一文解读Go并发编程
要搞清楚Go并发编程,就需要先清楚操作系统的线程库,因为真正的“跑腿的”是系统线程。先介绍线程实现的相关概念
1.线程模型
线程的实现模型主要有三个
- 用户级别线程模型
- 内核级线程模型
- 两级线程模型
他们之间的差异在于用户线程与**内核实体调度(KSE)**之间的对应关系。
这里我们要明白一个概念:内核调度实体就是被操作系统内核调度的对象,也称为内核级线程,是操作系统内核的最小调度单位。
1.1 用户级线程模型
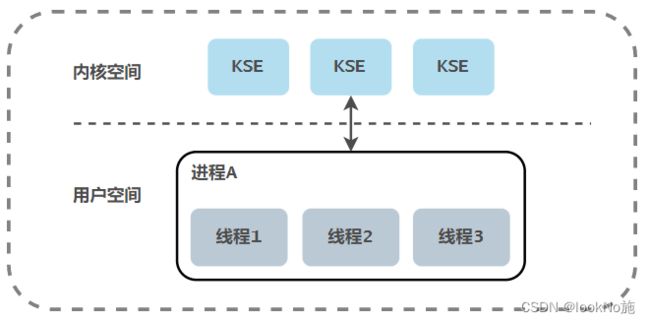
用户线程与内核线程(KSE)为N:1的对应关系。
特点:
- 此模型下的线程由用户级别的线程库全权管理,线程库存储在进程的用户空间之中,这些线程的存在对于内核来说是无法感知的,所以这些线程也不是内核调度器调度的对象。线程的调度则是在用户层面完成的。
- 一个进程中所有创建的线程都只和同一个KSE在运行时动态绑定,内核的所有调度都是基于用户进程的。
优点:
- 不需要让CPU在用户态和内核态之间切换,对系统资源的消耗会小很多,上下文切换所花费的代价也会小得多,总之就是更加轻量级。
缺点:
- 此模型下的多线程并不能真正的并发运行
- 如果某个线程在I/O操作过程中被阻塞,那么其所属进程内的所有线程都被阻塞,整个进程将被挂起。
1.2 内核级线程模型
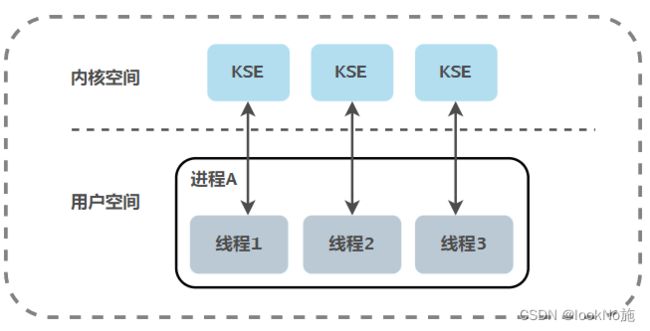
用户线程与内核线程(KSE)为一比一(1:1)的映射关系
特点:
- 该模型下的线程由内核负责管理。
- 应用程序对线程的创建、终止和同步都必须通过内核提供的系统调用来完成。
优点:
- 一对一线程模型可以真正的实现线程的并发运行。
缺点:
- 此模型下线程的创建、切换和同步都需要花费更多的内核资源和时间,如果一个进程包含了大量的线程,那么它会给内核的调度器造成非常大的负担,甚至会影响到操作系统的整体性能。
1.3 两级线程模型

用户线程与内核线程(KSE)为多对多(N:M)的映射关系。
巧妙吸收了用户级线程与内核级线程的优点,一个进程内的多个线程可以分别绑定一个自己的KSE,这点与内核级线程模型相似,但是用户线程并不与KSE唯一绑定,可以多个用户线程映射到同一个KSE。
当某个KSE因为其绑定的线程阻塞被调度出CPU时,其关联的进程中其余的用户线程可以重新与其他KSE绑定。
特点:
- 两级线程模型既不是用户级线程模型那种完全靠自己调度的也不是内核级线程模型完全靠操作系统调度的,而是一种自身调度与系统调度协同工作的中间态。
- 用户调度器实现用户线程到KSE的调度,内核调度器实现KSE到CPU上的调度。
2.Go的并发机制
在Go的并发编程模型中的用户线程被称之为goroutine。
很多人将goroutine理解为协程,这是不够精确的,我们所理解的传统意义上的协程属于用户级线程模型,而goroutine结合Go调度器的底层实现属于两级线程模型
Go的调度器使用G、M、P三个结构体来实现goroutine的调度,也称之为GMP模型。
2.1 GMP模型
G :表示goroutine。
- 每个Goroutine对应一个G结构体
- G存储Goroutine的运行堆栈、状态以及任务函数,可重用
当Goroutine被调离CPU时,调度器代码负责把CPU寄存器的值保存在G对象的成员变量之中,当Goroutine被调度起来运行时,调度器代码又负责把G对象的成员变量所保存的寄存器的值恢复到CPU的寄存器。
M:内核线程。
- 它代表着真正执行计算的资源。
- 由操作系统的调度器调度和管理。
M结构体对象除了记录着工作线程的诸如栈的起止位置、当前正在执行的Goroutine以及是否空闲等等状态信息之外,还通过指针维持着与P结构体的实例对象之间的绑定关系。
P:表示逻辑处理器。
- 对G来说,P相当于CPU核,G只有绑定到P(在P的local runq中)才能被调度。
- 对M来说,P提供了相关的执行环境(Context),如内存分配状态(mcache),任务队列(G)等。
P维护一个局部Goroutine可运行G队列,工作线程优先使用自己的局部运行队列,只有必要时才会去访问全局运行队列,这可以大大减少锁冲突,提高工作线程的并发性,并且可以良好的运用程序的局部性原理。
一个G的执行需要P和M的支持。一个M在与一个P关联之后,就形成了一个有效的G运行环境(内核线程+上下文)。每个P都包含一个可运行的G的队列(runq)。该队列中的G会被依次传递给与本地P关联的M,并获得运行时机。
M与KSE之间总是一一对应的关系,一个M仅能代表一个内核线程。M与KSE之间的关联非常稳固,一个M在其生命周期内,会且仅会与一个KSE产生关联,而M与P、P与G之间的关联都是可变的,M与P也是一对一的关系,P与G则是一对多的关系。
2.2 G
Go语言的goroutine与内核级线程(KSE)相比,占用了更小的内存空间,降低了上下文开销。
g结构体部分源码(src/runtime/runtime2.go):
type g struct {
stack stack // Goroutine的栈内存范围[stack.lo, stack.hi)
stackguard0 uintptr // 用于调度器抢占式调度
m *m // Goroutine占用的线程
sched gobuf // Goroutine的调度相关数据
atomicstatus uint32 // Goroutine的状态
...
}
type gobuf struct {
sp uintptr // 栈指针
pc uintptr // 程序计数器
g guintptr // gobuf对应的Goroutine
ret sys.Uintewg // 系统调用的返回值
...
}
gobuf中保存的内容会在调度器保存或恢复上下文时使用,其中栈指针和程序计数器会用来存储或恢复寄存器中的值,改变程序即将执行的代码。
atomicstatus字段存储了当前Goroutine的状态,Goroutine主要可能处于以下9种状态:
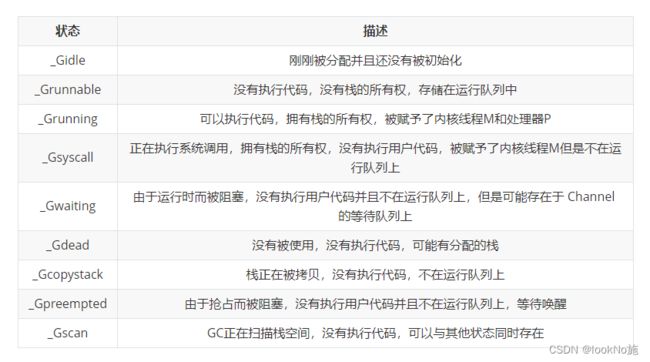
Goroutine的状态迁移是一个十分复杂的过程,触发状态迁移的方法也很多。这里主要介绍一下比较常见的五种状态_Grunnable、_Grunning、_Gsyscall、_Gwaiting和_Gpreempted。
可以将这些不同的状态聚合成三种:等待中、可运行、运行中,运行期间会在这三种状态来回切换:
- 等待中:Goroutine正在等待某些条件满足,例如:系统调用结束等,包括_Gwaiting、_Gsyscall和_Gpreempted几个状态;
- 可运行:Goroutine已经准备就绪,可以在线程运行,如果当前程序中有非常多的Goroutine,每个Goroutine就可能会等待更多的时间,即_Grunnable;
- 运行中:Goroutine正在某个线程上运行,即_Grunning。
2.3 M
Go语言并发模型中的M是操作系统线程。调度器最多可以创建10000个线程,但是最多只会有GOMAXPROCS(P的数量)个活跃线程能够正常运行。在默认情况下,运行时会将 GOMAXPROCS设置成当前机器的核数,我们也可以在程序中使用runtime.GOMAXPROCS来改变最大的活跃线程数。
例如,对于一个四核的机器,runtime会创建四个活跃的操作系统线程,每一个线程都对应一个运行时中的runtime.m结构体。在大多数情况下,我们都会使用Go的默认设置,也就是线程数等于CPU数,默认的设置不会频繁触发操作系统的线程调度和上下文切换,所有的调度都会发生在用户态,由Go语言调度器触发,能够减少很多额外开销。
m结构体源码(部分):
type m struct {
g0 *g // 一个特殊的goroutine,执行一些运行时任务
gsignal *g // 处理signal的G
curg *g // 当前M正在运行的G的指针
p puintptr // 正在与当前M关联的P
nextp puintptr // 与当前M潜在关联的P
oldp puintptr // 执行系统调用之前使用线程的P
spinning bool // 当前M是否正在寻找可运行的G
lockedg *g // 与当前M锁定的G
}
2.4 P
调度器中的处理器P是线程和Goroutine的中间层,它能提供线程需要的上下文环境,也会负责调度线程上的等待队列,通过处理器P的调度,每一个内核线程都能够执行多个Goroutine,它能在Goroutine进行一些I/O操作时及时让出计算资源,提高线程的利用率。
P的数量等于GOMAXPROCS,设置GOMAXPROCS的值只能限制P的最大数量,对M和G的数量没有任何约束。当M上运行的G进入系统调用导致M被阻塞时,运行时系统会把该M和与之关联的P分离开来,这时,如果该P的可运行G队列上还有未被运行的G,那么运行时系统就会找一个空闲的M,或者新建一个M与该P关联,满足这些G的运行需要。因此,M的数量很多时候都会比P多。
p结构体源码(部分):
type p struct {
// p 的状态
status uint32
// 对应关联的 M
m muintptr
// 可运行的Goroutine队列,可无锁访问
runqhead uint32
runqtail uint32
runq [256]guintptr
// 缓存可立即执行的G
runnext guintptr
// 可用的G列表,G状态等于Gdead
gFree struct {
gList
n int32
}
...
}
3 调度器
两级线程模型中的一部分调度任务会由操作系统之外的程序承担。在Go语言中,调度器就负责这一部分调度任务。调度的主要对象就是G、M和P的实例。每个M(即每个内核线程)在运行过程中都会执行一些调度任务,他们共同实现了Go调度器的调度功能。
3.1 g0和m0
运行时系统中的每个M都会拥有一个特殊的G,一般称为M的g0。M的g0不是由Go程序中的代码间接生成的,而是由Go运行时系统在初始化M时创建并分配给该M的。M的g0一般用于执行调度、垃圾回收、栈管理等方面的任务。M还会拥有一个专用于处理信号的G,称为gsignal。
除了g0和gsignal之外,其他由M运行的G都可以视为用户级别的G,简称用户G,g0和gsignal可称为系统G。Go运行时系统会进行切换,以使每个M都可以交替运行用户G和它的g0。这就是前面所说的“每个M都会运行调度程序”的原因。
除了每个M都拥有属于它自己的g0外,还存在一个runtime.g0。runtime.g0用于执行引导程序,它运行在Go程序拥有的第一个内核线程之中,这个线程也称为runtime.m0,runtime.m0的g0就是runtime.g0。