7、(复现)--智慧交通,deepsort车辆追踪统计 + yolov5识别模型训练,
开发目标:《基于yolov5检测器的,deepsort车辆目标追踪》
# 注意: 531.29的cuda驱动有问题,不断地黑屏,最好更新驱动为 531.79的驱动!!!
关键词: yolov5车辆检测器、deepsort车辆追踪器、匈牙利算法匹配合并轨迹、卡尔曼滤波(传感器与预测轨迹的权重拟合)
关键词: yolov5车辆检测器、deepsort目标最终、匈牙利算法最小等价矩阵、卡尔曼滤波(传感器与预测轨迹的权重拟合)、逆透视距离和速度估算、多目标跟踪、pytorch框架
多目标追踪 MOT: multiple object tracking ,加强版的目标检测==目标检测+目标 id
MOT 的主要步骤: 1、输入多帧视频、 2、检测:如yolo的目标检测器、faster-rcnn 3、特征提取:物体特征提取,表观特征、运动特征等
4、相似度计算:计算前后两帧的相似度、 5、关联阶段:为每一个目标,分配关联对应的ID。
本次使用的是: deepsort算法
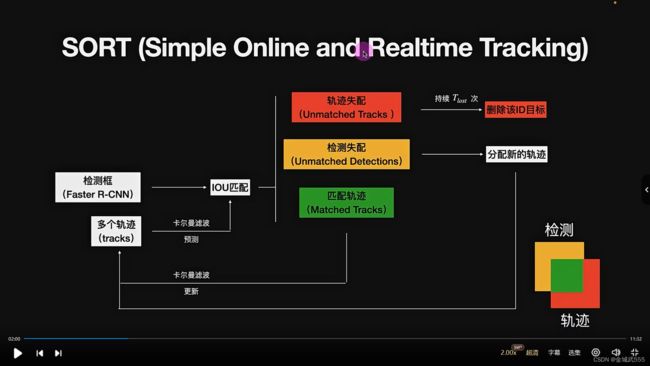
sort算法: simple online and realtime tracking(简单的,在线实时跟踪算法)
检测框 + 传感器,进行 iou匹配!!!
三种匹配情况: 1、轨迹失配:lost次后删除id目标(消失) 2、检测失配:卡尔曼滤波,分配新的轨迹(刚出场的角色,就给分配id,或是检测器,它没跟上,就再检测下)
3、轨迹匹配: 更新卡尔曼滤波,传感器对象
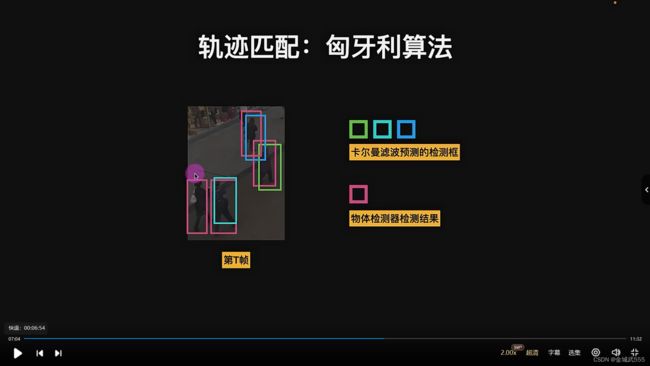
轨迹匹配: 使用《匈牙利算法》,确认mn之间的关系,谁是谁的问题,解决传感器框和检测器框,之间的匹配问题,每个人他们的框的问题
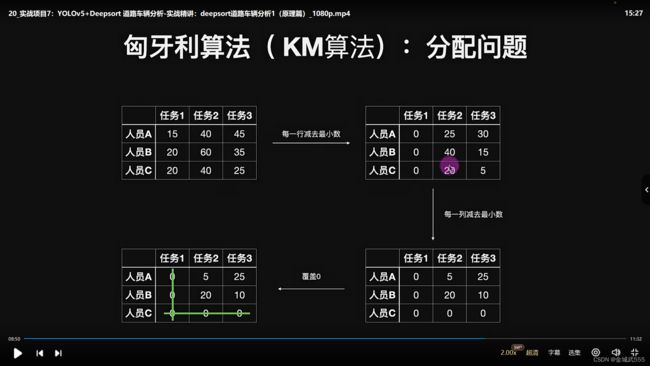
《匈牙利算法 KM》: 最小代价矩阵, 例如:几个人,完成各自任务的时间不同,找出最小代价矩阵,把耗时降到最小的最小代价矩阵。
如:3*3 矩阵,若无n=m个0行之前,重复步骤,行-行最小,列-列最小,行-剩余最小值,列+剩余最小值,直至0行个数与矩阵行数相等为止。。。
最小代价矩阵的代价: 0+0+0,
原来矩阵的最小代价: 20+40+25=85.
在 sort算法中,匈牙利算法的应用: 代价矩阵:== 每一个卡波框/检测框 的 iou距离。
sort算法的有点: 1、速度快 2、没遮挡情况效果好
sort算法的缺点: 1、遮挡无处理,id-Switch次数高 2、有遮挡的准确率低
因此,在sort算法的基础上,引入了级联匹配,更高级的 deepsort算法。
deepsort算法: sort 算法 + iou前:级联匹配 + iou后,轨迹失配下:新轨迹确认。
deepsort算法: 引入了表观信息,表观信息特征,级联匹配提高sort的表现,模型能更高地处理目标被长时间遮挡的 id-Switch现象
比如: 你朋友被遮住了,暂时看不见了,提取了你朋友的表观特征,过会再找一遍!!
级联匹配: 简单解释,即为一种相似度计算,马氏距离协方差,即为,外观特征相似度匹配!!
一、环境安装: deepsort环境:: 名称 deepsort_cuda110 !!
1、cuda 10.1 + pytorch 1.8.1(这个不行,卡顿,卡死,算了10.1你跟不上!!!)
pip install torch==1.8.1+cu101 torchvision==0.9.1+cu101 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
2、yolov5环境
依赖环境: pip install -r requirements.txt
easydict pip install easydict
特殊cd 进入方式: cd '.\yolo_deepsort_0724 _1\' # 字符串格式!!!
3、正确的步骤(前两个,是错误示范!!!)
pip install torch==1.7.1+cu110 torchvision==0.8.2+cu110 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
#### 正确的配置::: torch 1.7.1 + cuda 110 !!!
二、代码准备:
1、修改权重,为官网下载的 yolov5s.pt的预训练文件,发现测试效果不怎么样,IDswitch,还有没跟踪上等问题,因为没有针对特定场景训练,所以我们自己训练一个!
2、摄像头截屏,作为数据集,利用yolov5寻里哪一个自己的预训练模型pt,
2.1 标注: 划分好文件夹,训练集和测试集,
2.2 训练:
1、修改yaml文件,位置dataset文件coco_hightways.yaml,路径path,相对path下的train和val路径,nc=2两类,类名:nc_nmae = ['car','track'],
2、修改yaml文件,模型models规格,yolov5n、s、m.yaml,只需修改类别数量nc,nc为2即可!!!
3、如同上次训练工地防护检测项目,再次进行训练即可。
3、deepsort文件部分:
deepsort文件夹下的deepsort,里面的deep文件,
表征网络,外貌网络的特征提取文件,放在checkpoint 里的 ckpt7.t7 【 checkpoint7.t7 】
ckpt7放在,最外层的deepsort的 configs文件夹的yaml文件里!
4、deepsort的训练【 re-ID 】:
类似于 yolov5训练的检测模型
创建一个类似yolov5的文件夹,里面放置所有文件夹,每个文件里,是每辆车在不同运动时间下的不同状态图,
若需要训练:可以使用deep文件夹下的train.py文件,修改下,--data-dir 数据所在目录即可,
类目(多少个车的文件夹),model.py里,有一个nun_classes,相当于yolov5的nc,修改成文件夹车辆的数量
## 实践: 进入deep目录,python train.py --data-dir ./car-reid-dataset/ ,训练一个epoch即可,因其网络较深,训练较慢!
注意: 训练过程中 ckpt7.t7 会被覆盖,所以最好先备份一个《副本》!
结束后: 他会保存一个训练结果最好的 epoch,模型文件,放在原来的ckpt.t7 的文件夹,覆盖掉原来的那个
deep文件夹下,会生成每一个epoch 下的训练集和测试集的 loss图!!
5、速度估计:
速度 = 距离/时间
时间: 好估计,因为视频帧数 FPS = 1秒内 的画面数,只需每每过 fps帧,即为时间上的 1秒!!
不能用物理上的1 s,因为视频运算,不同模型下,性能有差异,算力不同计算速度不同,不一定是真实的 1秒!!!
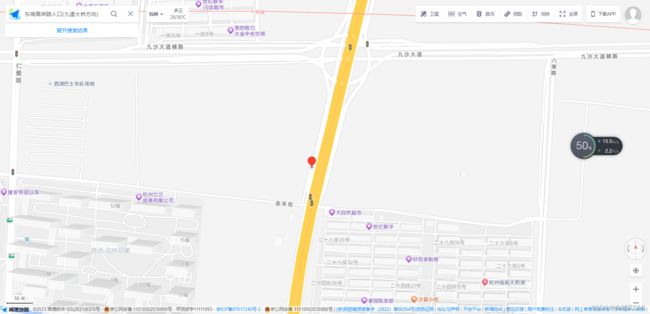
距离: 因为视频画面,斜着拍的,非平面,必须采用《逆透视》,根据经纬度,标注画面,估算出距离!
高德地图: 找出坐标点、点击分享,url地址里,有对应的经纬度信息,
逆透视: 采用网上别人写好的脚本,经纬度逆透视成 距离,pixel_to_dis
视频画面jupyter脚本:
魔法函数%matplotlib qt5,而不是%inline,
jupyter lab 中打开截图,标记坐标点,像素位置xy,
记得点击放大镜,划出矩形位置,放大画面!!!
左上角标记完成,点击一下home,再放大镜放大,要回右下角的xy坐标,
绘制一下原点,以四个点为坐标,看看对不对!!!
高德地图: 获取具体位置的经纬度,
这是哪里,更多,分享!!! url打开后,会有具体的经纬度坐标!!!
三、具体实现,敲代码:
1、目标检测的类: yolov5检测器,图像预处理!
2、目标追踪的类: 实例化一个,deepsort追踪器,
3、速度估计的类: 像素和经纬度的转换!
【注意:】 为保证缩放点,与获取参照点一致,获取的画面之后,frame也要进行缩放一下...
【报错及其修改:】 1、画面记得resize一下,
2、打开方式,parse模块,win系统记得加 try except 判断,encoding='utf-8','r',win系统默认打开的是 gbk模式,
3、画面结束前,记得加一个 无画面的frame is None的判断,否则resize会报错!!!
【代码细节:】 防止id-Switch现象,将结果以中线位置,进行切片!!
检测器可以共用一个画面,实例化两个追踪器,
但是,追踪器必须切分画面,以左右分开独立计算,防止目标窜了!!!
@ 在绘制结果后,记得将frame左右,重新归位,返还给frame, 如: frame[:,:281] = frame_left, frame[:,281:] = frame_right
字典存储每一个id的信息: 如{13:{‘上次的位置,经纬度’:(0,255,255),‘速度’:9,‘类别’:‘卡车’,}}
插入or更新: id在上帧中,更新,else插入!字典形式!
for key,value in this_infos.items()
if key in this_infos,更新,else插入!!
本帧的位置: this_frame_pos = value['lat_pos']
上帧的位置: last_fram_pos = last_frame_info[key]['last_pos']
速度估计: 实例化他人已经封装好的速度估计模块,分别、传入上帧的xy像素点,本帧的xy像素点,即可得出距离估计值!m/s
转化单位m/s to km/h: speed = dis *3.6 比值: 1000/3600 = 3.6 * (10*-1)
创建是/否,需要?更新的空字典! update_dic = {},仅仅保存位置和速度!!
还有一个,可以使用 标志位 ‘left’ 和 ‘right’,
1、判断车头车尾, 2、更新计算各自的坐标 3、绘图:根据标志位的左右,两遍分别,独立绘图!!