YOLOv8环境安装、数据集划分、训练、测试、推理
首先在电脑上安装好Anaconda以及Pycham软件。并配置好了基础的pytorch环境。
1、安装教程
首先进入自己的虚拟环境,如果之前有安装过ultralytics库的话,请先pip uninstall ultralytics,卸载好之后在执行一次相同的命令(pip uninstall ultralytics)。
如果出现WARNING: Skipping ultralytics as it is not installed.证明已经卸载干净.
执行 python setup.py develop命令之后如果没报错就证明安装完成。
2、数据集划分
YOLOv8和YOLOv5的数据集是一样的。
2.1数据集格式转换(XML转TXT,就是VOC转YOLO)
现在我们需要两个文件夹分别存放标注文件(Annotations)与原始图片文件(JPEGImages),两个文件夹内文件名互相对应(标注和图像的名字对应)

再新建一个txt文件夹用于存放将Annotations中的.xml文件转换成.txt格式后的文件。
 运行xml2txt.py,特别注意几个文件夹的相对位置不要搞错,这样才能成功。且图片文件夹JPEGImages中的图片类型必须全部一致,不能混杂,并用postfix = 'jpg'指定你的数据中的图像文件后缀。
运行xml2txt.py,特别注意几个文件夹的相对位置不要搞错,这样才能成功。且图片文件夹JPEGImages中的图片类型必须全部一致,不能混杂,并用postfix = 'jpg'指定你的数据中的图像文件后缀。

运行完成之后所得到的文件夹结果如下图所示。

2.2数据集按照比例划分

val_size = 0.1,test_val = 0.2,分别表示验证集以及测试集的比例.
训练集的比例就自动设置成1-0.1-0.2 = 0.7.
postfix = ‘jpg’ 格式就是图像源的格式
根据上面代码,我们可以看到创建了两个文件夹分别是images(存放图像数据)、labels(存放标签数据),里面包含三个子文件夹分别存放的是训练集验证集以及测试集的图像以及标签数据。
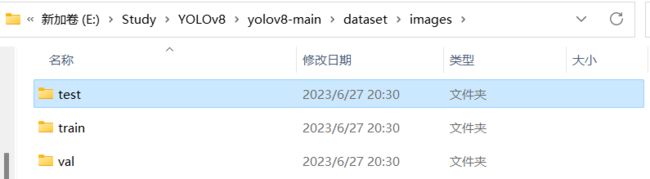

这样我们的数据就处理好了,可以准备下一步训练了。
3、训练、测试、推理
3.1train.py参数解读
首先打开train.py查看参数。

--yaml
--yaml 模型的配置文件:可以看到输入的是yolov8n.yaml,实际上该项目目录下是没有该yaml配置文件的,只有一个yolov8.yaml,该文件默认是yolov8n,如果我们想要使用yolov8x配置文件的话,我们只需要输入yolov8x.yaml即可,尽管文件夹中没有这个对应名字的配置模型文件。
![]()
YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
--weight
预训练模型,主要有yolos,yolon,yolol,yolox...
加快模型训练速度,提升训练效果等。
--cfg
超参数的配置文件
--data
coco128.yaml为例,这里面主要设置训练集、验证集、测试集的路径,以及种类名字信息等。


--epochs(训练轮次)
--patience
在epoches增加但是训练效果没有替身时是否决定要提前结束训练。(不想提前结束的话就和epochs的值设置成一样)
--unamp(是否开启混合精度训练)
--batch(一次送入训练网络的图像张数,根据电脑显存决定)
--project
训练结果的保存路径
![]()
--name
保存路径中保存的结果名字命名是什么
![]()
--resume(断点续训)
--optimizer(优化器选择)
主要的类型有:'SGD', 'Adam', 'Adamax', 'NAdam', 'RAdam', 'AdamW', 'RMSProp', 'auto'。
--close_mosaic
关闭mosaic数据增强。设置值10表示最后十个epochs在训练的时候关闭mosaic可能会帮助提高训练效果。因为mosaic图片本来就是远离真实图片的分布。
--info(模型可视化输出)
3.2val.py参数解读
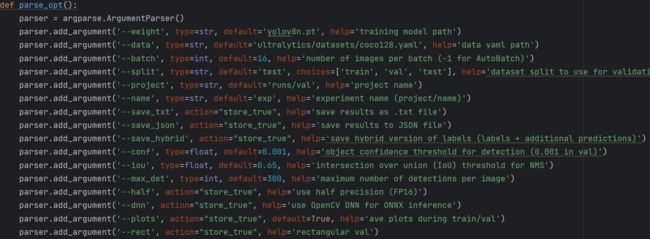
--split(分割数据集用于验证)
--save_json(保存结果到json文件)
--save_hybrid(保存标签的混合版本)
--conf(用于检测的对象置信阈值,一般在验证中就设置0.001不变化,一般不改变)
--iou(NMS的感兴趣区域阈值)
--max_det(一张图片最多检测目标个数)
3.3detect.py参数解读

--source
待检测的图片或者视频文件路径
--show
直接弹出检测结果
--vid_strid
视频文件每隔几帧做一次检测,加快预测速度
--line_width
调整线宽
3.4常用命令
查看yolov8l的网络结构
python train.py --yaml ultralytics/models/v8/yolov8l.yaml --infopython train.py --yaml ultralytics/models/v8/yolov8-bifpn.yaml --info![]()
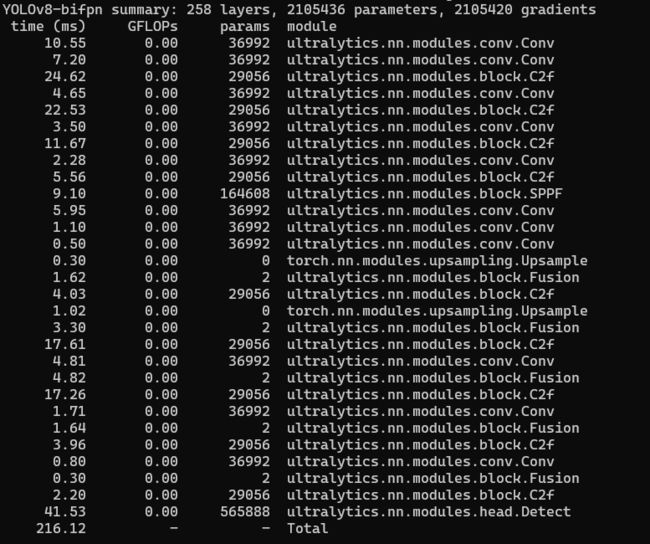
3.4训练
训练时我们打开终端进入虚拟环境以及项目文件夹路径下。
输入命令
python train.py --weight yolov8n.pt --yaml ultralytics/models/v8/yolov8n.yaml --data /home/Desktop/dataset/dataset_person/data.yaml --workers 8 --batch 32训练时我们要创建自己的yaml文件并传入,形式可以参考coco128.yaml

--fraction
设置成0.1,表示只使用数据集中百分之10进行训练。设置成1则表示使用全部数据集。
3.5验证
python val.py --weight runs/train/exp3/weights/best.pt --data /home/Desktop/dataset/dataset_person/data.yaml --split test
python val.py --weight runs/train/exp4/weights/best.pt --data /home/Desktop/dataset/dataset_person/data.yaml --split test --save_txt3.6检测推理
python detect.py --weight yolov8n.pt --source ultralytics/assets/zidane.jpg --conf 0.25python detect.py --weight runs/train/exp4/weights/best.pt --source video.mp4 --conf 0.25
