React 论文《ReAct: Synergizing Reasoning and Acting in Language Models》阅读笔记
文章目录
-
- 1. 简介
-
- 论文摘要翻译
- 动机和主要贡献
- 2. REACT : SYNERGIZING *RE*ASONING + *ACT*ING
- 3. KNOWLEDGE-INTENSIVE REASONING TASKS
-
- 3.1 设置
- 3.2 方法
- 3.3 结果和观察
- 4. 决策任务
- 5. 参考资料
1. 简介
论文摘要翻译
虽然大型语言模型(LLM)在自然语言理解和交互式决策制定等任务中表现出了令人印象深刻的性能,但它们的推理(例如思维链提示)和行动(例如行动计划生成)能力主要被作为单独的主题进行研究。 在本文中,我们探索使用 LLM 以交错的方式生成推理轨迹和特定于任务的动作,从而实现两者之间更大的协同作用:推理轨迹帮助模型归纳、跟踪和更新行动计划以及处理异常,而行动允许它与外部源(例如知识库或环境)交互并收集附加信息。
我们将名为 ReAct 的方法应用于多种语言理解和决策任务,并展示了其相比于SOTA基线的有效性以及改进了人类可解释性和可信度。 具体来说,在问答(HotpotQA)和事实验证(Fever)数据集上,ReAct 通过与简单的维基百科 API 交互,克服了思维链推理中普遍存在的幻觉和错误传播问题;并生成类似人类的任务解决轨迹,比没有推理轨迹的基线更具可解释性。 此外,在两个交互式决策基准(ALFWorld 和 WebShop)上,ReAct仅需要一两个上下文示例进行提示,而其成功率分别优于模仿和强化学习方法达34% 和10%。
动机和主要贡献
人类智能的一个独特特征是能够将面向任务的行动与言语推理(verbal reasoning)(或内心推理inner speech)无缝结合起来。而“行动”和“推理”之间的紧密协同作用使人类能够快速学习新任务并执行稳健的决策或推理,即使在以前未见过的情况下或面临信息不确定性时。比如在厨房做饭的例子:在任意两个具体行动之间,我们可能会用语言进行推理,以便跟踪进度(“既然所有材料都切好了,我应该把水壶的水加热一下”),处理异常情况或根据实际情况调整计划(“盐用完了,用酱油和胡椒来代替吧”),并意识到何时需要外部信息(“如何准备面团?让我在网上搜索一下”)。我们还可以采取行动如打开食谱阅读菜谱、打开冰箱、检查食材等来支持推理并回答问题如“我现在可以做什么菜?”
因为大模型的涌现能力,思维链方法(chain of thought, COT)可以用来对算法、常识和符号推理等任务得到答案,但是这种思维链方法是一个静态的黑匣子,模型用自己的内部表示来生成想法,所以可能会导致推理过程出现事实幻觉和错误传播等问题(下图的1b示例)。
目前也有不少工作是用大模型在交互环境中进行规划和行动(planning and acting),但是这些方法没有考虑用大模型来对更高阶的任务进行推理。
所以本文提出ReAct框架用语言模型结合推理和行动,它prompt LLM用一种交互性的方式生成与任务相关的言语推理轨迹和动作,这使得模型能够执行动态推理来创建、维护和调整高级行动计划(行动的理由),同时与外部环境(例如维基百科)交互将附加信息纳入推理(行为到推理)。
论文的主要贡献如下:
- 引入了 ReAct,一种新颖的基于提示的范式,可以在语言模型中协同推理和行动来解决一般任务;
- 在不同的基准上进行了大量的实验,以展示 ReAct 在few-shot学习设置中相对于单独执行推理或动作生成的方法的优势;
- 展示系统的消融和分析实验,以了解推理任务中的行动和交互任务中推理的重要性;
- 分析了 ReAct 在提示设置下的局限性(即对推理和行动行为的支持有限),并进行初步微调实验,显示通过额外的训练数据可以改进ReAct 的潜力。在更多的任务上应用ReAct,并将其与强化学习等相结合,可以进一步释放大型语言模型的潜力。

2. REACT : SYNERGIZING REASONING + ACTING
对于一个与环境交互来解决任务的agent,在时刻t,一个agent从环境中收到了观察 o t ∈ O o_t \in \mathcal{O} ot∈O,并且遵循策略 π ( a t ∣ c t ) \pi(a_t|c_t) π(at∣ct)采取动作 a t ∈ A a_t \in \mathcal{A} at∈A,其中 c t = ( o 1 , a 1 , ⋯ , o t − 1 , a t − 1 , o t ) c_t = (o_1, a_1, \cdots, o_{t-1}, a_{t-1}, o_t) ct=(o1,a1,⋯,ot−1,at−1,ot)是agent的上下文(context)。当 c t → a t c_t \rightarrow a_t ct→at的映射是隐形的并且需要大量计算时,学习一个策略是有挑战的。 比如在上图的(1c)和(2a)都没有执行最终的正确动作。
而ReAct的思想很简单:将agent的动作空间增强变成 A ^ = A ∪ L \hat{\mathcal{A}} = \mathcal{A} \cup \mathcal{L} A^=A∪L, 其中的 L \mathcal{L} L是语言空间。一个属于语言空间的动作 a t ^ ∈ L \hat{a_t} \in \mathcal{L} at^∈L,被称为thought 或reasoning trace,它不影响外部环境,因此也不会有观察反馈。一个thought a t ^ \hat{a_t} at^意在对现有上下文 c t c_t ct推理来组合出有用的信息,并更新上下文 c t + 1 = ( c t , a t ^ ) c_{t+1} = (c_t, \hat{a_t}) ct+1=(ct,at^)以支持将来的推理或动作。
在上面的图1中,有用的thought的类型不定:
- 拆分任务目标和创建行动计划(2b,Act 1; 1d, Thought 1)
- 注入解决任务相关的常识知识(2b, Act 1)
- 从观察中抽取重要的信息(1d, Thought2,4)
- 跟踪进度和行动计划(2b, Act8)
- 处理异常和调整行动计划(1d, Thought 3)等等
因为语言空间 L \mathcal{L} L是无限的,从这个增强空间学习是困难的并且需要很强的语言先验知识。在本文中,作者主要使用语言模型:PaLM-540B,在解决任务时使用few-shot上下文例子prompt模型来生成领域相关的动作或者thought,比如上面图中的(1d),(2b)。
每一个上下文例子是人工生成的用来解决任务实例的动作、thoughts和环境观察的轨迹,在论文附录C中展示了,比如对于HOTPOTQA的上下文例子如下:
"""
Question What is the elevation range for the area that the eastern sector of the Colorado orogeny extends into?
Thought 1 I need to search Colorado orogeny, find the area that the eastern sector of the Colorado orogeny extends into, then find the elevation range of the area.
Action 1 Search[Colorado orogeny]
Observation 1 The Colorado orogeny was an episode of mountain building (an orogeny) in Colorado and surrounding areas.
Thought 2 It does not mention the eastern sector. So I need to look up eastern sector. Action 2 Lookup[eastern sector]
Observation 2 (Result 1 / 1) The eastern sector extends into the High Plains and is called the Central Plains orogeny.
Thought 3 The eastern sector of Colorado orogeny extends into the High Plains. So I need to search High Plains and find its elevation range.
Action 3 Search[High Plains]
Observation 3 High Plains refers to one of two distinct land regions
Thought 4 I need to instead search High Plains (United States).
Action 4 Search[High Plains (United States)]
Observation 4 The High Plains are a subregion of the Great Plains. From east to west, the High Plains rise in elevation from around 1,800 to 7,000 ft (550 to 2,130 m).[3]
Thought 5 High Plains rise in elevation from around 1,800 to 7,000 ft, so the answer is 1,800 to 7,000 ft.
Action 5 Finish[1,800 to 7,000 ft]
"""
对于推理更重要的任务(上图中的(1)),作者们交替生成thoughts和action,所以任务轨迹是包括多个“thought-action-observation"步骤。 而对于像上图中的(2)的决策任务会涉及到很多动作,thoughts只需要在轨迹中最相关位置稀疏的出现,所以作者们让语言模型自行决定thought和动作的异步发生。
因为ReAct包括决策和推理能力,所以作者们认为它有几个独特特征:
- Intuitive and easy to design:人类标注员将自己采取动作时的想法写上就可以了,没有特别的格式要求。
- General and flexible:因为不限格式,thought空间也没有限制,所以适用且不限于各种任务:QA、事实验证、文字游戏、网页浏览等。
- Performant and robust: 只用1-6个上下文例子,ReAct对新的例子显示出强的泛化性,在不同领域内相比于只推理或只行动的基线效果都更好。
- Human aligned and controllable: ReAct的轨迹是可解释的,人很容易检查推理和事实的准确性。并且在过程中人也可以编辑thought来进行控制和纠正agent的行为(如论文第四节的Figure 5,这一点暂时还有点疑问)。
3. KNOWLEDGE-INTENSIVE REASONING TASKS
以多跳问答和事实校验来说明知识密集型推理任务,在上图的(1d)中,通过与Wikipedia API交互演示了推理和行动的协同作用,ReAct可以检索信息来支持推理,并推理来决定检索什么内容。
3.1 设置
- 领域:两个数据集:HotPotQA多跳问答数据集和FEVER事实确认数据集,对两个任务只考虑问题作为输入的情形。
- 动作空间:用Wikipedia API来支持交互性检索,有三种动作类型:1. search[entity],返回实体wiki页面对应的开头5个句子,或者Wikipedia搜索引擎建议的最相似的5个实体。 2. lookup[string],查找在页面中包括string的下一个句子,类似于浏览器中的Ctrl+F快捷键。3. finish[answer],用答案结束当前任务。
3.2 方法
-
ReAct Promping: 从训练集中随机选取样本并人工标注作为few-shot例子,HotpotQA是6个例子,Fever是3个例子,作者们试验发现更多例子不会提升性能。如上图的1d所示,更多的例子在论文附录C,注意作者在写例子的时候,尝试了:
- 问题分解(“I need to search x, find y, then find z”)
- 从Wikipedia页面中提取信息 (“x was started in 1844”, “The paragraph does not tell x”)
- 进行常识推理(“x is not y, so z must instead be…”)
- 算数推理 (“1844 < 1989”)
- 引重新定义搜索内容(“maybe I can search/look up x instead”)
- 合成答案 (“…so the answer is x”).
-
基线:将ReAct与如下几种基线对比:
- Standard Promping(Standard): 也就是ReAct去掉所有的thought、actions、observation,如上面图片中的1a。
- Chain-of-thought prompting(CoT):也就是现在流行的思维链,也就是ReAct去掉actions、observation,作为只有推理的基线,如上面图片中的1b。另外还比较了self-consistency baselin(CoT-SC),它取temperature=0.7 并采样21条CoT轨迹后采用大多数答案。
- Acting-only prompt (Act),去掉React中thought,如上面图片中的1c。
-
组合内外部知识:因为ReAct更基于事实,而CoT在推理结构上更准确,但是容易产生幻觉事实或thought,所以合并了ReAct和CoT-SC,基于如下启发式规则让模型决定什么切换到另一种方法:
- ReAct → \rightarrow → CoT-SC:当ReAct在指定步数内无法返回答案,则切换到CoT-SC,对HotpotQA设定为7步,Fever设定为5步。
- CoT-SC → \rightarrow → ReAct: 当n个CoT-SC样本的多数答案少于n/2时,则切换到ReAct。
-
Finetuning: 使用boostraping方法生成3000条正确的React轨迹微调小一点的语言模型PaLM-8/62B。
3.3 结果和观察
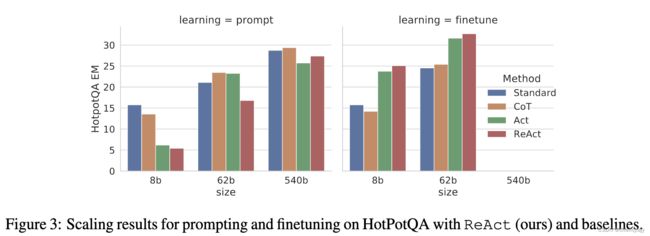
- ReAct 比Act效果更好:下面图片中的表1显示ReAcT在两个任务上都比Act效果更好,特别是合成最后的答案时(如上面图片中1c-d)。在后面图片中的Figure 3也表明在Fine-tuning后推理也是有益处的。

- ReAct vs. CoT: 上面图片中显示ReAct在Fever数据集上比CoT要好,在HotpotQA上比CoT要差。而为了更好的理解ReAct和CoT在HotpotQA上的行为区别,随机从对ReAct和COT各采样50条正确和错误的轨迹(共200条),然后人工标记它们的成功和错误模式,如下图的表2所示,一些关键结果如下,在论文附录E.1给了详细例子:
- CoT的幻觉是一个严重问题,在成功模式下相比ReAct有更高的假阳性(14% vs 6%),并且造成了56%的错误。 而ReAct因为有外部知识库的存在更基于事实、更可信。
- React的reasoning、action、observation步骤交替进行的结构让它更可靠,但是也限制了推理步骤的灵活性,所以React相比与CoT有更多的推理错误。 ReAct有一个明显的错误倾向是不断的重复之前的thought和actions,作者将它们归纳为”reasoning error"。
- 对于React,从搜索中成功地检索出有用的知识很关键,无用的搜索造成23%的错误案例。

- ReAct + CoT-SC是更好的prompt方式, 在上面图片的表1中ReAct → \rightarrow → CoT-SC和 CoT-SC → \rightarrow → ReAct分别是在HotpotQA和Fever上最好的prompt方式。下面的Figure 2展示了CoT-SC中不同样本数时的效果。这个结果表明了推理任务将内部知识和外部知识恰当的组合起来的价值。
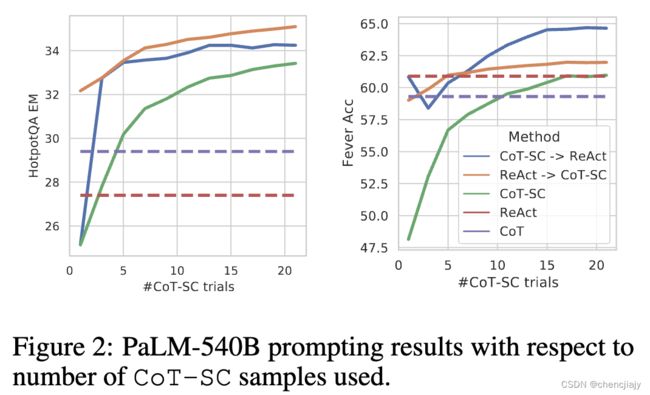
- ReAct方法在fine-tuning时表现最好,如下图的Figure 3显示了四种方法在HotpotQA上prompting和finetuning的对比所示。 作者们相信如果用更大的标注数据集去finetuning,有可能会比最先进的有监督的方法效果更好。
4. 决策任务
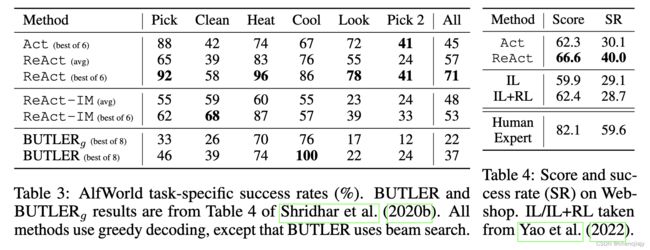
在ALFWorld和WebShop两个数据集上测试了ReAct的效果。
结果如下图中的table 3和table 4, ReAct在两个数据集上都优于Act。
5. 参考资料
- Yao, Shunyu, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2022. “ReAct: Synergizing Reasoning and Acting in Language Models,” October.
- 论文主页