MySQL 窗口函数
聚合函数作为窗口函数
设聚合函数为op语法结构:
op(字段名A) over(partition by 字段名B order by 字段名C rows between D1 and D2)
其中:
-
partition by:按照某一字段将数据进行分组
-
order by:按照某一字段将数据进行排序,默认升序ASC,可设置为降序DESC
-
字段名A:执行聚合操作的字段
-
字段名B:通过该字段进行分组
-
字段名C:通过该字段进行排序
-
D1:行数的起始范围
-
D2:行数的结束范围
其中表示范围的D1和D2可以用下图这些表示方法:

若没有字段名C rows between D1 and D2,默认范围为rows between unbounded preceding and current row,即范围为之前所有的行和本行。一个例子如下:
Create table If Not Exists tb(id int, gid int,val int);
insert into tb values (1, 1, 1);
insert into tb values (2, 2, 2);
insert into tb values (3, 1, 3);
insert into tb values (4, 2, 4);
insert into tb values (5, 1, 3);
insert into tb values (6, 2, 6);
insert into tb values (7, 1, 7);
insert into tb values (8, 2, 8);
insert into tb values (9, 1, 9);
select id, gid, val, sum(val) over(partition by gid order by id) as sum, avg(val) over(partition by gid order by id) as avg
from tb;
执行结果:

可以看出,这里的sum窗口函数即按gid分组,并在组内按id排序,返回每行val上的前缀和,avg类似。
分区排序函数
设聚合函数为op语法结构:
op(字段名A) over(partition by 字段名B order by 字段名C)
示例如下:
Create table If Not Exists tb(id int, gid int,val int);
insert into tb values (1, 1, 1);
insert into tb values (2, 2, 2);
insert into tb values (3, 1, 3);
insert into tb values (4, 2, 4);
insert into tb values (5, 1, 3);
insert into tb values (6, 2, 6);
insert into tb values (7, 1, 7);
insert into tb values (8, 2, 8);
insert into tb values (9, 1, 9);
select id, gid, val, rank() over(partition by gid order by val) as rank_, row_number() over(partition by gid order by val) as row_num, dense_rank() over(partition by gid order by val) as drank
from tb
where gid = 1;
执行结果:
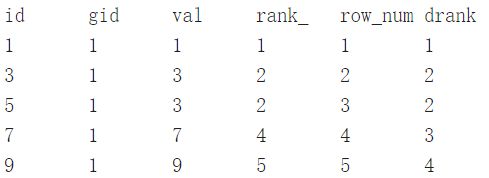
三种函数的特点简单地说:
- rank():序号可以重复,可能不连续
- row_number():序号不能重复,连续
- dense_rank(): 序号可以重复,连续
分区按数量分组函数
分区按数量分组函数ntile语法结构:
ntile(k) over(partition by 字段名A order by 字段名B)
其中k为组数,设partition by 划分的一个区域的行数为n,则这个区域的前 n % k n\%k n%k组中每组行数为 ⌈ n / k ⌉ \left \lceil n/k \right \rceil ⌈n/k⌉、这个区域后 n − n % k n-n\%k n−n%k组中每组行数为 ⌊ n / k ⌋ \left \lfloor n/k \right \rfloor ⌊n/k⌋。一个例子如下:
Create table If Not Exists tb(id int, gid int,val int);
insert into tb values (1, 1, 1);
insert into tb values (2, 2, 2);
insert into tb values (3, 1, 3);
insert into tb values (4, 2, 4);
insert into tb values (5, 1, 3);
insert into tb values (6, 2, 6);
insert into tb values (7, 1, 7);
insert into tb values (8, 2, 8);
insert into tb values (9, 1, 9);
select id, gid, ntile(3) over(partition by gid order by id) as ind
from tb;
执行结果:
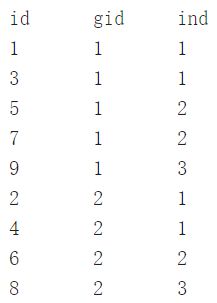
可以看出gid为1的区域中分为三组(ind范围为1~3),前两组的行数为2,剩余一组的行数为1。
参考:
https://zhuanlan.zhihu.com/p/366553723?utm_id=0
https://www.mysqltutorial.org/mysql-window-functions/