RISC-V处理器核设计优化与扩展指令集实现(一)
1.1 课题研究背景及意义
随着移动物联网、汽车电子和人工智能等技术的兴起和市场化,终端设备的高性能、低功耗、可信加密等要求越来越苛刻。如果仅仅依靠软件编程来实现复杂的计算密集型或者访存密集型算法,不仅计算和循环程序功耗大,且性能低。因此,越来越多的计算复杂程序需要以芯片硬件电路加速实现性能优化。DSA(Domain Specific Architecture)便是CPU设计领域面向应用场景的专用电路加速架构的统称。
不同的应用场景对芯片算力的通用性和灵活性也提出更大挑战。SoC芯片的处理器核不仅仅要实现基本的指令计算和控制能力,更需要考虑扩展性以保证其在特定应用场景下的灵活性,具备更大数据带宽、更快访存系统和更加丰富的外设接口。
集成电路处理器芯片有三种主流指令集架构:X86、ARM以及新兴RISC-V。X86是以Intel和AMD主导的企业设计芯片所使用的指令集架构,主要面向个人电脑和服务器处理器芯片。我国兆芯、海光CPU基于X86指令集;ARM指令集大多应用于嵌入式处理器,并逐渐应用于高端服务器处理器中。但是,X86和ARM指令集不仅仅需要高昂的授权费用,更面临卡脖子风险。RISC-V开源指令集更适合于国产自主芯片设计。此外,RISC-V指令集的可扩展性可以灵活的适配应用场景,无论是通用处理能力还是特定领域的加速处理,都具备优异的表现,这使得基于RISC-V指令集的处理器不仅具有通用处理器的能力,还具备面向特定领域加速处理的灵活性。
此外,RISC-V指令集属于RISC精简指令集架构,如图1-1所示,相较于其他指令集,在实现相同功能代码的情况下,无论是32bit还是64bit架构,RISC-V指令集都能够显著减少代码体积。
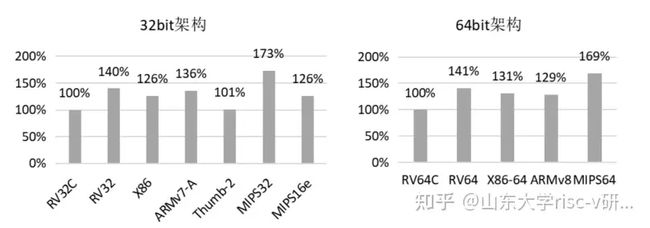
图1-1 各指令集架构的代码体积比较
目前,国内外涌现出大量的RISC-V处理器核,其中很多是开源的。国外开源的RISC-V处理器核有西部数据使用System Verilog语言开发的SweRV-EH和EL系列处理器,EH为高性能处理器,主要用于硬盘控制器中数据处理和控制;伯克利大学基于Chisel开发的单发射顺序执行的Rocket处理器以及多发乱序执行的BOOM处理器已经更新迭代到第三个版本,名为SonicBOOM,这些处理器有配套的SoC以及编译和开发环境Chipyard;Charles等人使用SpinalHDL开发了VexRiscv处理器。国内有芯来科技公司开源的蜂鸟E203处理器;中科院计算所使用Chisel开发了开源XiangShan处理器,第二版Nanhu较第一版Yanqihu有大幅性能提升,达到了Coremark 7.81,SPECint 2006 18.41, SPECfp 2006 20.94@2GHz;阿里平头哥开源玄铁E系列处理器和C系列高性能处理器也有广泛的应用。目前开源的处理器中,平头哥的玄铁C910、伯克利的BOOM以及中科院计算所的香山处理器性能较高。在公开的资料和论文中,可以看到最新的几种处理器的Coremark成绩对比如图1-2所示。
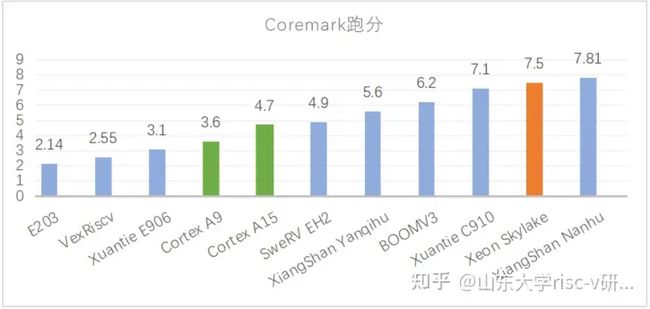
图1-2 RISC-V开源处理器以及ARM和X86典型架构Coremark跑分
图1-2中,Cortex A9和A15是ARM体系架构的两款典型处理器架构,Xeon Skylake是X86阵营Intel公司旗下服务器端处理器架构。可以看到RISC-V开源处理器性能遍布低端嵌入式处理器、中端应用处理器,并在高端服务器性能已经可以媲美甚至超过Intel典型架构。如今,处理器开发正式进入了X86、ARM和RISC-V三分天下的局面。最新发布的第二代Xiangshan系列处理器Nanhu是目前开源RISC-V处理器中性能最强的,但是XiangShan系列处理器使用Chisel开发,其EDA流程相比于产业化流程尚未完善。C910采用Verilog语言描述,Coremark跑分达到了7.1分,性能优越,且已经具备产业化应用案例。
通过优化处理器核设计,可以提升RISC-V处理器的整体性能和效率。通过针对特定应用场景进行扩展指令集的实现,可以使处理器更好地适应不同的工作负载和任务要求。这种通用性和灵活性的提升可以使RISC-V处理器在各个领域和应用中更具竞争力。另外,随着技术的发展和市场需求的变化,处理器和系统级芯片面临着越来越多的新挑战。通过优化处理器核设计和引入扩展指令集,可以满足市场对更高性能、更低功耗、更小尺寸和更低成本的要求。这种优化可以帮助RISC-V处理器在不同市场和应用中更好地竞争和应对需求。因此,对于成熟的RISC-V处理器架构(以C910为代表)进行研究,优化处理器核设计,并研究如何在RISC-V体系下实现扩展指令集,以满足特定场景的加速需求,对于提高RISC-V处理器的通用性和灵活性、满足当今市场对处理器及系统级芯片的新要求以及实现芯片自主可控具有重要学术和实际意义。
1.2 国内外研究现状
1.2.1 RISC-V处理器核的敏捷开发
不同于以往的处理器设计,在RISC-V处理器设计中不仅仅有较为传统的使用Verilog或System Verilog等HDL(Hardware Description Language)开发的,还有使用敏捷开发方法进行RISC-V处理器核心开发的项目。相较于传统的开发手段,敏捷开发具有高效、标准化的特点,如今RISC-V体系甚至是整个ASIC和FPGA体系开发的敏捷方法可以归为四类:
(1) Matlab方法:使用Matlab提供的HDL Coder工具箱。随着人工智能、大数据和图像处理的兴起,传统的软件算法在处理速度和效率方面存在着局限性。因此,许多算法都被硬件化以提高其性能。然而,从头开始使用HDL描述复杂的算法(如FIR滤波、FFT变换以及图像ISP的Pipeline)是一个耗时费力的过程。在这种情况下,使用HDL Coder工具可以大大简化这一过程。对于图像处理领域,Matlab还提供了Vision HDL ToolBox工具,可通过Simulink搭建模型进行仿真和验证。HDL Coder生成的HDL代码易读性很高,而且HDL Coder还提供了代码优化的功能,例如可以选择优化电路的面积或时序。优化面积时可以使用共享因子(例如乘法器)共享资源,也可以通过Pipeline方式优化关键路径,这些优化方法都由HDL Coder自动实现。
(2) C/C++方法:使用Xilinx的HLS工具。与HDL Coder类似,高层次综合(HLS)也提供了一种简便快速的方式来处理复杂的设计,特别是算法设计。与HDL Coder不同的是,HLS使用C/C++模型进行描述。用户可以使用高级C/C++描述自己的算法模型,并利用HLS工具快速将此模型转换为硬件语言描述模型。尽管HLS在FPGA算法开发方面高效快速,但生成的代码往往无法控制其时序和面积,并且代码可读性不高。
(3) Scala方法:使用Chisel或Spinal HDL。Chisel是来自UC Berkely的一门硬件构架语言,Chisel基于Scala语言,继承了Scala的丰富特性,使用户可以在更高层次上描述硬件架构行为,并将其转换为硬件描述语言。Chisel不断完善,现在转换后的HDL描述更为成熟,已有许多成功的实现案例,如BOOM和XiangShan等基于Chisel的开源项目。Spinal HDL是另一种基于Scala的库,相较于Chisel,生成的代码可读性更高。虽然使用面向对象的描述方法和许多软件会使得这些语言对于硬件描述者的入门门槛相对较高,但对于FPGA开发者来说,使用它们还是相对容易的。Spinal的作者还开发了一个基于RISC-V的CPU——VexRISCV,Wilson等人在宇航级TMR处理器设计中采用了此处理器。虽然Spinal HDL生成的代码可读性较高,但是它只能生成一个文件。即使使用Spinal HDL描述多个模块,最终生成的也只是一个HDL描述文件。这种方式不利于代码的仿真和调试。
(4) Python方法:使用MyHDL。MyHDL是一个Python库,生成的代码可读性较高,而且编程时可以充分利用Python语言的众多特性。需要注意的是,虽然MyHDL对ASIC开发较为友好,但并不意味着可以不加限制地将Python语句转换为对应的HDL描述。
1.2.2 RISC-V扩展指令集现状
RISC-V指令集提供了16位、32位、64位和128位的标准格式,其中16位和32位指令集适用于嵌入式处理器,而64位和128位指令集则适用于个人计算机或服务器。与传统的指令集架构如X86和ARM不同,RISC-V的指令集是一个可扩展的、模块化的结构。相比之下,X86的指令集架构是一个增量式的发展过程,平均每个月增加大约三条指令。这也意味着,每次更新迭代的X86处理器都必须实现以前的基础指令集和更新的扩展指令集,导致X86的指令集架构变得越来越臃肿。ARM架构分为Application、Realtime和Embedded三个系列,每个系列都有各自的优化方法。与X86和ARM指令集架构不同,RISC-V具有模块化的特点,使得用户可以根据需要选择实现扩展指令集或自定义指令集,从而达到性能、功耗和面积的平衡。
随着应用场景的多样化和对处理器能效要求的进一步提高,DSA(Domain Specific Architecture)架构正在逐渐兴起,并成为未来市场的主流发展方向。该架构要求对微处理器应用的特定场景进行精细化的设计,以获得最高的能效比。RISC-V扩展指令集是朝着DSA架构发展的重要一步。由于其模块化特点,只要用户在特定应用场景中会经常使用到某种特殊的程序,并且这种程序又有抽象的RISC-V指令集的对应,那么用户就可以选择实现这种对应的扩展指令集,并将这些扩展指令集添加到自己的编译器中来实现特定应用场景的加速。
RISC-V扩展指令集可以有选择的添加到实现了基础指令集的流水线架构中。对于32位指令集架构,其基础指令集为RV32I,即32位整数指令集,而64位和128位指令集也有对应的基础指令集。除法、原子操作指令、单精度浮点数、双精度浮点数以及其他特色指令操作均以扩展指令集的形式实现。实现这些扩展指令集的前提是必须实现其基础指令集。RISC-V已经集成了近20种扩展指令集,每个扩展指令集都有自己的应用领域,例如H扩展指令集用于实现硬件虚拟化,B指令集扩展可用于加速比特级操作,而K扩展用于加速常见的AES/SHA2/SM3/SM4等加解密算法操作。表1-1概述了截至目前RISC-V的扩展指令集的统计情况,并给出了每个扩展指令集所实现的大致功能和用用场景。
表1-1 RISC-V基础和扩展指令集状态
| 指令集 | 描述 | 版本 | 状态 |
| RV32I | 32bit基础整数指令 | 2.1 | 批准 |
| RV32E | 32bit嵌入式指令 | 1.9 | 开放 |
| RV64I | 64bit基础整数指令 | 2.1 | 批准 |
| RV128I | 128bit基础整数指令 | 1.7 | 开放 |
| M | 乘除法指令扩展 | 2.0 | 批准 |
| A | 原子指令扩展 | 2.1 | 批准 |
| F | 单精度浮点指令扩展 | 2.2 | 批准 |
| D | 双精度浮点指令扩展 | 2.2 | 批准 |
| Zicsr | 控制和状态寄存器 | 2.0 | 批准 |
| Zifence | Fence指令扩展 | 2.0 | 批准 |
| G | 相当于IMAFDZicsr | N/A | N/A |
| C | 压缩指令扩展 | 2.0 | 批准 |
| B | 比特操作指令扩展 | 1.0 | 开放 |
| P | SIMD指令扩展 | 0.2 | 开放 |
| K | 加解密指令扩展 | 1.0 | 开放 |
| V | 向量指令扩展 | 1.0 | 开放 |
| H | 虚拟化指令扩展 | 1.0 | 批准 |
可以看到,RISC-V指令集的最新扩展中已经包含了向量扩展指令集,这对于人工智能技术的广泛应用非常重要。向量指令集的实现可以在大规模矩阵运算或稀疏矩阵计算中产生良好的加速效果。此外,RISC-V还扩展了Hypervisor指令集,实现了虚拟化的功能,使得使用RISC-V处理器的主机可以同时运行主机(Host)和客户机(Guest),这是个人电脑和云服务器芯片所必备的重要功能。RISC-V指令集的发展与时俱进,只要有大规模的应用场景,就可以通过抽象应用场景的数学计算“模式”,采用RISC-V扩展指令集的方式来实现。这也表明了RISC-V在占据未来市场和空间方面的野心。
1.2.3 RISC-V SoC设计流程
SoC设计流程涵盖了架构及规格的指定、设计、验证、逻辑综合、时序分析、形式验证、版图及布局布线等多个步骤,如图1-3所示。首先,制定系统的架构规格,包括系统使用的算法、功耗、性能和面积等参数,将用户需求转化为设计文档并初步确定系统的工作流程。接下来,进行详细的设计和验证,这是一个循环迭代的过程,需要根据后续验证结果修改RTL代码以满足设计要求。然后,对整个设计实施布局布线、时钟树综合等后端流程,得到GDSII数据。在后端布局布线过程中,可以提取出设计中详细的延时参数,并根据这些参数进一步检测设计是否满足时序要求。在保证设计无问题后,进行流片。
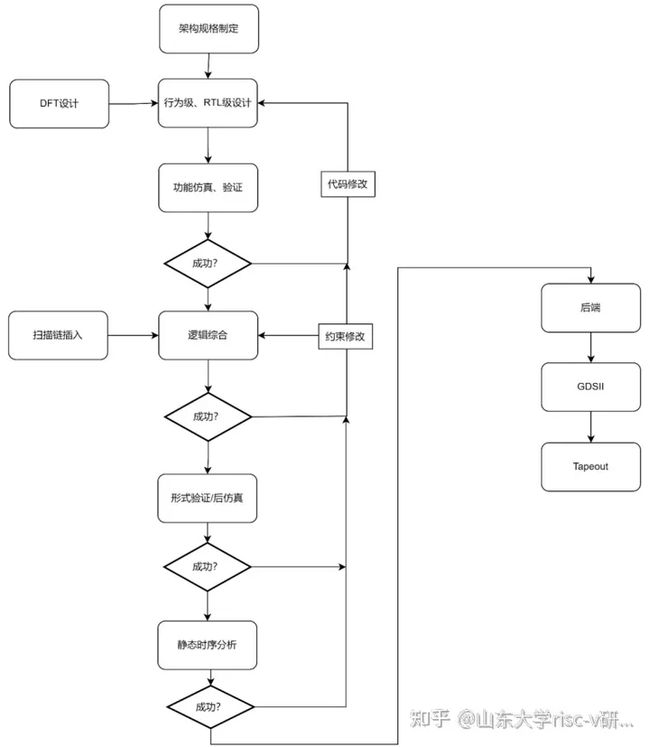
图1-3 SoC开发流程示意图