Spring中的事务
目录
- 一 Spring 与 Mybatis 整合
-
- 1.1 单独使用 Mybatis 的问题
- 1.2 Spring 为啥需要与 Mybatis 整合
- 1.3 Spring 可以与那些持久层技术进⾏整合
- 1.4 Mybatis 的开发步骤
- 1.5 Mybatis 与 Spring 整合
- 1.6 思考?
- 二 Spring 中的事务
-
- 2.1 什么叫事务
- 2.2 事务的 4 大特点
- 2.3 如何控制事务
- 2.4 Spring 支持两种方式的事务管理
-
- 2.4.1 编程式事务
- 2.4.2 声明式事务
- 2.5 Spring 的事务属性
-
- 2.5.1 隔离属性 (ISOLATION)
-
- 2.5.1.1 并发带来的问题?
- 2.5.1.2 事务隔离级别
- 2.5.2 传播属性(PROPAGATION)
-
- 2.5.2.1 **TransactionDefinition.PROPAGATION_REQUIRED**
- 2.5.2.2 **TransactionDefinition.PROPAGATION_REQUIRES_NEW**
- 2.5.2.3 **TransactionDefinition.PROPAGATION_NESTED**
- 2.5.2.4 **TransactionDefinition.PROPAGATION_MANDATORY**
- 2.5.3 只读属性(readOnly)
- 2.5.4 超时属性(timeout)
- 2.5.5 异常属性
- 2.5.6 总结
一 Spring 与 Mybatis 整合
1.1 单独使用 Mybatis 的问题
- 配置繁琐,如果我们单独使用 Mybatis 需要写多个 Mapper 的配置,配置文件臃肿
- 代码冗余,系统中存在冗余代码,特别是 APl 调用的时候
1.2 Spring 为啥需要与 Mybatis 整合
- JavaEE 开发需要持久层进⾏数据库的访问操作
- JDBC Hibernate MyBatis 进⾏持久开发过程存在⼤量的代码冗余
- Spring 基于模板设计模式对于上述的持久层技术进⾏了封装,极大的简化了代码
1.3 Spring 可以与那些持久层技术进⾏整合
1.JDBC
|- JDBCTemplate
2. Hibernate (JPA)
|- HibernateTemplate
3. MyBatis
|- SqlSessionFactoryBean MapperScannerConfigure
1.4 Mybatis 的开发步骤
1. 实体
2. 实体别名
3. 表
4. 创建DAO接⼝
5. 实现Mapper⽂件
6. 注册Mapper⽂件
7. MybatisAPI调⽤
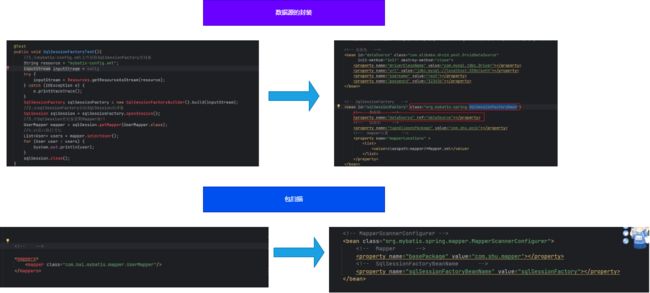
- 数据源的封装,在 Mybatis 中我们用 SqlSessionFactory 来执行增删改查操作,但是在我们的 Spring 中提供了 SqlSessionFactoryBean 这个类来封装数据源的连接
- 包扫描的封装,在我们原来的 Mybatis 中我们需要配置包扫描的方式,在 Spring 中提供了一个 MapperScannerConfigurer 类对我们的接口进行扫描
1.5 Mybatis 与 Spring 整合
- 依赖
<dependencies>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>8.0.31version>
dependency>
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring-jdbcartifactId>
<version>5.1.14.RELEASEversion>
dependency>
<dependency>
<groupId>org.mybatisgroupId>
<artifactId>mybatis-springartifactId>
<version>2.0.2version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>druidartifactId>
<version>1.1.18version>
dependency>
<dependency>
<groupId>org.mybatisgroupId>
<artifactId>mybatisartifactId>
<version>3.4.6version>
dependency>
dependencies>
- 配置文件的配置主要包括:数据源的配置,SqlSessionFactory 的配置,MapperScannerConfigurer 的配置
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:p="http://www.springframework.org/schema/p"
xmlns:aop="http://www.springframework.org/schema/aop" xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/aop https://www.springframework.org/schema/aop/spring-aop.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx.xsd">
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource"
init-method="init" destroy-method="close">
<property name="driverClassName" value="com.mysql.cj.jdbc.Driver">property>
<property name="url" value="jdbc:mysql://localhost:3306/auth">property>
<property name="username" value="root">property>
<property name="password" value="123456">property>
bean>
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="dataSource">property>
<property name="typeAliasesPackage" value="com.shu.pojo">property>
<property name="mapperLocations" >
<list>
<value>classpath:mapper/*Mapper.xmlvalue>
list>
property>
<property name="configLocation" value="classpath:mybatis-config.xml">property>
bean>
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="com.shu.mapper">property>
<property name="sqlSessionFactoryBeanName" value="sqlSessionFactory">property>
bean>
<bean id="UserService" class="com.shu.service.UserService">
<property name="userMapper" ref="userMapper">property>
bean>
beans>
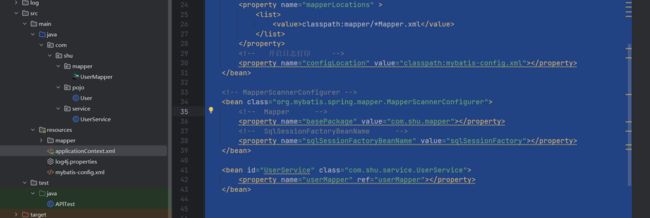
- 代码结构,代码就自己编写吧很简单
- 详细日志配置
<dependency>
<groupId>org.apache.logging.log4jgroupId>
<artifactId>log4j-coreartifactId>
<version>2.6.1version>
dependency>
log4j.properties 配置文件
log4j.rootLogger=DEBUG,console,file
log4j.appender.console = org.apache.log4j.ConsoleAppender
log4j.appender.console.Target = System.out
log4j.appender.console.Threshold=DEBUG
log4j.appender.console.layout = org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=[%c]-%m%n
log4j.appender.file = org.apache.log4j.RollingFileAppender
log4j.appender.file.File=log/tibet.log
log4j.appender.file.MaxFileSize=10mb
log4j.appender.file.Threshold=ERROR
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=[%p][%d{yy-MM-dd}][%c]%m%n
log4j.logger.org.mybatis=DEBUG
log4j.logger.java.sql=DEBUG
log4j.logger.java.sql.Statement=DEBUG
log4j.logger.java.sql.ResultSet=DEBUG
log4j.logger.java.sql.PreparedStatement=INFO
mybatis-config.xml 配置文件
DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<settings>
<setting name="logImpl" value="STDOUT_LOGGING">setting>
settings>
configuration>
- 编写测试代码
import com.shu.mapper.UserMapper;
import com.shu.pojo.User;
import com.shu.service.UserService;
import org.junit.Test;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
/**
* @description:
* @author: shu
* @createDate: 2023/7/26 9:45
* @version: 1.0
*/
public class APlTest {
@Test
public void MybatisTest(){
ApplicationContext factory = new ClassPathXmlApplicationContext("applicationContext.xml");
UserService userService = factory.getBean("UserService", UserService.class);
userService.getUser();
userService.addUser();
userService.updateUser();
}
}

1.6 思考?
Spring 与 Mybatis 整合后,为什么 DAO 不提交事务,但是数据能够插⼊数据库中?
Connection --> tx Mybatis(Connection) 本质上控制连接对象
(Connection) —> 连接池(DataSource)
- Mybatis 提供的连接池对象 —> 创建 Connection Connection.setAutoCommit(false) ⼿⼯的控制了事务 , 操作完成后,⼿ ⼯提交
- Druid(C3P0 DBCP)作为连接池 —> 创建 Connection Connection.setAutoCommit(true) true 默认值 保持⾃动控制事务,⼀条 sql ⾃动提交
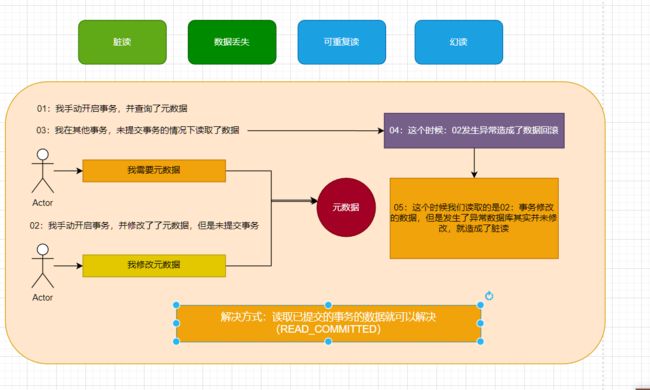
- 答案:因为 Spring 与 Mybatis 整合时,引⼊了外部连接池对象,保持⾃动的事务提交这 个机制(Connection.setAutoCommit(true)),不需要⼿⼯进⾏事务的操作,也能进 ⾏事务的提交
- 注意:未来实战中,还会⼿⼯控制事务(多条 sql ⼀起成功,⼀起失败),后续 Spring 通过 事务控制解决这个问题
二 Spring 中的事务
2.1 什么叫事务
事务是逻辑上的一组操作,要么都执行,要么都不执行。
我们系统的每个业务方法可能包括了多个原子性的数据库操作,比如下面的 savePerson() 方法中就有两个原子性的数据库操作。这些原子性的数据库操作是有依赖的,它们要么都执行,要不就都不执行。
public void savePerson() {
personDao.save(person);
personDetailDao.save(personDetail);
}
另外,需要格外注意的是:事务能否生效数据库引擎是否支持事务是关键。比如常用的 MySQL 数据库默认使用支持事务的innodb引擎。但是,如果把数据库引擎变为 myisam,那么程序也就不再支持事务了!
事务最经典也经常被拿出来说例子就是转账了。假如小明要给小红转账 1000 元,这个转账会涉及到两个关键操作就是:
- 将小明的余额减少 1000 元
- 将小红的余额增加 1000 元。
万一在这两个操作之间突然出现错误比如银行系统崩溃或者网络故障,导致小明余额减少而小红的余额没有增加,这样就不对了。事务就是保证这两个关键操作要么都成功,要么都要失败。
2.2 事务的 4 大特点

**原子性:**原子性是指事务是一个不可分割的工作单位,事务中的操作要么全部成功,要么全部失败。比如在同一个事务中的 SQL 语句,要么全部执行成功,要么全部执行失败。
begin transaction;
update account set money = money-100 where name = '张三';
update account set money = money+100 where name = '李四';
commit transaction;
**一致性:**事务必须使数据库从一个一致性状态变换到另外一个一致性状态。
换一种方式理解就是:事务按照预期生效,数据的状态是预期的状态。
举例说明:张三向李四转 100 元,转账前和转账后的数据是正确的状态,这就叫一致性,如果出现张三转出 100 元,李四账号没有增加 100 元这就出现了数据错误,就没有达到一致性。
**隔离性:**事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。
持久性: 持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响。
例如我们在使用 JDBC 操作数据库时,在提交事务方法后,提示用户事务操作完成,当我们程序执行完成直到看到提示后,就可以认定事务以及正确提交,即使这时候数据库出现了问题,也必须要将我们的事务完全执行完成,否则就会造成我们看到提示事务处理完毕,但是数据库因为故障而没有执行事务的重大错误。
2.3 如何控制事务
JDBC:
Connection.setAutoCommit(false);
Connection.commit();
Connection.rollback();
Mybatis:
Mybatis⾃动开启事务
sqlSession(Connection).commit();
sqlSession(Connection).rollback();
结论:控制事务的底层 都是Connection对象完成的。
2.4 Spring 支持两种方式的事务管理
2.4.1 编程式事务
通过 TransactionTemplate或者TransactionManager手动管理事务,实际应用中很少使用,但是对于你理解 Spring 事务管理原理有帮助。
@Autowired
private TransactionTemplate transactionTemplate;
public void testTransaction() {
transactionTemplate.execute(new TransactionCallbackWithoutResult() {
@Override
protected void doInTransactionWithoutResult(TransactionStatus transactionStatus) {
try {
// .... 业务代码
} catch (Exception e){
//回滚
transactionStatus.setRollbackOnly();
}
}
});
}
@Autowired
private PlatformTransactionManager transactionManager;
public void testTransaction() {
TransactionStatus status = transactionManager.getTransaction(new DefaultTransactionDefinition());
try {
// .... 业务代码
transactionManager.commit(status);
} catch (Exception e) {
transactionManager.rollback(status);
}
}
2.4.2 声明式事务
推荐使用(代码侵入性最小),实际是通过 AOP 实现(基于@Transactional 的全注解方式使用最多)。
@Transactional(propagation=propagation.PROPAGATION_REQUIRED)
public void aMethod {
//do something
B b = new B();
C c = new C();
b.bMethod();
c.cMethod();
}
2.5 Spring 的事务属性
事务属性:描述事务特征的⼀系列值 1. 隔离属性 2. 传播属性 3. 只读属性 4. 超时属性 5. 异常属性
参考文章:https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485085&idx=1&sn=01e5c29c49f32886bc897af7632b34ba&chksm=cea24956f9d5c040a07e4d335219f11f888a2d32444c16cade3f69c294ae0a1e416bcd221fb6&token=1613452699&lang=zh_CN&scene=21#wechat_redirect
2.5.1 隔离属性 (ISOLATION)
2.5.1.1 并发带来的问题?
在典型的应用程序中,多个事务并发运行,经常会操作相同的数据来完成各自的任务(多个用户对统一数据进行操作)。并发虽然是必须的,但可能会导致以下的问题。
•脏读(Dirty read): 当一个事务正在访问数据并且对数据进行了修改,而这种修改还没有提交到数据库中,这时另外一个事务也访问了这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据,那么另外一个事务读到的这个数据是“脏数据”,依据“脏数据”所做的操作可能是不正确的。
@Transactional(isolation=Isolation.READ_COMMITTED)
我们来看下面的一个关键代码:
/**
* 模拟事务脏读
*/
@Test
public void dirtyReadTest(){
ApplicationContext factory = new ClassPathXmlApplicationContext("applicationContext.xml");
UserTestService userService = factory.getBean("userTestService", UserTestService.class);
TransactionService transactionService = factory.getBean("transactionService", TransactionService.class);
int userId = 1;
// 开启事务
TransactionStatus transactionStatus1 = transactionService.begin();
BigDecimal initialBalance = userService.readBalance(userId);
System.out.println("Initial Balance for User ID " + userId + ": " + initialBalance);
// 在另一个线程中更新用户余额
new Thread(() -> {
TransactionService transactionService1 = factory.getBean("transactionService", TransactionService.class);
TransactionStatus transactionStatus = transactionService1.begin();
userService.updateBalance(userId, initialBalance.subtract(BigDecimal.valueOf(500.00)));
BigDecimal bigDecimal = userService.readBalance(userId);
System.out.println("Balance after dirty read: " + bigDecimal);
// 休眠3
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}
transactionService1.rollback(transactionStatus);
}).start();
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 提交事务
transactionService.commit(transactionStatus1);
// 读取用户余额
BigDecimal balanceAfterCommit = userService.readBalance(userId);
System.out.println("Balance after commit: " + balanceAfterCommit);
}

开启事务我们先查询了一下原来的数据,为 8500
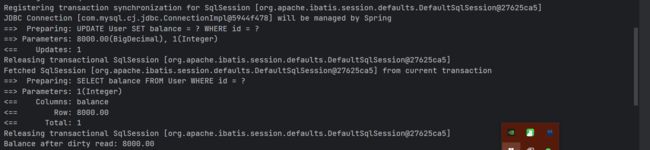
在一个新线程中手动开启事务并行修改数据,但是注意事务并没有提交,有查询了一下余额
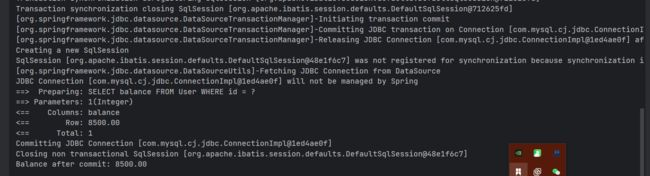
之后线程中进行了事务的回滚,而数据库中没有发生修改
•不可重复读(Unrepeatableread): 指在一个事务内多次读同一数据。在这个事务还没有结束时,另一个事务也访问该数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改导致第一个事务两次读取的数据可能不太一样。这就发生了在一个事务内两次读到的数据是不一样的情况,因此称为不可重复读。
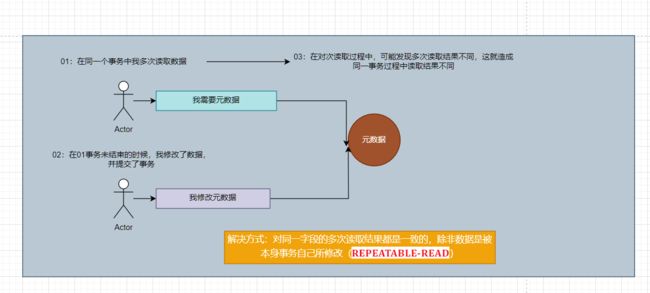
解决⽅案 @Transactional(isolation=Isolation.REPEATABLE_READ)
本质: ⼀把⾏锁
•幻读(Phantom read): 幻读与不可重复读类似。它发生在一个事务(T1)读取了几行数据,接着另一个并发事务(T2)插入了一些数据时。在随后的查询中,第一个事务(T1)就会发现多了一些原本不存在的记录,就好像发生了幻觉一样,所以称为幻读。
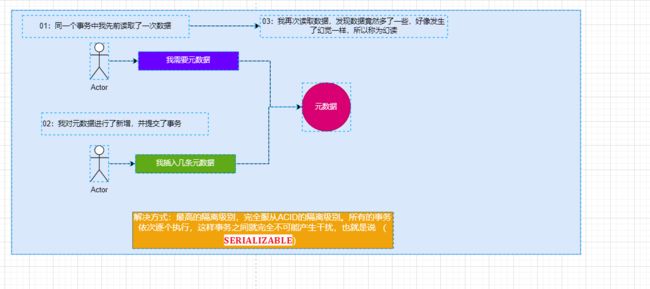
解决⽅案 @Transactional(isolation=Isolation.SERIALIZABLE)
本质:表锁
不可重复度和幻读区别:
不可重复读的重点是修改,幻读的重点在于新增或者删除。
例 1(同样的条件, 你读取过的数据, 再次读取出来发现值不一样了 ):事务 1 中的 A 先生读取自己的工资为 1000 的操作还没完成,事务 2 中的 B 先生就修改了 A 的工资为 2000,导 致 A 再读自己的工资时工资变为 2000;这就是不可重复读。
例 2(同样的条件, 第 1 次和第 2 次读出来的记录数不一样 ):假某工资单表中工资大于 3000 的有 4 人,事务 1 读取了所有工资大于 3000 的人,共查到 4 条记录,这时事务 2 又插入了一条工资大于 3000 的记录,事务 1 再次读取时查到的记录就变为了 5 条,这样就导致了幻读。
2.5.1.2 事务隔离级别
SQL 标准定义了四个隔离级别:
•READ-UNCOMMITTED(读取未提交): 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读
•READ-COMMITTED(读取已提交): 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生
•REPEATABLE-READ(可重读): 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
•SERIALIZABLE(可串行化): 最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
数据库对于隔离属性的⽀持
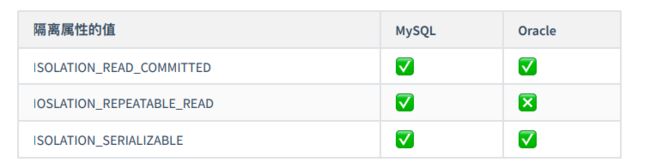
Oracle不⽀持REPEATABLE_READ值 如何解决不可重复读
采⽤的是多版本⽐对的⽅式 解决不可重复读的问题
默认隔离属性
ISOLATION_DEFAULT:会调⽤不同数据库所设置的默认隔离属性
MySQL : REPEATABLE_READ
Oracle: READ_COMMITTED
查看数据库默认隔离属性
Mysql
select @@tx_isolation
这里需要注意的是:与 SQL 标准不同的地方在于 InnoDB 存储引擎在 REPEATABLE-READ(可重读)事务隔离级别下使用的是 Next-Key Lock 锁算法,因此可以避免幻读的产生,这与其他数据库系统(如 SQL Server)是不同的。所以说 InnoDB 存储引擎的默认支持的隔离级别是 REPEATABLE-READ(可重读) 已经可以完全保证事务的隔离性要求,即达到了 SQL 标准的 SERIALIZABLE(可串行化)隔离级别。 因为隔离级别越低,事务请求的锁越少,所以大部分数据库系统的隔离级别都是 READ-COMMITTED(读取提交内容):,但是你要知道的是 InnoDB 存储引擎默认使用 REPEATABLE-READ(可重读)并不会有任何性能损失。 InnoDB 存储引擎在 分布式事务 的情况下一般会用到 SERIALIZABLE(可串行化)隔离级别。 Oracle
SELECT s.sid, s.serial#,
CASE BITAND(t.flag, POWER(2, 28))
WHEN 0 THEN 'READ COMMITTED'
ELSE 'SERIALIZABLE'
END AS isolation_level
FROM v$transaction t
JOIN v$session s ON t.addr = s.taddr
AND s.sid = sys_context('USERENV', 'SID');
2.5.2 传播属性(PROPAGATION)
参考博客:https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247486668&idx=2&sn=0381e8c836442f46bdc5367170234abb&chksm=cea24307f9d5ca11c96943b3ccfa1fc70dc97dd87d9c540388581f8fe6d805ff548dff5f6b5b&token=1776990505&lang=zh_CN#rd
概念:他描述了事务解决嵌套问题的特征
什么叫做事务的嵌套:他指的是⼀个⼤的事务中,包含了若⼲个⼩的事务 问题:⼤事务中融⼊了很多⼩的事务,他们彼此影响,最终就会导致外部⼤的事务,丧失了 事务的原⼦性
我们在 A 类的aMethod()方法中调用了 B 类的 bMethod() 方法。这个时候就涉及到业务层方法之间互相调用的事务问题。如果我们的 bMethod()如果发生异常需要回滚,如何配置事务传播行为才能让 aMethod()也跟着回滚呢?这个时候就需要事务传播行为的知识了,如果你不知道的话一定要好好看一下。
Class A {
@Transactional(propagation=propagation.xxx)
public void aMethod {
//do something
B b = new B();
b.bMethod();
}
}
Class B {
@Transactional(propagation=propagation.xxx)
public void bMethod {
//do something
}
}
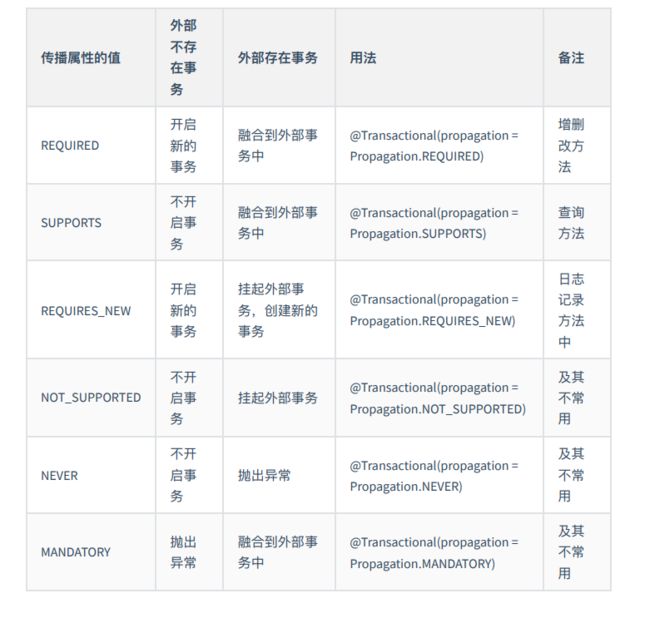
2.5.2.1 TransactionDefinition.PROPAGATION_REQUIRED
使用的最多的一个事务传播行为,我们平时经常使用的@Transactional注解默认使用就是这个事务传播行为。如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。也就是说:
- 如果外部方法没有开启事务的话,Propagation.REQUIRED修饰的内部方法会新开启自己的事务,且开启的事务相互独立,互不干扰。
- 如果外部方法开启事务并且被Propagation.REQUIRED的话,所有Propagation.REQUIRED修饰的内部方法和外部方法均属于同一事务 ,只要一个方法回滚,整个事务均回滚。
举个例子:如果我们上面的aMethod()和bMethod()使用的都是PROPAGATION_REQUIRED传播行为的话,两者使用的就是同一个事务,只要其中一个方法回滚,整个事务均回滚。
Class A {
@Transactional(propagation=propagation.PROPAGATION_REQUIRED)
public void aMethod {
//do something
B b = new B();
b.bMethod();
}
}
Class B {
@Transactional(propagation=propagation.PROPAGATION_REQUIRED)
public void bMethod {
//do something
}
}
2.5.2.2 TransactionDefinition.PROPAGATION_REQUIRES_NEW
创建一个新的事务,如果当前存在事务,则把当前事务挂起。也就是说不管外部方法是否开启事务,Propagation.REQUIRES_NEW修饰的内部方法会新开启自己的事务,且开启的事务相互独立,互不干扰。
举个例子:如果我们上面的bMethod()使用PROPAGATION_REQUIRES_NEW事务传播行为修饰,aMethod还是用PROPAGATION_REQUIRED修饰的话。如果aMethod()发生异常回滚,bMethod()不会跟着回滚,因为 bMethod()开启了独立的事务。但是,如果 bMethod()抛出了未被捕获的异常并且这个异常满足事务回滚规则的话,aMethod()同样也会回滚,因为这个异常被 aMethod()的事务管理机制检测到了。
Class A {
@Transactional(propagation=propagation.PROPAGATION_REQUIRED)
public void aMethod {
//do something
B b = new B();
b.bMethod();
}
}
Class B {
@Transactional(propagation=propagation.REQUIRES_NEW)
public void bMethod {
//do something
}
}
2.5.2.3 TransactionDefinition.PROPAGATION_NESTED
如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于TransactionDefinition.PROPAGATION_REQUIRED。也就是说:
- 在外部方法未开启事务的情况下Propagation.NESTED和Propagation.REQUIRED作用相同,修饰的内部方法都会新开启自己的事务,且开启的事务相互独立,互不干扰。
- 如果外部方法开启事务的话,Propagation.NESTED修饰的内部方法属于外部事务的子事务,外部主事务回滚的话,子事务也会回滚,而内部子事务可以单独回滚而不影响外部主事务和其他子事务。
这里还是简单举个例子:
如果 aMethod() 回滚的话,bMethod()和bMethod2()都要回滚,而bMethod()回滚的话,并不会造成 aMethod() 和bMethod()回滚。
Class A {
@Transactional(propagation=propagation.PROPAGATION_REQUIRED)
public void aMethod {
//do something
B b = new B();
b.bMethod();
b.bMethod2();
}
}
Class B {
@Transactional(propagation=propagation.PROPAGATION_NESTED)
public void bMethod {
//do something
}
@Transactional(propagation=propagation.PROPAGATION_NESTED)
public void bMethod2 {
//do something
}
}
2.5.2.4 TransactionDefinition.PROPAGATION_MANDATORY
如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。(mandatory:强制性)
这个使用的很少,就不举例子来说了。
若是错误的配置以下 3 种事务传播行为,事务将不会发生回滚,这里不对照案例讲解了,使用的很少。
- TransactionDefinition.PROPAGATION_SUPPORTS: 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
- TransactionDefinition.PROPAGATION_NOT_SUPPORTED: 以非事务方式运行,如果当前存在事务,则把当前事务挂起。
- TransactionDefinition.PROPAGATION_NEVER: 以非事务方式运行,如果当前存在事务,则抛出异常。
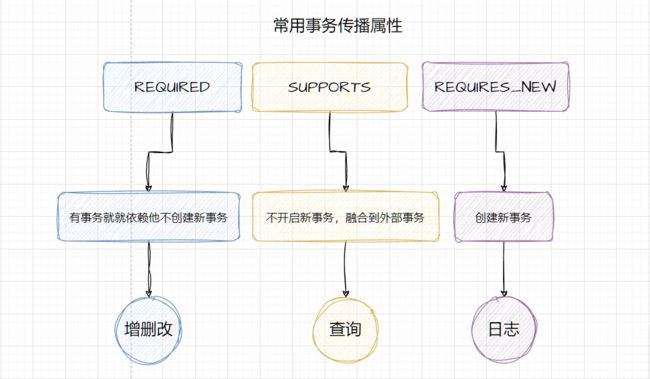
2.5.3 只读属性(readOnly)
针对于只进⾏查询操作的业务⽅法,可以加⼊只读属性,提供运⾏效率
分享一下关于事务只读属性,其他人的解答:
- 如果你一次执行单条查询语句,则没有必要启用事务支持,数据库默认支持 SQL 执行期间的读一致性;
- 如果你一次执行多条查询语句,例如统计查询,报表查询,在这种场景下,多条查询 SQL 必须保证整体的读一致性,否则,在前条 SQL 查询之后,后条 SQL 查询之前,数据被其他用户改变,则该次整体的统计查询将会出现读数据不一致的状态,此时,应该启用事务支持
2.5.4 超时属性(timeout)
指定了事务等待的最⻓时间
为什么事务进⾏等待? 当前事务访问数据时,有可能访问的数据被别的事务进⾏加锁的处理,那么此时本事务就必须 进⾏等待。等待时间 秒,@Transactional(timeout=2) ,超时属性的默认值 -1 最终由对应的数据库来指定
2.5.5 异常属性
- Spring 事务处理过程中 默认 对于 RuntimeException 及其⼦类 采⽤的是回滚的策略 默认 对于 Exception 及其⼦类 采⽤的是提交的策略
rollbackFor = {java.lang.Exception,xxx,xxx} noRollbackFor = {java.lang.RuntimeException,xxx,xx}
@Transactional(rollbackFor = {java.lang.Exception.class},noRollbackFor = {java.lang.RuntimeException.class})
- 建议:实战中使⽤ RuntimeExceptin 及其⼦类 使⽤事务异常属性的默认值
2.5.6 总结
1. 隔离属性 默认值
2. 传播属性 Required(默认值) 增删改 Supports 查询操作
3. 只读属性 readOnly false 增删改 true 查询操作
4. 超时属性 默认值 -1
5. 异常属性 默认值
增删改操作 @Transactional
查询操作
@Transactional(propagation=Propagation.SUPPORTS,readOnly=true)
面试参考:https://juejin.cn/post/7215188852850409528