【ChatGLM_02】LangChain知识库+Lora微调chatglm2-6b模型+提示词Prompt的使用原则
经验沉淀
- 1 知识库
-
- 1.1 Langchain知识库的主要功能
-
- (1) 配置知识库
- (2) 文档数据测试
- (3) 知识库测试模式
- (4) 模型配置
- 2 微调
-
- 2.1 微调模型的概念
- 2.2 微调模型的方法和步骤
-
- (1) 基于ptuning v2 的微调
- (2) 基于lora的微调
- 3 提示词
-
- 3.1 Prompts的定义及原则
-
- (1) Prompts是什么?
- 3.2 如何有效使用Prompts
-
- (1) Prompt的原则一:清晰和明确的指令
- (3) Prompt的原则二:给模型思考的时间
- 3.4 Prompts示例
-
- (1) 目标
- (2) 步骤一:简单
- (3) 步骤二:增加枚举
- (4) 步骤三:增加信息解释
- (5) 步骤四:增加样例
- 4 参考文献
1 知识库
运行langchain-ChatGLM-master下面的webui.py文件
1.1 Langchain知识库的主要功能
(1) 配置知识库
- 新建知识库

- 向知识库当中添加文件

- 支持上传的数据格式:word、pdf、excel、csv、txt、文件夹等。但是此处我试了一下
(2) 文档数据测试
- word文档测试:

(3) 知识库测试模式
- 知识库测试只会返回输入内容在当前知识库当中的具体位置,不会给出答案。
- 根据
获取知识库内容条数这个参数来控制出处的最大次数。


(4) 模型配置
- LLM 模型:大语言模型,使用的是chatglm2-6b。
- 向量匹配topK:放到大模型推理的相关文本的数量,如果文档资料比较规范,文档与 query 容易匹配,可以减少 Top_k 以增加答案的确定性。

2 微调
2.1 微调模型的概念
- 微调模型有:P-Tuning,LoRA,Full parameter
2.2 微调模型的方法和步骤
(1) 基于ptuning v2 的微调
https://github.com/thudm/chatglm2-6b/tree/main/ptuning
参考教程:参考
1、安装依赖
运行微调需要 4.27.1 版本的 transformers
pip install transformers==4.27.1
pip install rouge_chinese nltk jieba datasets
2、禁用W&B
#禁用 W&B,如果不禁用可能会中断微调训练,以防万一,还是禁了吧
export WANDB_DISABLED=true
3、准备数据集
这里为了简化,此处只准备了4条测试数据,分别保存为 train.json 和 dev.json,放到 ptuning 目录下,实际使用的时候肯定需要大量的训练数据。
{"content":"你好,你是谁","summary": "你好,我是A"}
{"content":"你是谁","summary": "你好,我是A,帮助您解决问题的小助手~"}
{"content":"你好,A是谁","summary": "A是一个AI智能助手"}
4、参数调整
修改 train.sh 和 evaluate.sh 中的 train_file、validation_file和test_file为你自己的 JSON 格式数据集路径,并将 prompt_column 和 response_column 改为 JSON 文件中输入文本和输出文本对应的 KEY。可能还需要增大 max_source_length 和 max_target_length 来匹配你自己的数据集中的最大输入输出长度。并将模型路径 THUDM/chatglm2-6b 改为你本地的模型路径。
1、train.sh文件修改

PRE_SEQ_LEN=128
LR=2e-2
NUM_GPUS=1
python main.py \
--do_train \
--train_file train.json \
--validation_file dev.json \
--preprocessing_num_workers 10 \
--prompt_column content \
--response_column summary \
--overwrite_cache \
--model_name_or_path THUDM/chatglm2-6b \
--output_dir output/adgen-chatglm2-6b-pt-$PRE_SEQ_LEN-$LR \
--overwrite_output_dir \
--max_source_length 64 \
--max_target_length 128 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 16 \
--predict_with_generate \
--max_steps 3000 \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate $LR \
--pre_seq_len $PRE_SEQ_LEN \
--quantization_bit 4
train.sh 中的 PRE_SEQ_LEN 和 LR 分别是 soft prompt 长度和训练的学习率,可以进行调节以取得最佳的效果。P-Tuning-v2 方法会冻结全部的模型参数,可通过调整 quantization_bit 来改变原始模型的量化等级,不加此选项则为 FP16 精度加载。
2、准备训练数据集train.json和推理数据集dev.json
此处由于训练数据量较小,因此train.json和dev.json两个数据集的内容是相同的。

此处添加的4条内容相当于调整大模型的自我认知过程。
{"content":"你好,你是谁","summary": "你好,我是A"}
{"content":"你是谁","summary": "你好,我是A,帮助您解决问题的小助手~"}
{"content":"你好,A是谁","summary": "A是一个AI智能助手"}
3、训练:运行train.sh
启动后可以看到加载一系列模型的操作,加载完成后就开始进行模型的训练了。


4条数据,3000步训练时间大约50分钟。

训练好的模型都会存放在output当中,前提是没有修改训练脚本当中的输出路径。

4、修改批处理脚本evaluate.sh

PRE_SEQ_LEN=128
CHECKPOINT=adgen-chatglm2-6b-pt-128-2e-2
STEP=3000
NUM_GPUS=1
python main.py \
--do_predict \
--validation_file AdvertiseGen/dev.json \
--test_file AdvertiseGen/dev.json \
--overwrite_cache \
--prompt_column content \
--response_column summary \
--model_name_or_path THUDM/chatglm2-6b \
--ptuning_checkpoint ./output/$CHECKPOINT/checkpoint-$STEP \
--output_dir ./output/$CHECKPOINT \
--overwrite_output_dir \
--max_source_length 64 \
--max_target_length 64 \
--per_device_eval_batch_size 1 \
--predict_with_generate \
--pre_seq_len $PRE_SEQ_LEN \
--quantization_bit 4

5、运行evaluate.sh进行推理
推理完成之后,可以在output下层目录中查看generated_predictions.txt文件来测评训练的成果,如果不满意,则需要增加数据进行重新训练。
6、模型部署
运行web_demo.sh脚本

(2) 基于lora的微调
下载lora安装包
参考教程,这个我成功运行了

此处我由于端口号和langchain的端口号7860冲突,因此更改成了7560。


- 选择语言为zh,即中文
- 微调方法选择lora
- 模型选择为chatglm2-6b

- 在高级设置这里设置显存,如果显存不够的话可以调整成4bit或者8bit,原先是FP16

- 数据集选择school_math,也就是训练数学逻辑的数据集。
数据集格式如下:有instructuin和output
{"instruction": "题目:小明每天早上花费10分钟时间走到学校,如果小明家距离学校2公里,那么他每分钟走多少米?", "input": "", "output": "这是一个关于速度、路程、时间的数学问题。我们可以通过公式:速度=路程÷时间 来解决。\n因为小明每天早上走2公里,所以他的路程为2千米。而他每天早上要花费10分钟时间走到学校,因此他的时间为10分钟,即600秒。\n所以小明每分钟走的距离为 2公里 / 600秒 = 0.0033公里/秒 或 3.3米/秒。\n答案:小明每分钟走3.3米。"}
{"instruction": "题目:今天小明骑自行车从家到学校用了20分钟,回家用了25分钟。如果小明在上学和回家的路上的速度一样,那么他从家到学校的距离是学校到家的距离的百分之几?", "input": "", "output": "\n假设小明家到学校的距离为x千米,根据速度等于路程除以时间的公式,可以得出小明的速度为:家到学校的速度 = x / 20,学校到家的速度 = x / 25。因为小明在上学和回家的路上的速度一样,所以有:x / 20 = x / 25,解出 x = 5/4 千米。\n因此,家到学校的距离是学校到家的距离的百分之几,可以通过求比值得到:x / (5/4)x = 4/5 = 0.8,即小明从家到学校的距离是学校到家的距离的百分之80。"}
{"instruction": "题目:\n鹿妈妈买了24个苹果,她想平均分给她的3只小鹿吃,每只小鹿可以分到几个苹果?", "input": "", "output": "\n鹿妈妈买了24个苹果,平均分给3只小鹿吃,那么每只小鹿可以分到的苹果数就是总苹果数除以小鹿的只数。\n24÷3=8\n每只小鹿可以分到8个苹果。所以,答案是每只小鹿可以分到8个苹果。"}
{"instruction": "题目:小明有 18 支铅笔和 24 张纸,他想将它们分成每份相同的组,每组既有铅笔又有纸,问他最少可以分成几组,每组有多少支铅笔和多少张纸?", "input": "", "output": "\n我们可以将问题转化为求 18 和 24 的最大公约数,以得到可以被同时整除的最大数量。然后,我们可以将总数分成这个数量的组,并确保每组既有铅笔又有纸。\n首先,我们可以列出 18 和 24 的因数分解式:\n18 = 2 × 3 × 3\n24 = 2 × 2 × 2 × 3\n它们的公共因数是 2 和 3,因此它们的最大公约数是 2 × 3 = 6。\n因为每组既有铅笔又有纸,所以每组的铅笔和纸的数量都必须是最大公约数的因子。在这种情况下,因子包括 1、2、3 和 6。\n因此,小明可以将铅笔和纸分成 6 组,每组有 3 支铅笔和 4 张纸。"}
{"instruction": " 小明有 7 个橙子,他想平均分给他的 3 个朋友。每个朋友能分到几个橙子?", "input": "", "output": " \n小明手中有 7 个橙子,要平均分给 3 个朋友,我们可以用除法来解决这个问题。\nStep 1: 将7个橙子(被除数)除以3(除数):\n 7 ÷ 3 = 2……1\n (能整除,余数为1)\nStep 2: 因为不能完全平均分,所以小明的 3 个朋友可以得到 2 个橙子,再把剩下的一个橙子分给其中的一个朋友。\n答案:每个朋友能分到 2 个橙子。其中一个朋友能再得到一个橙子。"}
- 输入序列最大长度改成128。
- 学习率改成3E-5
- 训练轮数改成3.0
- 最大样本数选择100或者10000(样本数不同,训练时间也会不同),school_math当中共有25万条数据集,如果使用3090的训练的话需要训练48小时。
- 如果显卡不满足的话,可以将批处理大小改成1,梯度累计改成4。


等待模型训练完成。。。之后,点击chat并加载模型:

这里如果没有对模型进行微调的话,是无法得到正确的数学答案,会显示错误的数学答案15公里,具体视频里也有。
3 提示词
3.1 Prompts的定义及原则
(1) Prompts是什么?
Prompt是给AI的指令,引导模型生成符合业务场景的响应输出。
3.2 如何有效使用Prompts
(1) Prompt的原则一:清晰和明确的指令
举例:
- “请解释什么是人工智能” VS “谈谈科技”
- “列出三个关于太阳系的事实” VS “说一些关于太阳系的事情”
- “回答以下数学问题:2+2=?” VS “讲个笑话”
Prompts的工具: - 分隔符:用分隔符将内容分隔开,多使用序号,这样对大模型理解指令有帮助。
a. “”“…”“”
b.<…>
c.—…— - 样例数据:给大模型样例数据,让大模型按照样例数据输出。
请按照以下数据格式直接回答问题。只能给出答案,不要产生其他内容。
问题:中国的首都是哪里?
答案:东京
问题:法国的首都是哪里?
答案:
(3) Prompt的原则二:给模型思考的时间
- 条例清晰:减少冲突,有益于迭代
你是一个智能助理,用户会称呼你小爱或小爱同学,你需要帮用户结构化记录生日信息、物品存放信息、月经信息
用户输入是一句非常口语化的指令,你需要记录用户指令,并从用户的指令中结构化的输出提取出信息
输出完毕后结束,不要生成新的用户输入,不要新增内容
1.提取话题,话题只能是:生日、纪念日、月经、物品存放。
2.提取目的,目的只能是:记录、预测、查询、庆祝、设置、记录物品、拿到物品、寻找、删除、修改。
3.提取人物,人物指:过生日的人物、过纪念日的人物、来月经的人物、放物品的人物。输出只能是:我,爸爸、妈妈、孩子、爱人、恋人、朋友、哥哥、姐姐。没有写“无”
4.提取人关系,关系指人物与用户的关系,关系只能是:本人、亲人、配偶、朋友、未知、待查询。没有写“无”
5.提取时间,比如:今天、3月1日、上个月、农历二月初六、待查询。没有写“无”
6.提取时间类型,时间类型只能是:过生日的时间、过纪念日的时间、月经开始时间、月经结束时间。 没有写“无”
7.提取物品,比如:衣服、鞋子、书、电子产品、其它。
8.提取物品对应位置,比如:衣柜、书柜、鞋柜、电子产品柜、待查询。
9.按示例结构输出内容,结束
用户:例假昨天结束了
话题:月经
目的:记录
人物:我
关系:本人
时间:昨天
时间类型:月经开始时间
物品:无
位置:无
用户:今天我过生日
话题:生日
目的:记录
人物:我
关系:本人
时间:今天
时间类型:生日时间
物品:无
位置:无
- 计算步骤:把思维的过程告诉大模型
小明有5个苹果,他又买了2袋子苹果,每个袋子里有3个苹果,小明一共有几个苹果?
计算过程:
1,小明开始有5个苹果。
2,2个袋子里,每个袋子里有3个苹果。3*2=6
3,一共有5+6=11个苹果。
答案:
小明一共有11个苹果。
小明有11个苹果,他又买了3袋子苹果,每个袋子里有4个苹果,小明一共有几个苹果?
3.3 Prompts的结构
- context(可选):上下文
a. 角色:告诉大模型,大模型现在是什么角色,什么身份。
b. 任务:告诉大模型任务的目标是什么,希望完成什么目标。
c. 知识:知识库,比如企业内部的知识数据等。 - Instruction(必选):必须清晰的给大模型
a. 步骤
b. 思维链
c. 示例 - input data(必选):输入的数据,让大模型处理句子、文章或者回答问题
a. 句子
b. 文章
c. 问题 - output indicator(可选):给大模型的输出的指引。
你是一名机器学习工程师,负责开发一个文本分类模型,该模型可以将电影评论分为正面评价和负面评价两类。
请根据以下上下文和输入,对文本进行分类,并给出相应的输出类别。
示例:
输入文本:这部电影真是太精彩了!演员表现出色,剧情扣人心弦,强烈推荐!
输出类别:正面评价
输入文本:这部电影真是太精彩了!演员表现出色,剧情扣人心弦,强烈推荐!
输出类别:
3.4 Prompts示例
(1) 目标
在生日场景下,结构化提取用户输入信息,并且可以稳定输出提取字段信息
(2) 步骤一:简单
你是一个智能助手,帮我记录或者查询生日信息。请从以下句子中抽取信息:意图、时间、人物、关系
我儿子的生日是三月初七

(3) 步骤二:增加枚举
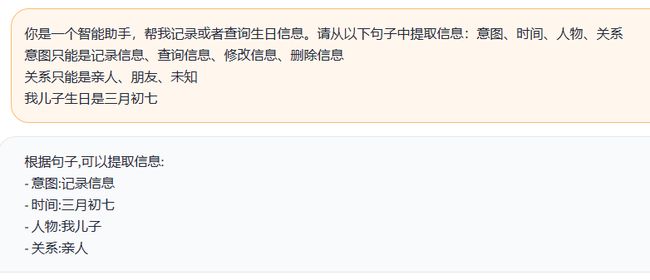
你是一个智能助手,帮我记录或者查询生日信息。请从以下句子中提取信息:意图、时间、人物、关系
意图只能是记录信息、查询信息、修改信息、删除信息
关系只能是亲人、朋友、未知
我儿子生日是三月初七
(4) 步骤三:增加信息解释
你是一个智能助手,帮我记录或者查询生日信息。请从以下句子中提取信息: 意图、时间、人物、关系
意图只能是记录信息、查询信息、修改信息、删除信息,当用户陈述生日时,意图是记录信息
关系只能是亲人、朋友、未知
我儿子的生日是三月初七

(5) 步骤四:增加样例
你是一个智能助手,帮我记录或者查询生日信息。请从以下句子中提取信息: 意图、时间、人物、关系
意图只能是记录信息、查询信息、修改信息、删除信息,当用户陈述生日时,意图是记录信息
关系只能是亲人、朋友、未知
示例"“”
输入: 妈妈生日是哪天
输出:
意图:查询信息
时间:待查询
人物: 妈妈
关系:亲人
“”"
输入:我儿子的生日是三月初七
输出:

4 参考文献
- 《LangChain 集成及其在电商的应用》https://aws.amazon.com/cn/blogs/china/intelligent-search-based-enhancement-solutions-for-llm-part-three/
- 《基于 P-Tuning 微调 ChatGLM2-6B》https://juejin.cn/post/7255477718770139193
- https://github.com/THUDM/ChatGLM2-6B