吴恩达教授深度学习--神经风格转换算法
本文所使用的代码和测试图片已上传至百度网盘https://pan.baidu.com/s/1R-z7L95iQIDBpAF32sgWFg,提取码:b4cg。
什么是神经风格迁移?
假设你有一张内容图片C(Content)和一张具有独特风格S(Style)的图片,神经风格迁移可以让这两张图片结合,让原始图片具有图片S的风格。所以神经风格迁移可以解决的问题是:生成一张同时具有图片C的内容和图片S的风格的新图片G。比如下图:

要学习神经风格迁移算法,首先我们要知道什么是迁移学习。深度学习最强大的理念之一就是,神经网络可以从一个认为中习得知识,并将其应用或迁移到另一个独立的任务中,这就是迁移学习。神经风格迁移算法是在预训练好的模型上完成的,本文使用的是VGG-19网络结构,是一个已经训练好的图像分类网络,已经能够很好的识别图像的低级特征和高级特征。
代价函数
定义代价函数![]() 可以用来评定生成图片的好坏。代价函数由两部分组成,一个是内容代价函数
可以用来评定生成图片的好坏。代价函数由两部分组成,一个是内容代价函数![]() ,用于衡量生成图片和原始图片的相似程度,另一个是风格代价函数
,用于衡量生成图片和原始图片的相似程度,另一个是风格代价函数![]() ,用于衡量生成图片的风格和风格图片的风格相似程度,使用超参数来确定内容代价和风格代价的权重,代价函数的公式如下:
,用于衡量生成图片的风格和风格图片的风格相似程度,使用超参数来确定内容代价和风格代价的权重,代价函数的公式如下:
![]()
神经风格迁移算法的步骤:
-
随机初始化特定尺寸的生成图像G
-
使用梯度下降算法最小化
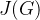 ,以找到最合适的图像G
,以找到最合适的图像G -
更新图像G:
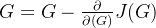
内容代价函数
确定一个隐层 ,使用预训练好的卷积神经网络,分别输入内容图像和生成图像,得到两个第隐层的激活块,然后使用L2范数的平方计算两个激活块中对应项的距离并求和。对使用梯度下降法时,会激励这个算法找到合适的图像G,使得图像G在第层的激活值和内容图像相似。
,使用预训练好的卷积神经网络,分别输入内容图像和生成图像,得到两个第隐层的激活块,然后使用L2范数的平方计算两个激活块中对应项的距离并求和。对使用梯度下降法时,会激励这个算法找到合适的图像G,使得图像G在第层的激活值和内容图像相似。
风格代价函数
图片风格定义为:第层各通道间激活项的相关系数,而相关系数是用于测量不同特征在图片中各位置同时出现或不同时出现的概率。用相关系数描述激活块中不同通道的风格。

如何计算图像各通道的相关系数?
- 取第隐层的激活矩阵,有如下定义:
![a_{i,j,k}^{[l]}](http://img.e-com-net.com/image/info8/883e3cc614254e678a5568cba69fddb1.png) 表示第
表示第 个通道的
个通道的 激活项,
激活项,![G^{[l]}](http://img.e-com-net.com/image/info8/75c49f470e5446fdbdb4cb6300d4d69f.png) 是
是![n_c^{[l]} * n_c^{[l]}](http://img.e-com-net.com/image/info8/5c1be7e5d433455788752cedeb53ab77.png) 大小的风格矩阵
大小的风格矩阵 - 求风格图像的风格矩阵:
![G_{kk^\prime}^{(S)} = \sum_{i=1}^{n_H^{[l]}}\sum_{j=1}^{n_W^{[l]}}a_{i,j,k}^{(S)}a_{i,j,k^{\prime}}^{(S)}](http://img.e-com-net.com/image/info8/0820ea99f08c40f59ea1e7b18ae65ec8.png)
- 求生成图像的风格矩阵:
![G_{kk^\prime}^{(G)} = \sum_{i=1}^{n_H^{[l]}}\sum_{j=1}^{n_W^{[l]}}a_{i,j,k}^{(G)}a_{i,j,k^{\prime}}^{(G)}](http://img.e-com-net.com/image/info8/3e67d5f57d9f4ce78209ccfd20ce6aa4.png)
风格代价函数,使用L2范数的平方计算两个风格矩阵对应项的距离,系数是多少影响不大:
![]()

代码实现
请先导入一下模块或函数:
from keras.models import Model
from keras.applications import VGG19
from keras.preprocessing import image
from keras.optimizers import Adam
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
import time确定内容输出和风格输出的中间层
首先导入VGG-19网络:
from keras.applications import VGG19
vgg = VGG19(include_top=False)查看网络所有层的名字
for layer in vgg.layers:
print(layer.name)
输出内容:
input_2
block1_conv1
block1_conv2
block1_pool
block2_conv1
block2_conv2
block2_pool
block3_conv1
block3_conv2
block3_conv3
block3_conv4
block3_pool
block4_conv1
block4_conv2
block4_conv3
block4_conv4
block4_pool
block5_conv1
block5_conv2
block5_conv3
block5_conv4
block5_pool选择网络某些中间层作为内容输出和风格输出
content_layers = ['block5_conv2'] # 被选择作为内容输出的中间层
style_layers = ['block1_conv1',
'block2_conv1',
'block3_conv1',
'block4_conv1',
'block5_conv1'] # 被选择为风格输出的中间层构建模型
创建VGG19模型,返回以中间层作为输出的模型
def vgg_layers(layer_names):
'''
创建VGG19模型,返回以中间层作为输出的模型
:param layer_names: 层名字列表
:return:
'''
vgg = VGG19(include_top=False)
# 中间层的输出结构列表
outputs = [vgg.get_layer(name).output for name in layer_names]
model = Model([vgg.input], outputs)
return model提取内容和特征
先定义一个函数,用于求特征矩阵的风格矩阵:
def gram_matrix(input):
'''
:param input: 特征矩阵
:return: 返回风格矩阵
'''
result = tf.linalg.einsum("bijc,bijd -> bcd", input, input)
return result构建内容和风格提取模型,调用该模型的实例,可以返回图像在VGG19网络中间层的风格矩阵和特征矩阵:
class StyleContentModel(Model):
def __init__(self, style_layers, content_layers):
'''
:param style_layers: 被选择的中间层,作为风格图像输出
:param content_layers: 被选择的中间层,作为内容图像的输出
'''
super(StyleContentModel, self).__init__()
self.vgg = vgg_layers(style_layers + content_layers) # 这样模型的输出成为包含所有被选择的中间层输出的列表。
self.style_layers = style_layers
self.content_layers = content_layers
self.num_style_layers = len(style_layers)
def call(self, inputs):
'''
在类实例被调用时,该函数会执行
:param inputs: 输入模型的图像数据
:return: 返回字典,包含图像内容输出的列表和风格输出的列表
'''
# 输入图像给模型,得到被选择的中间层输出
outputs = self.vgg(inputs)
# 分割输出值,得到风格输出值和内容输出值
style_outputs, content_outputs = outputs[:self.num_style_layers], outputs[self.num_style_layers:]
# 根据风格输出值计算其风格矩阵
style_outputs = [gram_matrix(output) for output in style_outputs]
# 对于内容输出,将层的名字及其对应的输出封装成字典
content_dict = {content_name: value for (content_name, value) in zip(self.content_layers, content_outputs)}
# 对于风格输出,将层的名字及其对应的输出封装成字典
style_dict = {style_name: value for (style_name, value) in zip(self.style_layers, style_outputs)}
return {"style": style_dict, "content": content_dict}
计算总代价
计算总代价包括计算内容代价和风格代价:
def style_content_loss(outputs, style_target, content_target, style_weight, content_weight):
style_outputs = outputs["style"]
content_outputs = outputs["content"]
# 计算风格损失
style_loss = tf.add_n(tf.reduce_mean(tf.square(style_outputs[name] - style_target[name])) * style_weight / (4 * style_outputs[name].shape[1] * style_outputs[name].shape[2]) for name in style_layers)
style_loss = style_loss / len(style_layers)
# 计算内容损失
content_loss = tf.add_n(tf.reduce_mean(tf.square(content_outputs[name] - content_target[name])) * content_weight / (4 * content_outputs[name].shape[1] * content_outputs[name].shape[2] * content_outputs[name].shape[3]) for name in content_layers)
content_loss = content_loss / len(content_layers)
# 计算总体损失
loss = style_loss + content_loss
return loss使用优化算法寻找最优图像G
定义模型,并获取内容图像的输出值和风格图像的风格矩阵:
# 定义模型
model = StyleContentModel(style_layers, content_layers)
# 获取内容图像的内容输出和风格图像的风格输出
content_target = model(content)["content"]
style_target = model(style)["style"]初始化生成图像,尺寸要和原图像一致:
# 初始化生成图像,尺寸和原图像要一致
generate = tf.Variable(content)前向传播计算输出值,反向传播计算梯度值:
# 进行epochs次训练
for epoch in range(epochs):
with tf.GradientTape() as tape:
outputs = model(generate)
loss = style_content_loss(outputs, style_target, content_target, style_weight, content_weight)
print("第{}代, 损失值为:{}".format(str(epoch), str(loss)))
# 定义Adam优化算法
optimizer = Adam(learning_rate, beta1, beta2, epsilon)
# 使用优化算法最小化成本函数,以找到最优生成图像G
grad = tape.gradient(loss, generate)
optimizer.apply_gradients([(grad, generate)])
# 限制图像的像素值在[0,1]
generate.assign(tf.clip_by_value(generate, clip_value_min=0.0, clip_value_max=1.0))将上诉操作封装成一个函数,方便同时执行:
def model(content, style, style_weight=1e-2, content_weight=1e4, learning_rate=0.05, beta1=0.9, beta2=0.999, epsilon=1e-8, epochs=10):
'''
:param content: 内容图像
:param style: 风格图像
:param style_weight: 风格损失函数权重
:param content_weight: 内容损失函数权重
:param learning_rate: 学习率
:param beta1: 梯度的加权平均
:param beta2: 梯度的平方加权平均
:param epsilon: 防止除0而加上的参数
:param epochs: 迭代次数
:return: 返回生成图像 generate
'''
# 定义模型
model = StyleContentModel(style_layers, content_layers)
# 获取内容图像的内容输出和风格图像的风格输出
content_target = model(content)["content"]
style_target = model(style)["style"]
# 初始化生成图像,尺寸和原图像要一致
generate = tf.Variable(content)
# 进行epochs次训练
for epoch in range(epochs):
with tf.GradientTape() as tape:
outputs = model(generate)
loss = style_content_loss(outputs, style_target, content_target, style_weight, content_weight)
print("第{}代, 损失值为:{}".format(str(epoch), str(loss)))
# 定义Adam优化算法
optimizer = Adam(learning_rate, beta1, beta2, epsilon)
# 使用优化算法最小化成本函数,以找到最优生成图像G
grad = tape.gradient(loss, generate)
optimizer.apply_gradients([(grad, generate)])
# 限制图像的像素值在[0,1]
generate.assign(tf.clip_by_value(generate, clip_value_min=0.0, clip_value_max=1.0))
return generate实现效果
实现效果如下图所示,从左至右分别是内容图像、风格图像和生成图片:

参考:
- 【中英】【吴恩达课后编程作业】Course 4 -卷积神经网络 - 第四周作业_hsck.cc_何宽的博客-CSDN博客
- 神经风格迁移 | TensorFlow Core