到概率分布时,只有一件事来了 想到:贝叶斯。是的,贝叶斯规则再次成为主要原则。由 方式,我不是要夸大其词,但贝叶斯公式是唯一最好的方程 曾经创建过。我不是在开玩笑。它无处不在。如果你不知道什么 是,请查一下。抛弃那篇文章,了解贝叶斯是什么。我会原谅的 你。
回到变分自动编码器。我认为下面的图像清楚地说明了问题:

使用循环变分自动编码器进行纹理合成
你有它。随机神经网络。在我们构建示例之前,我们的 自己生成新图像,讨论更多细节是合适的。
VAE的一个关键方面是损失函数。最常见的是,它包括 两个组件。重建损失衡量的是 重建的数据来自原始数据(例如二进制交叉熵)。 KL-散度试图使过程正规化并保持重建 数据尽可能多样化。
def loss_function(recon_x, x, mu, logvar) -> Variable:
BCE = F.binary_cross_entropy(recon_x, x.view(-1, 784))
KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
KLD /= BATCH_SIZE * 784
return BCE + KLD另一个重要方面是如何训练模型。困难的发生是因为 变量是确定性的,但通常是随机和梯度下降的 不是那样工作的。为了解决这个问题,我们使用重新参数化。潜伏的 向量 (z) 将等于分布的学习均值 (μ) 加上 学习标准差 (σ) 乘以 epsilon (ε),其中 ε 遵循正态 分配。我们重新参数化样本,使随机性 与参数无关。
def reparameterize(self, mu: Variable, logvar: Variable) -> Variable:
#mu : mean matrix
#logvar : variance matrix
if self.training:
std = logvar.mul(0.5).exp_() # type: Variable
eps = Variable(std.data.new(std.size()).normal_())
return eps.mul(std).add_(mu)
else:
return mu四、使用自动编码器生成图像
在我们的示例中,我们将尝试使用变分自动编码器生成新图像。我们将使用MNIST数据集,重建的图像将是手写的数字。正如我已经告诉过你的,我使用 Pytorch 作为一个框架,除了熟悉之外,没有特别的原因。 首先,我们应该定义我们的层。
def __init__(self):
super(VAE, self).__init__()
# ENCODER
self.fc1 = nn.Linear(784, 400)
self.relu = nn.ReLU()
self.fc21 = nn.Linear(400, 20) # mu layer
self.fc22 = nn.Linear(400, 20) # logvariance layer
# DECODER
self.fc3 = nn.Linear(20, 400)
self.fc4 = nn.Linear(400, 784)
self.sigmoid = nn.Sigmoid()如您所见,我们将使用一个非常简单的网络,只有密集层(在pytorch的情况下是线性的)。 下一步是生成运行编码器和解码器的函数。
def encode(self, x: Variable) -> (Variable, Variable):
h1 = self.relu(self.fc1(x))
return self.fc21(h1), self.fc22(h1)
def decode(self, z: Variable) -> Variable:
h3 = self.relu(self.fc3(z))
return self.sigmoid(self.fc4(h3))
def forward(self, x: Variable) -> (Variable, Variable, Variable):
mu, logvar = self.encode(x.view(-1, 784))
z = self.reparameterize(mu, logvar)
return self.decode(z), mu, logvar这只是几行python代码。没什么大不了的。最后,我们可以训练我们的模型并查看我们生成的图像。
快速提醒:与tensorflow相比,Pytorch有一个动态图,这意味着代码是动态运行的。无需创建图然后编译执行它,Tensorflow 最近以其渴望的执行模式引入了上述功能。
optimizer = optim.Adam(model.parameters(), lr=1e-3)
def train(epoch):
model.train()
train_loss = 0
for batch_idx, (data, _) in enumerate(train_loader):
data = Variable(data)
optimizer.zero_grad()
recon_batch, mu, logvar = model(data)
loss = loss_function(recon_batch, data, mu, logvar)
loss.backward()
train_loss += loss.data[0]
optimizer.step()
def test(epoch):
model.eval()
test_loss = 0
for i, (data, _) in enumerate(test_loader):
data = Variable(data, volatile=True)
recon_batch, mu, logvar = model(data)
test_loss += loss_function(recon_batch, data, mu, logvar).data[0]
for epoch in range(1, EPOCHS + 1):
train(epoch)
test(epoch)训练完成后,我们执行测试函数来检查模型的工作情况。 事实上,它做得很好,构建的图像与原始图像几乎相同,我相信没有人能够在不了解整个故事的情况下区分它们。
下图显示了第一行的原始照片和第二行中制作的照片。
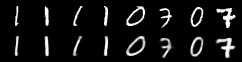
相当不错,不是吗?
有关自动编码器的更多详细信息,您应该查看edX的深度学习与Tensorflow课程的模块5。
在我们结束这篇文章之前,我想再介绍一个话题。正如我们所看到的,变分自动编码器能够生成新图像。这是生成模型的经典行为。生成模型正在生成新数据。另一方面,判别模型正在对类或类别中的现有数据进行分类或区分。
用一些数学术语来解释这一点: 生成模型学习联合概率分布 p(x,y),而判别模型学习条件概率分布 p(y|x)。
在我看来,生成模型更有趣,因为它们为从数据增强到可能的未来状态的模拟等许多可能性打开了大门。但在下一篇文章中会有更多内容。 可能是在一篇关于一种相对较新的生成模型类型的帖子上,称为生成对抗网络。
在那之前,继续学习人工智能。