mybatisplus常用小技巧,mybatisX插件使用小技巧
条件构造器select方法介绍
根据业务需求,有时候只需要返回特定的几个数据表字段,我们通过条件构造器的select方法可以指定;
还有一种情况,假如数据库字段很多的时候,我们要排除某几个字段,其他字段返回的时候,select方法也支持排除某些字段,查询其他的;
最后还有一种情况,我们搞分组聚合函数的时候,可以使用select方法,返回聚合函数执行后的数据字段;
实例
实例一:查找薪水大于3500 名字里有“小”的 员工 (只显示编号和姓名)
@Test
public void selectByQueryWrapper7(){
QueryWrapper<Employee> queryWrapper=new QueryWrapper();
// QueryWrapper queryWrapper2=Wrappers.query();
queryWrapper.select("id","name").gt("salary",3500).like("name","小");
List<Employee> employeeList = employeeMapper.selectList(queryWrapper);
System.out.println(employeeList);
}
1
2
3
4
5
6
7
8
实例二:查找薪水大于3500 名字里有“小”的 员工 (排除出生日期和性别)
@Test
public void selectByQueryWrapper8(){
QueryWrapper<Employee> queryWrapper=new QueryWrapper();
// QueryWrapper queryWrapper2=Wrappers.query();
queryWrapper
.select(Employee.class,fieldInfo->!fieldInfo.getColumn().equals("birthday")&&!fieldInfo.getColumn().equals("gender"))
.gt("salary",3500)
.like("name","小");
List<Employee> employeeList = employeeMapper.selectList(queryWrapper);
System.out.println(employeeList);
}
1
2
3
4
5
6
7
8
9
10
11
实例三:查询每个部门的平均薪资
sql实现:
SELECT departmentId,AVG(salary) AS avg_salary FROM t_employee GROUP BY department_id;
1
@Test
public void selectByQueryWrapper9(){
QueryWrapper queryWrapper=new QueryWrapper();
// QueryWrapper queryWrapper2=Wrappers.query();
queryWrapper
.select("department_id","AVG(salary) AS avg_salary")
.groupBy("department_id");
List employeeList = employeeMapper.selectList(queryWrapper);
System.out.println(employeeList);
}
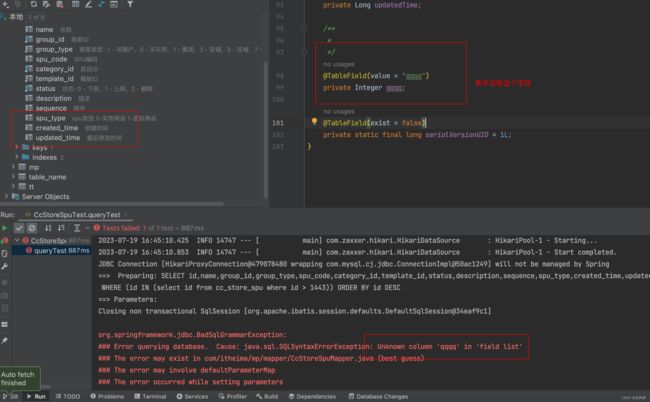
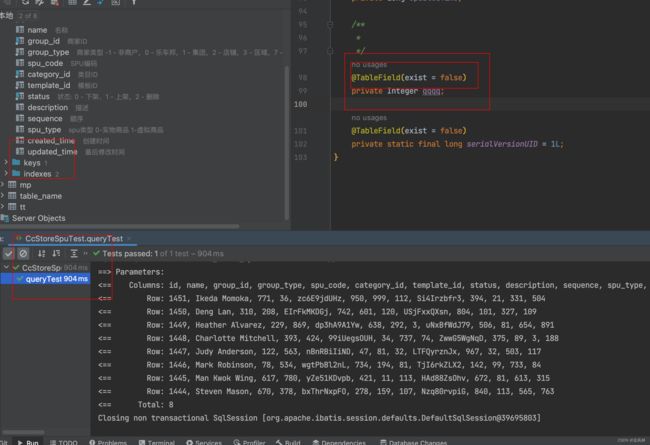
实体类与表字段.没有映射关系.
使用则个注解
@TableField(exist = false)
mybatisX插件快速生成代码
1.到指定位置生成
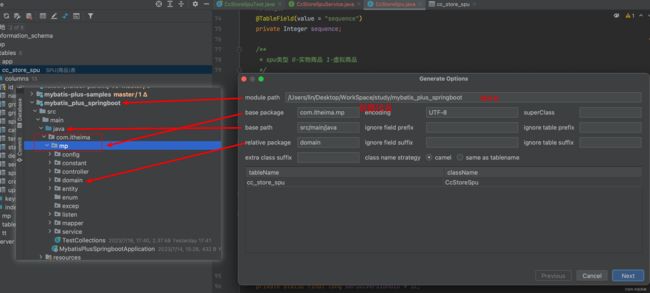
2.实体类 注解,驼峰命名
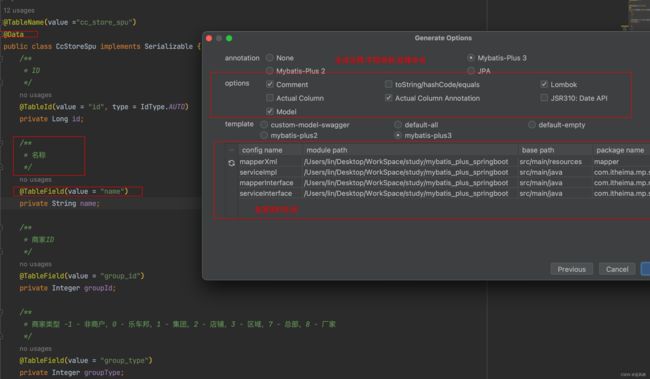
3.文件覆盖,生成新的文件,如果和旧文件有冲突.可以选择保持旧的文件.或者选择覆盖
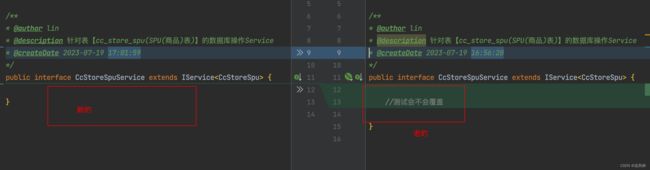

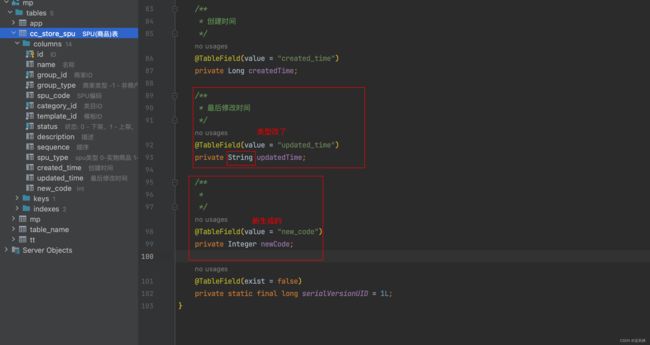
4.实体类增加字段.删减字段.修改了类型.可以直接生成替换

xml的foreach和mybatis-plus的saveBatch 比对大数据 插入和修改比对
大数据量的情况下.使用集合分批 xml的foreach循环插入…
foreach.是把数据拼接再一条sql.但是mysql对大小有限制.看的别的博客的.一般建议,对list进行切分
https://blog.csdn.net/weixin_41725792/article/details/110186011#:~:text=%E6%8D%A2%E7%AE%97%E5%90%8E%E7%9A%84%E7%BB%93%E6%9E%9C%E4%B8%BA%EF%BC%9A,M%E7%9A%84%E7%BC%93%E5%86%B2%E5%8C%BA%E5%A4%A7%E5%B0%8F%E3%80%82
字段比较少
5000条数据
foreach
1070ms
mybatis-Plus
5034ms
10000条数据 分5000一次插入,批处理
foreach
1617秒ms
mybatis-Plus
5034ms

List<BookTag> list =new ArrayList<>();
for (int i = 0; i < 10000; i++) {
BookTag bookTag = new BookTag();
bookTag.setBookTagId(0L+i);
bookTag.setBookTagName("i");
bookTag.setBookTagGmtCreate(new Date());
bookTag.setBookTagGmtModified(new Date());
bookTag.setBookTagDeleted(0);
bookTag.setBookTenantId("123213");
list.add(bookTag);
}
long s2 = System.currentTimeMillis();
List<List<BookTag>> partition = Lists.partition(list, 5000);
for (List<BookTag> list1 : partition) {
StopWatch stopWatch = new StopWatch("foreachInsert计时");
stopWatch.start("foreachInsert计时");
long s = System.currentTimeMillis();
bookTagMapper.insertBatch(list1);
//bookTagService.saveBatch(list1);
long e = System.currentTimeMillis();
System.out.println(e-s);
stopWatch.stop();
log.info("批量插入完成"+stopWatch.prettyPrint());
}
long e2 = System.currentTimeMillis();
System.out.println(e2-s2);
<insert id="insertBatch">
insert into book_tag(tag_id,tag_name,
gmt_create,gmt_modified,deleted,
tenant_id)
values
<foreach collection="bookTagCollection" item="item" separator=",">
(#{item.bookTagId,jdbcType=NUMERIC},
#{item.bookTagName,jdbcType=VARCHAR},
#{item.bookTagGmtCreate,jdbcType=TIMESTAMP},
#{item.bookTagGmtModified,jdbcType=TIMESTAMP},
#{item.bookTagDeleted,jdbcType=NUMERIC},
#{item.bookTenantId,jdbcType=VARCHAR})
</foreach>
</insert>