全链路压测引发的惨案-流量回放的实践(一)
作者:CRDE
笔记中的每一个篇都有建立在此前篇章的基础上,建议按照顺序阅读。
在这里记录下系列文章地址:
全链路压测引发的惨案-流量回放的实践(一)
(本文)
流量回放框架jvm-sandbox-repeater的实践【入门使用篇】1 repeater安装于启动(初尝repeater-console)
一. 邂逅JVM-Sandbox-Repeater(起因)
数字时代的来临,一个企业的生产力不仅取决于勤奋负责的员工和出色高效的设备,安全稳定的网络基础设施也是必不可少的重要环节。研发过程中,如果没有一个安全稳定的网络基础设施,不光用户体验大打折扣,同时也会出现严重的数据信息安全问题。面对着多种突发故障出现的可能性,橙色云秉承着以客户为中心,用心创造价值的核心价值观,对服务系统都进行了一次较全面的“体检”。此次体检,我们通过一系列的技术手段,保障橙色云多个业务服务系统的稳定性,优化用户体验,为设计师们提供更加舒适的工作环境。
早期,主要的压测方式是线上环境的单机或集群发起服务调用。
1. 线上环境的单机或集群发起服务调用;
2. 线上流量录制,在单台机器上进行回放;
3. 修改权重的方式进行引流压测;
全链路压测是基于线上真实环境和实际业务场景,通过模拟海量的用户请求,来对整个系统进行压力测试。
1. 提供模拟线上真实流量的能力;
2. 具备快速创建压测环境的能力;
3. 支持多种压测类型;
4. 提供压测过程的实时监控与过载保护。
全链路压测是一个需要实时关注服务状态的过程,尤其在探测极限的时候,需要具备精准调控 QPS 的能力,秒级监控的能力,预设熔断降级的能力,以及快速定位问题的能力。
苦恼
1. 如何能准确的获取线上流量数据;
2. 如何能针对特定的业务流程产生的数据进行录制;
3. 如何实现特定场景的数据回放;
4. 如何保证对现有程序的无侵入性;
是否也在被类似的问题困扰,是否也遇到过其他问题?
1. 服务重构,大量接口需要回归;
2. 每次迭代,耗费精力进行回归测试;
3. 线上Bug,线下复现不了;
4. 接口自动化测试用例维护工作量大。
推荐
很多企业在尝试一些流量回放工具来解决上述问题时,常常会遇到这样一个情形:从入门到放弃的无奈。现有大部分流量回放工具中都存在着这样或那样的限制,比如,单纯支持GET接口、不能对子调用进行Mock、对环境和数据依赖度高等情况,所以往往会出现在线上录制时心惊胆跳,线下回放时坎坷不断的使用感受。回归的接口少,使用流量回放还不如手动测试快;回归的接口多,使用体验直线下降。
现推荐一款简单易用、安全可靠的流量录制回放工具JVM-Sandbox-Repeater。

二. 初识JVM-Sandbox-Repeater(简介)
JVM-Sandbox-Repeater是阿里在2019年7月份的时候开源的流量录制回放工具。
GitHub:https://github.com/alibaba/jvm-sandbox-repeater。
JVM-Sandbox-Repeater框架基于JVM-Sandbox,具备了JVM-Sandbox的所有特点封装了以下能力:
1. 录制/回放基础协议,可快速配置/编码实现一类中间件的录制/回放;
2. 开放数据上报,对于录制结果可上报到自己的服务端,进行监控、回归、问题排查等上层平台搭建。
基于它我们可以在业务系统无感知的情况下,快速扩展Api,实现自己的插件,对流量进行录制,入口请求(HTTP/Dubbo/Java)流量回放、子调用(Java/Dubbo)返回值Mock能力。
详细介绍可看官方说明。
三. 探知JVM-Sandbox-Repeater(原理)
主要原理
录制
当repeater启动对service A的录制后,有请求到service A,sandbox感知到请求后通知repeater。repeater对事件进行给过滤和采样计算,对满足录制条件的请求会记录请求、响应、子调用和响应,序列化成后通知repeater-console进行处理和保存。
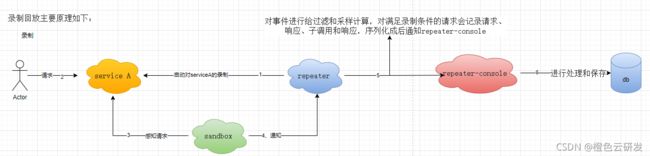
步骤解析:
1. 把repeater注入到service A中,用于监测service A,从而进行对service 的录制回放实现。
2. 用户对service A发起请求
3. sandbox感知到对service A发起的请求
4. sandbox感知请求后通知repeater
5. repeater对事件进行过滤和采样计算,对满足录制条件的请求会记录请求、响应、子调用和响应,序列化成后通知repeater-console
6. repeater-console把需要录制的请求、响应以及子调用序列话后的结果进行数据库存储。
回放
用户请求repeater-console的回放接口,明确需要回放哪条录制数据。然后repeater-console通过调用repeater提供的回放任务接收接口下发回放任务。repeater在执行回放任务的过程中,会反序列化记录的wrapperRecord,根据信息构造相同的请求,对被挂载的任务进行请求,并跟踪回放请求的处理流程,以便记录回放结果以及执行mock动作。如图,当我们启用了redis插件,录制时,service A到reids等的子请求方法、参数、响应将被录制下来,回放时,当service A再对reids发起请求时,repeater会先判断是否需要mock,当需要mock时会根据回放上下文中的信息拼接
出MockRequest,通过mock策略计算获取MockResponse。目前源码中是获取相似度100%的请求的响应来进行mock。回放结束,repeater会将回放信息和结果序列化后通知repeater-console进行处理和保存。
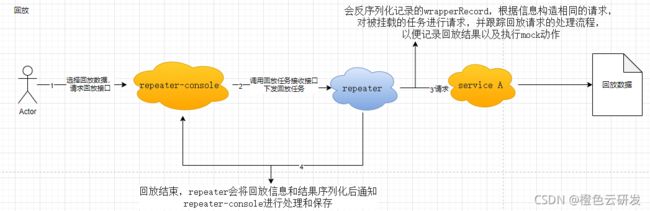
步骤解析:
1.用户请求repeater-console的回放接口,明确需要回放哪条录制数据。
2. repeater-console调用repeater提供的回放任务接收接口,并进行下发回放任务。
3. repeater在执行回放任务的过程中,会反序列化记录的wrapperRecord,根据信息构造相同的请求,对被挂载的任务进行请求,并跟踪回放请求的处理流程,以便记录回放结果以及执行mock动作。
4. 回放结束,repeater会将回放信息和结果序列化后通知repeater-console进行处理和数据保存。
四. 启程JVM-Sandbox-Repeater(实践)
完成上述改造,基本上流量回放就可以简单使用起来了。下面记录一次录制回访的过程。
1)在目标服务器上运行./sandbox.sh -p {PID} -P 12580启动录制,看日志见插件加载成功,服务开始录制

2)录制情况

3)回放情况

4)资源占用情况
在服务器上的录制。启动repeater开始录制,约占用80M的内存。另外短时间也会有较大的cpu开销,因为需要遍历所有加载的类以及类增强。而和console交互也会占用部分网速,可能影响响应时长。所以线上录制时,务必预留好资源。
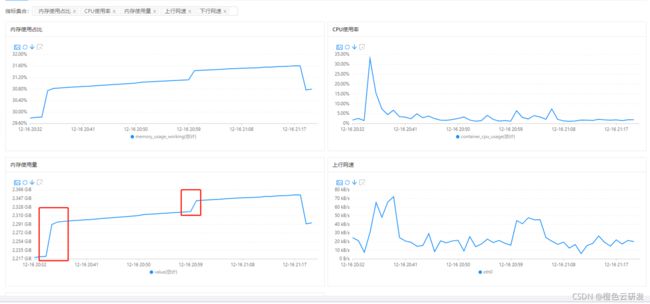
回放时,一般建议在线下回放。批量回放对cpu资源占用较高,这个后续优化。

五. 感恩JVM-Sandbox-Repeater(推荐)
JVM-Sandbox-Repeater是一款便捷好用的流量回放工具。
无侵入、热插拔
直接作用在JVM层,它的通用性和可扩展性都不错。
已支持插件
| 插件类型 | 录制 | 回放 | Mock | 支持时间 | 贡献者 |
|---|---|---|---|---|---|
| http-plugin | √ | √ | × | 201906 | zhaoyb1990 |
| dubbo-plugin | √ | × | √ | 201906 | zhaoyb1990 |
| ibatis-plugin | √ | × | √ | 201906 | zhaoyb1990 |
| mybatis-plugin | √ | × | √ | 201906 | ztbsuper |
| java-plugin | √ | √ | √ | 201906 | zhaoyb1990 |
| redis-plugin | √ | × | √ | 201910 | ElesG |
| hibernate | √ | × | √ | 201910 | zhaoyb1990 |
| spring-data-jpa | √ | × | √ | 201910 | zhaoyb1990 |
平台化
支持平台操作配置变更、录制、回放、结果查看、历史记录查看等。
最后感谢阿里开源了这一个强大的流量回放工具。水平有限,欢迎指正。
关注我们
本文转载自: 流量回放框架jvm-sandbox-repeater的实践, 感谢原作者的无私分享。