大模型微调技术(Adapter-Tuning、Prefix-Tuning、Prompt-Tuning(P-Tuning)、P-Tuning v2、LoRA)
2022年11月30日,ChatGPT发布至今,国内外不断涌现出了不少大模型,呈现“百模大战”的景象,比如ChatGLM-6B、LLAMA、Alpaca等模型及在此模型基础上进一步开发的特定领域的大模型。今年3月15日,GPT-4发布后,也出现了一些多模态的大模型,比如百度的文心一言、讯飞星火认知大模型等等。
要想训练一个针对特定领域的大模型,如果采用全量参数微调(Full Parameter Futuing)的方法,一方面需要大量的高质量数据集、另一方需要较高的算力,比如8块A100 80G GPU,甚至需要成百上千的GPU。一般的小企业或者高校研究所对此望而却步。
那么,有没有不需要大量算力就能在特定领域数据上对大模型进行微调的方法呢?
下面,给大家介绍几种常见的大模型微调方法:Adapter-Tuning、Prefix-Tuning、Prompt-Tuning(P-Tuning)、P-Tuning v2、LoRA。并介绍各种方法之间的效果对比。
1. Adapter-Tuning
该方法出自2019年的论文“Parameter-Efficient Transfer Learning for NLP ”
论文链接:https://arxiv.org/pdf/1902.00751.pdf
github链接:GitHub - google-research/adapter-bert

模型结构如上图左侧所示, 微调时冻结预训练模型的主体,由Adapter模块学习特定下游任务的知识。其中,Adapter模块结构如上图右侧所示,包含两个前馈层和一个中间层,第一个前馈层和中间层起到一个降维的作用,后一个前馈层和中间层起到升维的作用。
Adapter调优的参数量大约为LM参数的3.6%。
2. Prefix-Tuning
该方法出自2021年的论文“Prefix-Tuning: Optimizing Continuous Prompts for Generation”
论文链接:https://arxiv.org/pdf/2101.00190.pdf
github链接:GitHub - XiangLi1999/PrefixTuning: Prefix-Tuning: Optimizing Continuous Prompts for Generation

上图展示了Full Parameter Finetuning与Prefix Tuning之间的区别,其中,红色部分是需要微调的参数,可以发现,Prefix Tuning只是在每个任务前有少量的prefix的参数,比如翻译任务,可以在每句话的前面加上“翻译:”来引导模型进行翻译功能。
实验结果表明:
(1)在完整的数据集上,Prefix-Tunning和Fine-Tuning在table-to-text上的结果是comparable的,而在summarization任务上,prefix-tuning的效果略有下降。但在low-data settings和unseen topics的情况下,Prefix-Tuning的效果更佳。
(2)与Adapter-Tuning相比,Trefix-Tuning在相同的表现下只需调节更少的参数量。
(3)不同的前缀长度有不一样的性能表现,在一定程度上长度越长,prefix的效果越明显,但也可能出现降低的问题。实验表明,prefix长度对推理速度影响不大,因为prefix上的attention是并行计算的。
Prefix Tuning参数规模约为LM模型整体规模的0.1%。
3. Prompt-Tuning(P-Tuning)
该方法出自论文2021年的论文“GPT Understands, Too”
论文链接:https://arxiv.org/pdf/2103.10385.pdf
github链接:https://github.com/THUDM/P-tuning
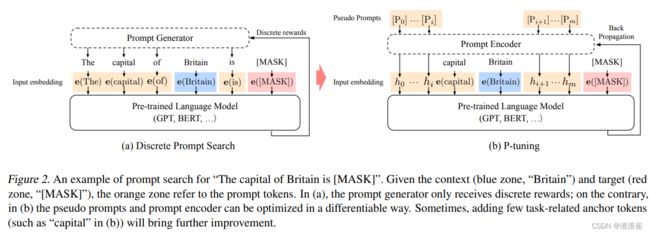
上图展示了P-Tuning和Discrete Prompt Search之间的区别,也引出了P-Tuning提出的目的。因为离线的Prompt对于连续的神经网络只是次优解,prompt的词之间是彼此关联的,需要将其关联起来。于是,P-Tuning将一些伪prompt输入至LSTM中,然后利用LSTM的输出向量来替代原始的prompt token,然后一起输入至预训练语言模型中。而且,LSTM和随着预训练语言模型一起训练。
论文中的实验结果表明:
(1)基于bert-base模型,在5/7的数据集上,P-tuning的效果比finetune等更好。
(2)基于gpt模型,在全部的数据集上,P-tuning的效果都比finetune等更好。
(3)对比gpt-base和bert-base,在6/7的数据集上,基于P-tuning,gpt-base的效果都更好。
(4)在自然语言理解任务上,双向模型比单向模型更好。
4. P-Tuning v2
该方法出自于2022年的论文“P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks”
论文链接:https://arxiv.org/pdf/2110.07602.pdf
github链接:GitHub - THUDM/P-tuning-v2: An optimized deep prompt tuning strategy comparable to fine-tuning across scales and tasks

上图中,左侧为P-Tuning,右侧为P-Tuning v2。P-Tuning v2与P-Tuning的不同之处在于:将只在第一层插入continuous prompt修改为在许多层都插入continuous prompt,层与层之间的continuous prompt是相互独立的。
P-Tuning v2与Prefix-Tuning的改进之处在于,除了输入的embedding外,其它的Transformer层也加了前置的prompt。
做出这种改进的原因:
(1)先前的工作显示,Prompt tuning在normal-sized的预训练模型上效果一般。
(2)现有的Prompt tuning方法在较难的文本序列问题上效果不好。
经过这样的改进,模型可训练参数的量从0.01%增加到了0.1%~3%。
实验结果表明:
(1)P-tuning V2可以与传统Fine-tuning有差不多的效果。
(2)Multi-task P-tuning V2效果更好,分析认为可能是变相的数据增强带来的影响。
(3)在不同的任务上的表现和prompt的长度有关系。
(4)对LSTM/MLP层的重新参数化不一定有效,取决于任务和数据集。
5. LoRA
LoRA(Low-Rank Adaptation)出自2021年的论文“LoRA: Low-Rank Adaptation of Large Language Models”
论文链接:https://arxiv.org/abs/2106.09685
github链接:https://github.com/microsoft/LoRA

LoRA技术冻结预训练模型的权重,并在每个Transformer块中注入可训练层(称为秩分解矩阵),即在模型的Linear层的旁边增加一个“旁支”A和B。其中,A将数据从d维降到r维,这个r是LoRA的秩,是一个重要的超参数;B将数据从r维升到d维,B部分的参数初始为0。模型训练结束后,需要将A+B部分的参数与原大模型的参数合并在一起使用。
LoRA微调的优点包括:
(1)训练速度更快。
(2)计算需求更低。
(3)训练权重更小。
参考文献:
1.预训练模型微调 | 一文带你了解Adapter Tuning - 知乎
2.论文阅读:Prefix-Tuning - 知乎
3.Prefix-Tunning - 知乎
4.【自然语言处理】【Prompt】P-tuning_BQW_的博客-CSDN博客
5.P-tuning v1 v2_开心的火龙果的博客-CSDN博客
6.P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks_Tsukinousag1的博客-CSDN博客
7.LoRA模型是什么?_黑风风的博客-CSDN博客
8.LoRA: Low-Rank Adaptation of Large Language Models 简读 - 知乎