深入探讨分类模型评价指标
每天给你送来NLP技术干货!
来自:AI算法小喵
前言
众所周知,机器学习分类模型常用评价指标有Accuracy, Precision, Recall和F1-score,而回归模型最常用指标有MAE和RMSE。
那么,这些评价指标的意义究竟是什么?今天我们就一起来对多分类模型的评价指标(Accuracy, Precision, Recall以及F1-score)进行深入的探讨:
在具体场景中(如:不均衡多分类)应以哪种指标为主要参考呢?
多分类模型和二分类模型的评价指标有什么区别?
在多分类任务中,为什么有:Accuracy = micro precision = micro recall = micro-F1?
什么时候应用macro, weighted, micro precision/ recall/ F1-score ?
1.Accuracy的不足
在探讨这些问题前,让我们先回顾一下最常见的指标Accuracy到底有哪些不足。
1.1 Accuracy指标
Accuracy是分类任务中最常用的指标,它表示的是分类正确的预测数在总预测数中占据的比例。
1.2 Accuracy的缺陷
但是,对不平衡数据集而言,Accuracy并不是一个好指标。
假设我们有100张图片,其中91张是狗,5张是猫,4张是猪。我们希望训练出一个三分类器来正确判定图片中动物的类别。其中狗这个类别是大多数类 (majority class),也就是说狗的样本数量远超过其他类别(猫、猪)的样本量。
这时,若采用Accuracy指标来评估分类器的好坏,即使模型性能很差 (比如:无论输入什么图片,预测结果均为狗),也可以得到较高的Accuracy Score(如:91%)。此时,虽然Accuracy Score很高,但是意义不大。
当数据异常不平衡时,Accuracy评估方法的缺陷尤为显著。 因此,我们需要引入Precision (精准度),Recall (召回率)和F1-score评估指标。考虑到二分类和多分类模型中,评估指标的计算方法略有不同,我们将其分开讨论。
2. 二分类模型常见指标解析
在二分类任务中,假设该样本一共有两种类别:Positive和Negative。当分类器预测结束,我们可以绘制出混淆矩阵(confusion matrix):
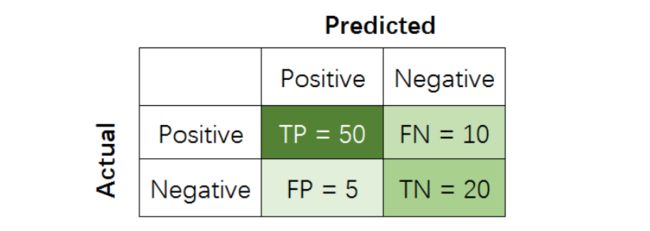
其中分类结果分为如下几种:
TP (True Positive): 把正样本成功预测为正。
TN (True Negative):把负样本成功预测为负。
FP (False Positive):把负样本错误地预测为正。
FN (False Negative):把正样本错误地预测为负。
2.1 二分类模型相关指标
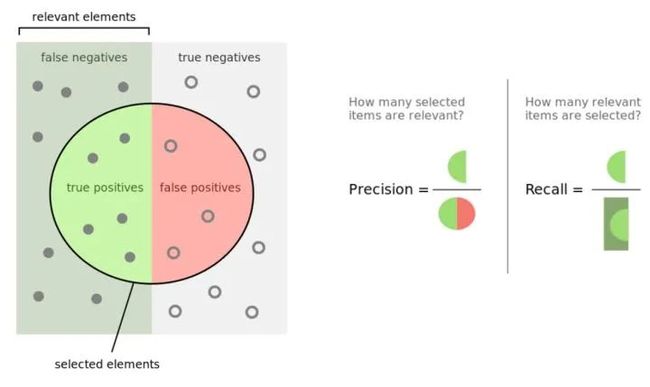
二分类模型中,Accuracy,Precision,Recall和F1 score的定义如下:
其中,Precision着重评估在预测为Positive的所有数据中,真实Positve的数据到底占多少? Recall 着重评估:在所有的Positive数据中,到底有多少数据被成功预测为Positive?
2.2 以哪种指标为主要参考
以医院开发的癌症AI诊断系统的性能评估为例。在这个例子中,病人得了癌症定义为Positive,没得癌症定义为Negative。
如用Precision对系统进行评估,那么其回答的问题就是:
在诊断为癌症的一堆人中,到底有多少人真得了癌症?如用Recall对系统进行评估,那么其回答的问题就是:
在一堆得了癌症的病人中,到底有多少人能被成功检测出癌症?如用Accuracy对系统进行评估,那么其回答的问题就是:
在一堆癌症病人和正常人中,有多少人被系统给出了正确诊断结果(患癌或没患癌)?(1)更注重Recall而不是Precision
当FN的成本代价很高 (后果很严重),希望尽量避免产生FN时,应该着重考虑提高Recall指标。
在上述例子里,FN 是得了癌症的病人没有被诊断出癌症,这种情况是最应该避免的。我们宁可把健康人误诊为癌症 (FP),也不能让真正患病的人检测不出癌症 (FN) 而耽误治疗离世。在这里,癌症诊断系统的目标是:尽可能提高Recall值,哪怕牺牲一部分Precision。
(2)更注重Precision而不是Recall
当FP 的成本代价很高 (后果很严重)时,即期望尽量避免产生FP时,应该着重考虑提高Precision指标。
以垃圾邮件屏蔽系统为例,垃圾邮件为Positive,正常邮件为Negative,FP是把正常邮件识别为垃圾邮件,这种情况是最应该避免的(你能容忍一封重要工作邮件直接进了垃圾箱,被不知不觉删除吗?)。
我们宁可把垃圾邮件标记为正常邮件 (FN),也不能让正常邮件直接进垃圾箱 (FP)。在这里,垃圾邮件屏蔽系统的目标是:尽可能提高Precision值,哪怕牺牲一部分recall。
(3)F1-Score
F1-Score是Precision和Recall二者的调和平均。
举个更有意思的例子,假设检察机关想将罪犯捉拿归案,需要对所有人群进行分析,以判断某人犯了罪(Positive),还是没犯罪(Negative)。显然,检察机关希望不漏掉一个罪人(提高recall),也不错怪一个好人(提高precision),所以就需要同时权衡recall和precision两个指标。
「天网恢恢,疏而不漏,任何罪犯都插翅难飞」更偏向Recall,「绝不冤枉一个好人,但难免有罪犯成为漏网之鱼,逍遥法外」更偏向Precision。到底哪种更好呢?显然,极端并不可取。Precision和Recall都应该越高越好,也就是F1应该越高越好。
3. 多分类模型的常见指标解析
在多分类(大于两个类)问题中,假设我们要开发一个动物识别系统,来区分输入图片是猫,狗还是猪。给分类器一堆动物图片,产生了如下结果混淆矩阵。
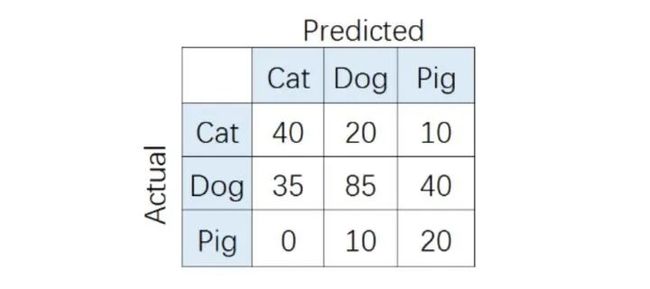
在混淆矩阵中,正确的分类样本(Actual label = Predicted label)分布在左上到右下的对角线上。其中,Accuracy的定义为分类正确(对角线上)的样本数与总样本数的比值。Accuracy度量的是全局样本预测情况,而对于Precision和Recall而言,每个类都需要单独计算其Precision和Recall。
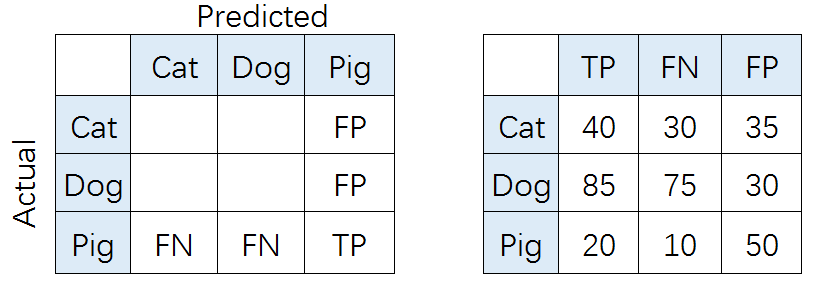
比如,对类别猪而言,其Precision和Recall分别为:
402 Payment Required
以P代表Precision,R代表Recall。也就是有:
如果想评估该识别系统的总体功能,必须考虑猫、狗、猪三个类别的综合预测性能。那么,要怎么综合这三个类别的相关指标呢?是简单加起来做平均吗?通常来说, 我们有如下几种解决方案(也可参考scikit-learn官网[1])。
3.1 Macro-average方法
Macro-average方法最简单,它给予所有类别相同的权重,然后直接将不同类别的评估指标(Precision/ Recall/ F1-score)加起来求平均。该方法能够平等看待每个类别,但是它的值会受稀有类别影响。
402 Payment Required
402 Payment Required
3.2 Weighted-average方法
Weighted-average方法给不同类别不同权重(权重根据该类别的真实分布比例确定),每个类别乘权重后再进行相加。该方法考虑了类别不平衡情况,它的值更容易受到常见类(majority class)的影响。
假设以W代表权重,N代表样本在该类别下的真实数目,我们有:
402 Payment Required
那么指标计算如下:
402 Payment Required
402 Payment Required
3.3 Micro-average方法
Micro-average方法把每个类别的TP, FP, FN先相加之后,然后根据二分类的公式进行计算:
402 Payment Required
其中,特别有意思的是,Micro-precision和Micro-recall竟然始终相同(需要注意,这个结论在实体识别等任务中不成立)! 因为在某一类中的FP样本,一定是其他某类别的FN样本。听起来有点抽象?举个例子,比如说系统错把狗预测成猫,那么对于狗而言,其错误类型就是FN,对于猫而言,其错误类型就是FP。与此同时,Micro-precision和Micro-recall的数值都等于Accuracy,因为它们计算了对角线样本数和总样本数的比值,总结就是:
402 Payment Required
最后运行一下代码,检验手动计算结果是否和Sklearn包结果一致:
import numpy as np
import seaborn as sns
from sklearn.metrics import confusion_matrix
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score, average_precision_score,precision_score,f1_score,recall_score
# create confusion matrix
y_true = np.array([-1]*70 + [0]*160 + [1]*30)
y_pred = np.array([-1]*40 + [0]*20 + [1]*20 +
[-1]*30 + [0]*80 + [1]*30 +
[-1]*5 + [0]*15 + [1]*20)
cm = confusion_matrix(y_true, y_pred)
conf_matrix = pd.DataFrame(cm, index=['Cat','Dog','Pig'], columns=['Cat','Dog','Pig'])
# plot size setting
fig, ax = plt.subplots(figsize = (4.5,3.5))
sns.heatmap(conf_matrix, annot=True, annot_kws={"size": 19}, cmap="Blues")
plt.ylabel('True label', fontsize=18)
plt.xlabel('Predicted label', fontsize=18)
plt.xticks(fontsize=18)
plt.yticks(fontsize=18)
plt.savefig('confusion.pdf', bbox_inches='tight')
plt.show()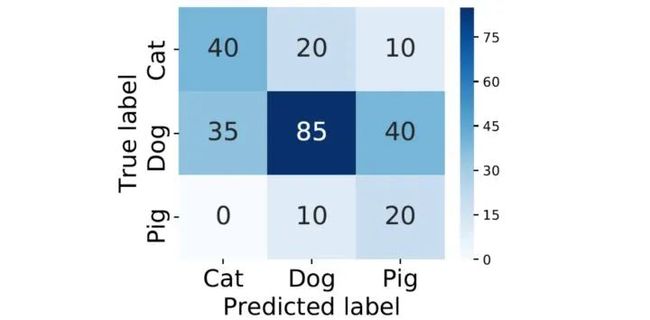
print('------Weighted------')
print('Weighted precision', precision_score(y_true, y_pred, average='weighted'))
print('Weighted recall', recall_score(y_true, y_pred, average='weighted'))
print('Weighted f1-score', f1_score(y_true, y_pred, average='weighted'))
print('------Macro------')
print('Macro precision', precision_score(y_true, y_pred, average='macro'))
print('Macro recall', recall_score(y_true, y_pred, average='macro'))
print('Macro f1-score', f1_score(y_true, y_pred, average='macro'))
print('------Micro------')
print('Micro precision', precision_score(y_true, y_pred, average='micro'))
print('Micro recall', recall_score(y_true, y_pred, average='micro'))
print('Micro f1-score', f1_score(y_true, y_pred, average='micro'))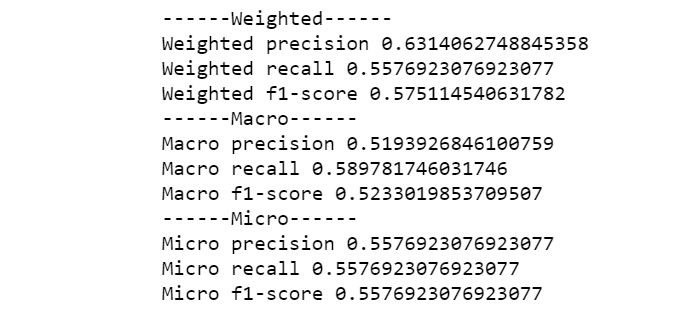
运算结果完全一致。
来源:https://zhuanlan.zhihu.com/p/147663370
作者:NaNNN
编辑:@公众号:AI算法小喵
如果本文对你有帮助的话,欢迎点赞&在看&分享,这对我继续分享&创作优质文章非常重要。感谢!
参考资料
[1]
scikit-learn官网: https://link.zhihu.com/?target=https%3A//scikit-learn.org/stable/modules/generated/sklearn.metrics.precision_score.html
最近文章
EMNLP 2022 和 COLING 2022,投哪个会议比较好?
一种全新易用的基于Word-Word关系的NER统一模型
阿里+北大 | 在梯度上做简单mask竟有如此的神奇效果
ACL'22 | 快手+中科院提出一种数据增强方法:Text Smoothing
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套! 后台回复【五件套】
下载二:南大模式识别PPT 后台回复【南大模式识别】投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!