from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import pandas as pd
from pandas import DataFrame
import time
mpl.rcParams['font.sans-serif']=[u'simHei']
mpl.rcParams['axes.unicode_minus']=False
path1='datas/household_power_consumption_1000.txt'
df = pd.read_csv(path1, sep=';', low_memory=False)
df.head()
|
Date |
Time |
Global_active_power |
Global_reactive_power |
Voltage |
Global_intensity |
Sub_metering_1 |
Sub_metering_2 |
Sub_metering_3 |
| 0 |
16/12/2006 |
17:24:00 |
4.216 |
0.418 |
234.84 |
18.4 |
0.0 |
1.0 |
17.0 |
| 1 |
16/12/2006 |
17:25:00 |
5.360 |
0.436 |
233.63 |
23.0 |
0.0 |
1.0 |
16.0 |
| 2 |
16/12/2006 |
17:26:00 |
5.374 |
0.498 |
233.29 |
23.0 |
0.0 |
2.0 |
17.0 |
| 3 |
16/12/2006 |
17:27:00 |
5.388 |
0.502 |
233.74 |
23.0 |
0.0 |
1.0 |
17.0 |
| 4 |
16/12/2006 |
17:28:00 |
3.666 |
0.528 |
235.68 |
15.8 |
0.0 |
1.0 |
17.0 |
df.info()
RangeIndex: 1000 entries, 0 to 999
Data columns (total 9 columns):
Date 1000 non-null object
Time 1000 non-null object
Global_active_power 1000 non-null float64
Global_reactive_power 1000 non-null float64
Voltage 1000 non-null float64
Global_intensity 1000 non-null float64
Sub_metering_1 1000 non-null float64
Sub_metering_2 1000 non-null float64
Sub_metering_3 1000 non-null float64
dtypes: float64(7), object(2)
memory usage: 70.4+ KB
new_df = df.replace('?', np.nan)
datas = new_df.dropna(axis=0, how = 'any')
datas.describe().T
|
count |
mean |
std |
min |
25% |
50% |
75% |
max |
| Global_active_power |
1000.0 |
2.418772 |
1.239979 |
0.206 |
1.806 |
2.414 |
3.308 |
7.706 |
| Global_reactive_power |
1000.0 |
0.089232 |
0.088088 |
0.000 |
0.000 |
0.072 |
0.126 |
0.528 |
| Voltage |
1000.0 |
240.035790 |
4.084420 |
230.980 |
236.940 |
240.650 |
243.295 |
249.370 |
| Global_intensity |
1000.0 |
10.351000 |
5.122214 |
0.800 |
8.400 |
10.000 |
14.000 |
33.200 |
| Sub_metering_1 |
1000.0 |
0.000000 |
0.000000 |
0.000 |
0.000 |
0.000 |
0.000 |
0.000 |
| Sub_metering_2 |
1000.0 |
2.749000 |
8.104053 |
0.000 |
0.000 |
0.000 |
1.000 |
38.000 |
| Sub_metering_3 |
1000.0 |
5.756000 |
8.066941 |
0.000 |
0.000 |
0.000 |
17.000 |
19.000 |
df.info()
RangeIndex: 1000 entries, 0 to 999
Data columns (total 9 columns):
Date 1000 non-null object
Time 1000 non-null object
Global_active_power 1000 non-null float64
Global_reactive_power 1000 non-null float64
Voltage 1000 non-null float64
Global_intensity 1000 non-null float64
Sub_metering_1 1000 non-null float64
Sub_metering_2 1000 non-null float64
Sub_metering_3 1000 non-null float64
dtypes: float64(7), object(2)
memory usage: 70.4+ KB
def date_format(dt):
import time
t = time.strptime(' '.join(dt), '%d/%m/%Y %H:%M:%S')
return (t.tm_year, t.tm_mon, t.tm_mday, t.tm_hour, t.tm_min, t.tm_sec)
X = datas.iloc[:,0:2]
X = X.apply(lambda x: pd.Series(date_format(x)), axis=1)
Y = datas['Global_active_power']
X.head(2)
|
0 |
1 |
2 |
3 |
4 |
5 |
| 0 |
2006 |
12 |
16 |
17 |
24 |
0 |
| 1 |
2006 |
12 |
16 |
17 |
25 |
0 |
X_train,X_test,Y_train,Y_test = train_test_split(X, Y, test_size=0.2, random_state=0)
print(X_train.shape)
print(X_test.shape)
print(Y_train.shape)
(800, 6)
(200, 6)
(800,)
X_train.describe()
ss = StandardScaler()
X_train = ss.fit_transform(X_train)
X_test = ss.transform(X_test)
pd.DataFrame(X_train).describe()
|
0 |
1 |
2 |
3 |
4 |
5 |
| count |
800.0 |
800.0 |
8.000000e+02 |
8.000000e+02 |
8.000000e+02 |
800.0 |
| mean |
0.0 |
0.0 |
2.445821e-15 |
-8.604228e-17 |
8.104628e-17 |
0.0 |
| std |
0.0 |
0.0 |
1.000626e+00 |
1.000626e+00 |
1.000626e+00 |
0.0 |
| min |
0.0 |
0.0 |
-1.221561e+00 |
-1.333814e+00 |
-1.722545e+00 |
0.0 |
| 25% |
0.0 |
0.0 |
-1.221561e+00 |
-8.377420e-01 |
-8.532677e-01 |
0.0 |
| 50% |
0.0 |
0.0 |
8.186245e-01 |
-3.416698e-01 |
1.600918e-02 |
0.0 |
| 75% |
0.0 |
0.0 |
8.186245e-01 |
1.022529e+00 |
8.852861e-01 |
0.0 |
| max |
0.0 |
0.0 |
8.186245e-01 |
1.518601e+00 |
1.696611e+00 |
0.0 |
lr = LinearRegression(fit_intercept=True)
lr.fit(X_train, Y_train)
y_predict = lr.predict(X_test)
print("训练集上R2:",lr.score(X_train, Y_train))
print("测试集上R2:",lr.score(X_test, Y_test))
mse = np.average((y_predict-Y_test)**2)
rmse = np.sqrt(mse)
print("rmse:",rmse)
训练集上R2: 0.24409311805909026
测试集上R2: 0.12551628513735869
rmse: 1.1640923459736248
print("模型的系数(θ):", end="")
print(lr.coef_)
print("模型的截距:", end='')
print(lr.intercept_)
模型的系数(θ):[ 0.00000000e+00 -6.66133815e-16 -1.41588166e+00 -9.34953243e-01
-1.02140756e-01 0.00000000e+00]
模型的截距:2.4454375000000033
from sklearn.externals import joblib
joblib.dump(ss, "result/data_ss.model")
joblib.dump(lr, "result/data_lr.model")
ss3 = joblib.load("result/data_ss.model")
lr3 = joblib.load("result/data_lr.model")
data1 = [[2006, 12, 17, 12, 25, 0]]
data1 = ss3.transform(data1)
print(data1)
lr3.predict(data1)
[[ 0. 0. 0.81862454 0.15440249 -0.27374978 0. ]]
array([1.16996393])
t=np.arange(len(X_test))
plt.figure(facecolor='w')
plt.plot(t, Y_test, 'r-', linewidth=2, label='真实值')
plt.plot(t, y_predict, 'g-', linewidth=2, label='预测值')
plt.legend(loc = 'upper left')
plt.title("线性回归预测时间和功率之间的关系", fontsize=20)
plt.grid(b=True)
plt.show()

X = datas.iloc[:,2:4]
Y2 = datas.iloc[:,5]
X2_train,X2_test,Y2_train,Y2_test = train_test_split(X, Y2, test_size=0.2, random_state=0)
scaler2 = StandardScaler()
X2_train = scaler2.fit_transform(X2_train)
X2_test = scaler2.transform(X2_test)
lr2 = LinearRegression()
lr2.fit(X2_train, Y2_train)
Y2_predict = lr2.predict(X2_test)
print("电流预测准确率: ", lr2.score(X2_test,Y2_test))
print("电流参数:", lr2.coef_)
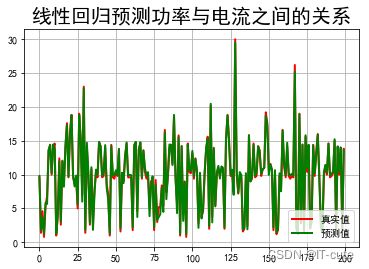
t=np.arange(len(X2_test))
plt.figure(facecolor='w')
plt.plot(t, Y2_test, 'r-', linewidth=2, label=u'真实值')
plt.plot(t, Y2_predict, 'g-', linewidth=2, label=u'预测值')
plt.legend(loc = 'lower right')
plt.title(u"线性回归预测功率与电流之间的关系", fontsize=20)
plt.grid(b=True)
plt.show()
电流预测准确率: 0.9920420609708968
电流参数: [5.07744316 0.07191391]