Multi-view Depth Estimation using Epipolar Spatio-Temporal Networks
Multi-view Depth Estimation using Epipolar Spatio-Temporal Networks
尽管之前的一些方法得出了比较好的结果,但是大部分方法单独估计一个帧的深度,没有考虑到帧之间的时间连续性。
使用全3D卷积实现cost regularization需要大量的计算。
我们的方法得到了时间连续的深度估计结果,通过使用一种新的Epipolar Spatio-Temporal (EST) transformer,明确多视角深度估计的几何联系和时间相关性。
为了减少计算,参考最近的Mixture-of-Experts model,我们设计了一个紧凑的混合网络,由2D上下文感知网络和3D匹配网络组成,分别学习2D上下文信息和3D视差线索。

输入是5个连续的帧,输出是中间3个帧的深度图。Epipolar Spatio-Temporal (EST) transformer用于所有得到的混合volumes来联系他们的时间相关性,然后得到初始的深度图。
网络共分为四个部分:
1. Hybrid cost volume generation
(1)Matching volume generation:
feature extraction : SPP模块,32通道,下采样为原始图像的1/4
raw matching volume : 通过将source image特征图反投影到坐标系生成,这些坐标系是reference image在一系列前向平行的虚拟平面定义的,这些平面根据数据集深度范围均匀分布,取平面数D=64。reference特征图和source特征图在某一深度(64个中取一个)之间坐标存映射,根据这个映射,将source特征图warp到所有的虚拟平面,得到feature volume,维度C x D x H x W。然后在每个虚拟平面与reference特征图连接起来,生成2C x D x H x W的raw matching volume。通过连接操作,网络可以接收必要的信息,以便在reference特征和source特征之间执行特征匹配,而无需抽取特征维度。
MatchNet:3个3d卷积通道数降为c,然后平均池化,再一系列3d卷积正则化。只学习局部特征。
(2)Context volume generation:
ContextNet:使用的是ResNet-50,提取全局上下文信息。生成的是D x H x W,扩展到1 x D x H x W,与上面的regularized matching volume连接,得到 hybrid cost volume Ct: (1+C) x D x H x W,分别做三次,得到三个Ct-1,Ct,Ct+1。
Fuse:简单拼接。
2. Epipolar Spatio-Temporal transformer
一致性约束:空间中一点,在不同图片上投影,附近的背景应该高度相似。
混合cost volume被视为不同视点下相同3D世界空间的多个占用度量,即,对于世界空间中的3D点,体积Ct-1、Ct、Ct+1的相应体素应保持相似的嵌入向量。
Epipolar warping:
如图,将混合volume转换到同一相机坐标系,将Ct-1和Ct+1 warp到和Ct相同的坐标系中,相当于相机在两个不同位置拍摄,转换到同一相机坐标系中。
这里的warp和第一步中匹配volume生成都需要用到公式1.。平面扫描法。

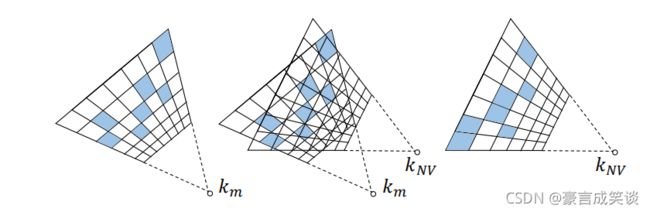

EST transformer :query volume :Ct memory volume :Ct-1,Ct+1
首先将query和memory分别送入两个相同的卷积层,下降通道数为C/2,分别得到两个value和key,memory keys和memory values分别warp到Ct的坐标系中,这样我们就可以通过key计算query 和 memory之间的相似性,(query key和memory key之间的相似性被计算出来,来决定那里检索memory value),生成correlation volume,经过soft max,得到attention volume。表示的是memory volume与query volume的相似性。然后warped values检索的值与query value融合(adaptive),得到最终的输出。
F融合:
使用了两种融合方式,一种是直接连接,另一种是adaptive,表现更好,如下面函数,得到可能性volume

Refine Net:得到初始深度,由于下采样四倍导致细粒度和边界特征丢失,使用2阶段RefineNet上采样initial depth maps,生成1/2和原大小的深度图。
depth regression:
我们从没有经过Transformer的hybrid cost volume中提取深度图,然后算上initial depth,2阶段RefineNet得到的2个深度图,一共是4个,通过如下公式计算loss ,λ = 0.8
这样算的话是越早得到的,不精确的深度图所占损失系数越大。

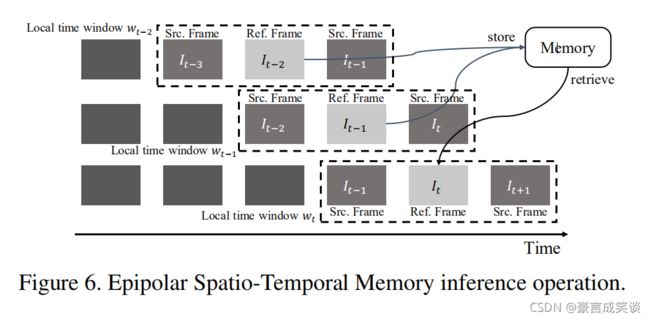
为了有效利用时间相关性,我们使用滑动窗口的形式,通过EST transformer,我们可以得到过去帧的相关性信息,保存到Memory中,然后就可以利用过去有用的信息,估计现在帧的深度,这个Memory是随着时间更新的。
其实就是把上面EST估计中两个前后的memory volume换成了N个之前的memory volume。
In the training stage, our model takes a short video sequence with 5 frames as input and jointly estimate the depth maps of three target images with short-term temporal coherence. To propagate long-term temporal coherence through the whole video, we propose an Epipolar Spatio-Temporal Memory (ESTM) inference operation. As depicted in Figure 6, we hold a sliding window containing one reference image and two source images to estimate the depth map of the current frame It. Using the EST transformer, we retrieve relevant values from a memory space storing the pairs of keys and values of N past frames, thus useful information at different space-time locations can be utilized for estimating the depth map of the current frame. When the sliding window moves on, the memory space will be also updated accordingly, by which operation the long-term temporal coherence is propagated through the whole video.
Datasets
训练用ScanNet dataset, The whole dataset consists of more than 1600 indoor scenes, which provides color images, ground truth depth maps and camera poses.
测试在7scenes and SUN3D 数据集实现跨数据集评估,同时与以前方法不同,使用视频而不是两个图像。
评价指标

Feature-Level Collaboration: Joint Unsupervised Learning of Optical Flow, Stereo Depth and Camera Motion
光流、立体深度和摄像机运动的精确估计对于真实世界的3D场景理解和视觉感知非常重要。在本文中,我们表明,与仅损失级联合优化相比,针对三个任务的网络的有效特征级协作可以在所有三个任务中实现更大的性能改进。
具体来说,我们提出了一个单一的网络来组合和改进这三项任务。该网络提取两幅连续立体图像的特征,同时估计光流、立体深度和摄像机运动。

The green box 1 presents our Feature-sharing encoder (Sec. 3.1), Pooled decoder module(Sec. 3.2) and Camera pose estimation module(Sec. 3.3).
The brown box 2 illustrates Cost volume complement(Sec. 3.4), which uses the C′d instead of Cd as the input of the decoder, where C′d is the combination of original Cd and Cf d whose construction process is shown in Fig. 2 in detail.
整个网络结构包括四个部分: 1) feature-sharing encoder, 2) pooled optical flow and disparity decoder, 3) camera pose estimation,
4) cost volume complement.
网络输入:左右两边分别在t和t+1时刻的图片。
根据输入得到光流,视差和相机移动
Feature-sharing encoder:
PWC-Net作为特征提取器,提取5种尺度特征金字塔,这些特征之后被整合起来为接下来的光流和立体深度估计。进一步用于预测相机运动。共享权重减少了参数量。
PWC-Net:
Deqing Sun, Xiaodong Yang, Ming-Yu Liu, and Jan Kautz. Pwc-net: Cnns for optical flow using pyramid, warping, and cost volume. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 8934–8943, 2018
Pooled optical flow and disparity decoder:
我们在原始的PWC-Net的解码做了两个修改:1):输入两个cost volume而不是一个。以第l层decoder为例,一个cost volume由左边两个图片第l层特征和光流上采样组成,另一个由t时刻的两个图的第l层特征和深度上采样组成。2):把解码端输出的通道数由2增加到3。同时解码光流和视差。前两个通道用于光流最后一个用于视差。
这是因为光流图需要两个通道表示,而深度图只需要一个通道表示。
Camera pose estimation:
两个子模块:camera pose prediction module and refinement module.
camera pose prediction:估计2帧间相机位姿变换。输入是:2nd-level flow and disparity, the 2nd-level image features, and the fused features of the pooled decoder in 2nd-level。输出是:6-DOF camera pose Camera pose refinement module:
与以往基于学习的方法[54,4,30,45]直接从原始图像回归相机姿态相比,我们的方法利用了光流和深度的feature-level信息,可以实现更好的相机运动估计。
Camera pose refinement module:
估计的相机姿态和真实值之间有一定的偏差,我们可以看做是轻微的扰动∆ξt→s。我们细化的目标是找到这个偏差,就像【45】中提出的RDVO一样。
【45】 Yang Wang, Peng Wang, Zhenheng Yang, Chenxu Luo, Yi Yang, and Wei Xu. Unos: Unified unsupervised optical-flow and stereo-depth estimation by watching videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 8071–8081, 2019. 1, 3, 4, 5, 6, 7, 8
深度和视差之间的关系。

目前还不懂这个公式

如【45】我们通过光流一致性检查得到静态区域,然后根据前后传播一致性检验得到非遮挡区域,静态非遮挡区域就是静态和非遮挡区域。

[33] Simon Meister, Junhwa Hur, and Stefan Roth. Unflow: Un-supervised learning of optical flow with a bidirectional census loss. arXiv preprint arXiv:1711.07837, 2017. 2, 4, 5, 6
我们的基本假设是,在非遮挡区域估计的光流和立体深度足够精确。所以∆ξt→s可以通过最小化在静态非遮挡区域中随机选择的N个像素的重投影误差来计算,

Cost volume complement
现有的联合方法通常侧重于优化损失,而不是降低cost volume。
基于共享特征,我们提出了一个cost volume complement module,更深利用图像特征,来加强光流和视差cost volume。
This module mainly contains four parts: cost volume enhancement, cost volume interaction, iterative optimization and moving objects handling.
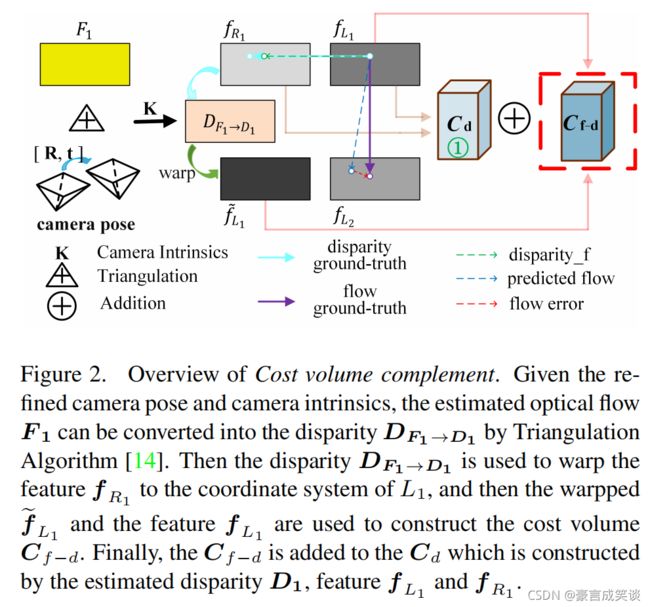
Cost volume enhancement:如图2所示,给定摄像机姿势ξL1→L2和光流F1,我们构建了cost volume Cf-d。在大多数真实数据集中,大多数遮挡像素在L2中不可见,但在R1中可见。因此,Cf-d是Cf的一个强大增强。
我们要得到Cf,是用了L1和L2的关系,但是由于遮挡,L1的像素在L2中不一定可见,但是呢在R1中可见,我们如果知道相机位姿和参数,光流就可以转换为深度,我们在上面已经得到了精细化之后的相机位姿,我们要求的是光流Cf,我们之前已经估计得到了光流,光流和深度(视差)可以转换,根据视差我们可以将R1 warp到L1
Cost volume interaction:如图1所示,我们将Cd和Cf-d组合得到C′d。由于估计的视差比光流更精确,尤其是在遮挡区域,因此Cf-d和Cd的组合将进一步提高光流估计性能。
Iterative optimization:为了实现cost volume component,第二级pooled decoder已经进行了三次迭代,权重相同,但输入和损失不同。首先,输入原始Cd和Cf以估计光流和视差,摄像机姿态估计模型在第一次迭代中只训练一次。经过第一次迭代,我们得到了初始光流、深度和相机的姿态。其次,输入C′d和Cf,仅用静态mask约束静态区域。第二次迭代后,我们在静态区域获得了更精确的光流。第三,输入C′d和Cf,用光度(photometric)损失约束非遮挡区域,用光流一致性(flow consistency)损失约束静态遮挡区域,在第三次迭代中,我们进一步细化了光流和视差。如图1所示。
Moving objects handling:在理论上,我们的cost volume complement module还可以通过使用不同移动对象的姿势(而不是相机姿势)应用于移动对象。但由于很难估计运动物体的精确姿态,因此,我们在此介绍一种处理运动物体的新方法。我们从原始输入图像中提取特征,并复制第二级pooled decoder来预测动态对象的光流和视差。为此,仅为该小型模块的训练提供了亮度一致性约束。该过程与第一次迭代类似。
Training losses
Photometric losses:

第一项是光度损失,第二项是相似性损失,第三项是census损失。V表示的是非遮挡区域mask,对于光流,根据前后传播一致性得到[16]。
[16] Junhwa Hur and Stefan Roth. Mirrorflow: Exploiting symmetries in joint optical flow and occlusion estimation. In Proceedings of the IEEE International Conference on Computer Vision, pages 312–321, 2017. 6
Edge-aware smoothness:
We use similar image gradient based edge-aware smooth loss L∗s(O) like [30].
Camera pose loss:

rigid flow (computed from estimated disparity and camera motion)


[45] Yang Wang, Peng Wang, Zhenheng Yang, Chenxu Luo, Yi Yang, and Wei Xu. Unos: Unified unsupervised optical-flow and stereo-depth estimation by watching videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 8071–8081, 2019. 1, 3, 4, 5, 6, 7, 8