前端不懂编译器,再多框架也无力-JS 编译器都做了啥?
在写这篇文章之前,小编工作中从来没有问过自己这个问题,不就是写代码,编译器将代码编辑成计算机能识别的 01 代码,有什么好了解的。
其实不然,编译器在将 JS 代码变成可执行代码,做了很多繁杂的工作,只有深入了解背后编译的原理,我们才能写出更优质的代码,了解各种前端框架背后的本质。
为了写这篇文章,小编也是诚惶诚恐,阅读了相关的资料,也是一个学习了解的过程,难免有些问题,欢迎各位指正,共同提高。
题外话——重回孩童时代的好奇心
现在的生活节奏和压力,也许让我们透不过气,我们日复一日的写着代码,疲于学习各种各样前端框架,学习的速度总是赶不上更新的速度,经常去寻找解决问题或修复 BUG 的最佳方式,却很少有时间去真正的静下心来研究我们最基础工具——JavaScript 语言。
不知道大家是否还记得自己孩童时代,看到一个新鲜的事物或玩具,是否有很强的好奇心,非要打破砂锅问你到底。但是在我们的工作中,遇到的各种代码问题,你是否有很强的好奇心,一探究竟,还是把这些问题加入"黑名单",下次不用而已,不知所以然。
其实我们应该重回孩童时代,不应满足会用,只让代码工作而已,我们应该弄清楚"为什么",只有这样你才能拥抱整个 JavaScript。掌握了这些知识后,无论什么技术、框架你都能轻松理解,这也前端达人公众号一直更新 javaScript 基础的原因。
不要混淆 JavaScipt 与浏览器
语言和环境是两个不同的概念。提及 JavaScript,大多数人可能会想到浏览器,脱离浏览器 JavaScipt 是不可能运行的,这与其他系统级的语言有着很大的不同。例如 C 语言可以开发系统和制造环境,而 JavaScript 只能寄生在某个具体的环境中才能够工作。
JavaScipt 运行环境一般都有宿主环境和执行期环境。如下图所示:

宿主环境是由外壳程序生成的,比如浏览器就是一个外壳环境(但是浏览器并不是唯一,很多服务器、桌面应用系统都能也能够提供 JavaScript 引擎运行的环境)。执行期环境则有嵌入到外壳程序中的 JavaScript 引擎(比如 V8 引擎,稍后会详细介绍)生成,在这个执行期环境,首先需要创建一个代码解析的初始环境,初始化的内容包含:
- 一套与宿主环境相关联系的规则
- JavaScript 引擎内核(基本语法规则、逻辑、命令和算法)
- 一组内置对象和 API
- 其他约定
虽然,不同的 JavaScript 引擎定义初始化环境是不同的,这就形成了所谓的浏览器兼容性问题,因为不同的浏览器使用不同 JavaScipt 引擎。
不过最近的这条消息想必大家都知道——浏览器市场,微软居然放弃了自家的 EDGE(IE 的继任者),转而投靠竞争对手 Google 主导的 Chromium 核心(国产浏览器百度、搜狗、腾讯、猎豹、UC、傲游、360 用的都是 Chromium(Chromium 用的是鼎鼎大名的 V8 引擎,想必大家都十分清楚吧),可以认为全是 Chromium 的马甲),真是大快人心,我们终于在同一环境下愉快的编写代码了,想想真是开心!
重温编译原理
一提起 JavaScript 语言,大部分的人都将其归类为“动态”或“解释执行”语言,其实他是一门“编译性”语言。与传统的编译语言不同,它不是提前编译的,编译结果也不能在分布式系统中进行移植。在介绍 JavaScript 编译器原理之前,小编和大家一起重温下基本的编译器原理,因为这是最基础的,了解清楚了我们更能了解 JavaScript 编译器。
编译程序一般步骤分为:词法分析、语法分析、语义检查、代码优化和生成字节码。
具体的编译流程如下图:
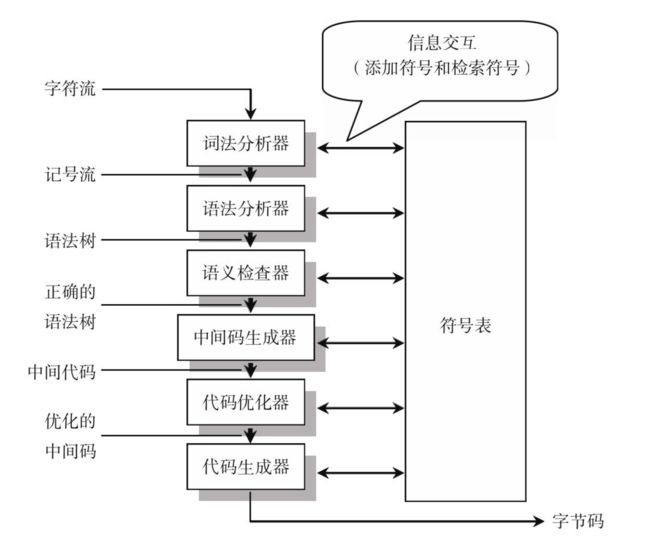
分词/词法分析(Tokenizing/Lexing)
所谓的分词,就好比我们将一句话,按照词语的最小单位进行分割。计算机在编译一段代码前,也会将一串串代码拆解成有意义的代码块,这些代码块被称为词法单元(token)。
例如,考虑程序 var a=2。这段程序通常会被分解成为下面这些词法单元:var,a,=,2;空格是否作为当为词法单位,取决于空格在这门语言中是否具有意义。
解析/语法分析(Parsing)
这个过程是将词法单元流转换成一个由元素逐级嵌套所组成的代表了程序语法结构的树。这个树称为“抽象语法树”(Abstract Syntax Tree,AST)。
词法分析和语法分析不是完全独立的,而是交错进行的,也就是说,词法分析器不会在读取所有的词法记号后再使用语法分析器来处理。在通常情况下,每取得一个词法记号,就将其送入语法分析器进行分析。

语法分析的过程就是把词法分析所产生的记号生成语法树,通俗地说,就是把从程序中收集的信息存储到数据结构中。注意,在编译中用到的数据结构有两种:符号表和语法树。
符号表:就是在程序中用来存储所有符号的一个表,包括所有的字符串变量、直接量字符串,以及函数和类。
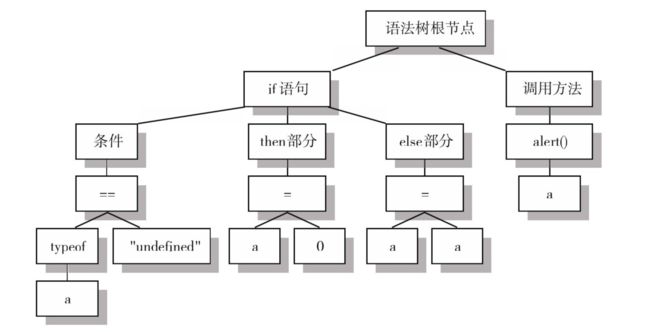
语法树:就是程序结构的一个树形表示,用来生成中间代码。下面是一个简单的条件结构和输出信息代码段,被语法分析器转换为语法树之后,如:
if (typeof a == "undefined") {
a = 0;
} else {
a = a;
}
alert(a);
如果 JavaScript 解释器在构造语法树的时候发现无法构造,就会报语法错误,并结束整个代码块的解析。对于传统强类型语言来说,在通过语法分析构造出语法树后,翻译出来的句子可能还会有模糊不清的地方,需要进一步的语义检查。
**语义检查的主要部分是类型检查。**例如,函数的实参和形参类型是否匹配。但是,对于弱类型语言来说,就没有这一步。
经过编译阶段的准备, JavaScript 代码在内存中已经被构建为语法树,然后 JavaScript 引擎就会根据这个语法树结构边解释边执行。
代码生成
将 AST 转换成可执行代码的过程被称为代码生成。这个过程与语言、目标平台相关。
了解完编译原理后,其实 JavaScript 引擎要复杂的许多,因为大部分情况,JavaScript 的编译过程不是发生在构建之前,而是发生在代码执行前的几微妙,甚至时间更短。为了保证性能最佳,JavaScipt 使用了各种办法,稍后小编将会详细介绍。
神秘的 JavaScipt 编译器——V8 引擎
由于 JavaScipt 大多数都是运行在浏览器上,不同浏览器的使用的引擎也各不相同,以下是目前主流浏览器引擎:
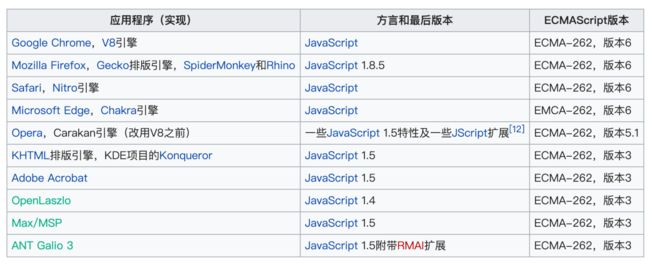
由于谷歌的 V8 编译器的出现,由于性能良好吸引了相当的注目,正式由于 V8 的出现,我们目前的前端才能大放光彩,百花齐放,V8 引擎用 C++进行编写, 作为一个 JavaScript 引擎,最初是服役于 Google Chrome 浏览器的。它随着 Chrome 的第一版发布而发布以及开源。现在它除了 Chrome 浏览器,已经有很多其他的使用者了。诸如 NodeJS、MongoDB、CouchDB 等。
最近最让人振奋前端新闻莫过于微软居然放弃了自家的 EDGE(IE 的继任者),转而投靠竞争对手 Google 主导的 Chromium 核心(国产浏览器百度、搜狗、腾讯、猎豹、UC、傲游、360 用的都是 Chromium(Chromium 用的是鼎鼎大名的 V8 引擎,想必大家都十分清楚吧),看来 V8 引擎在不久的将来就会一统江湖,下面小编将重点介绍 V8 引擎。
当 V8 编译 JavaScript 代码时,解析器(parser)将生成一个抽象语法树(上一小节已介绍过)。语法树是 JavaScript 代码的句法结构的树形表示形式。解释器 Ignition 根据语法树生成字节码。TurboFan 是 V8 的优化编译器,TurboFan 将字节码(Bytecode)生成优化的机器代码(Machine Code)。
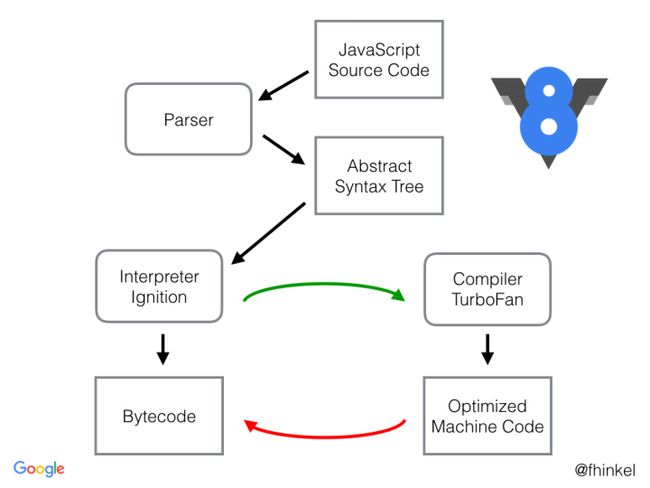
V8 曾经有两个编译器
在 5.9 版本之前,该引擎曾经使用了两个编译器:
full-codegen - 一个简单而快速的编译器,可以生成简单且相对较慢的机器代码。
Crankshaft - 一种更复杂的(即时)优化编译器,可生成高度优化的代码。
V8 引擎还在内部使用多个线程:
- 主线程:获取代码,编译代码然后执行它
- 优化线程:与主线程并行,用于优化代码的生成
- Profiler 线程:它将告诉运行时我们花费大量时间的方法,以便 Crankshaft 可以优化它们
- 其他一些线程来处理垃圾收集器扫描
字节码
字节码是机器代码的抽象。如果字节码采用和物理 CPU 相同的计算模型进行设计,则将字节码编译为机器代码更容易。这就是为什么解释器(interpreter)常常是寄存器或堆栈。 Ignition 是具有累加器的寄存器。

您可以将 V8 的字节码看作是小型的构建块(bytecodes as small building blocks),这些构建块组合在一起构成任何 JavaScript 功能。V8 有数以百计的字节码。比如 Add 或 TypeOf 这样的操作符,或者像 LdaNamedProperty 这样的属性加载符,还有很多类似的字节码。 V8 还有一些非常特殊的字节码,如 CreateObjectLiteral 或 SuspendGenerator。头文件 bytecodes.h(https://github.com/v8/v8/blob/master/src/interpreter/bytecodes.h) 定义了 V8 字节码的完整列表。
在早期的 V8 引擎里,在多数浏览器都是基于字节码的,V8 引擎偏偏跳过这一步,直接将 jS 编译成机器码,之所以这么做,就是节省了时间提高效率,但是后来发现,太占用内存了。最终又退回字节码了,之所以这么做的动机是什么呢?
- 减轻机器码占用的内存空间,即牺牲时间换空间。(主要动机)
- 提高代码的启动速度 对 v8 的代码进行重构。
- 降低 v8 的代码复杂度。
每个字节码指定其输入和输出作为寄存器操作数。Ignition 使用寄存器 r0,r1,r2,… 和累加器寄存器(accumulator register)。几乎所有的字节码都使用累加器寄存器。它像一个常规寄存器,除了字节码没有指定。 例如,Add r1 将寄存器 r1 中的值和累加器中的值进行加法运算。这使得字节码更短,节省内存。
许多字节码以 Lda 或 Sta 开头。Lda 和 Stastands 中的 a 为累加器(accumulator)。例如,LdaSmi [42] 将小整数(Smi)42 加载到累加器寄存器中。Star r0 将当前在累加器中的值存储在寄存器 r0 中。
以现在掌握的基础知识,花点时间来看一个具有实际功能的字节码。
function incrementX(obj) {
return 1 + obj.x;
}
incrementX({ x: 42 }); // V8 的编译器是惰性的,如果一个函数没有运行,V8 将不会解释它
如果要查看 V8 的 JavaScript 字节码,可以使用在命令行参数中添加 --print-bytecode 运行 D8 或 Node.js(8.3 或更高版本)来打印。对于 Chrome,请从命令行启动 Chrome,使用 --js-flags="--print-bytecode",请参考 Run Chromium with flags。
$ node --print-bytecode incrementX.js
...
[generating bytecode for function: incrementX]
Parameter count 2
Frame size 8
12 E> 0x2ddf8802cf6e @ StackCheck
19 S> 0x2ddf8802cf6f @ LdaSmi [1]
0x2ddf8802cf71 @ Star r0
34 E> 0x2ddf8802cf73 @ LdaNamedProperty a0, [0], [4]
28 E> 0x2ddf8802cf77 @ Add r0, [6]
36 S> 0x2ddf8802cf7a @ Return
Constant pool (size = 1)
0x2ddf8802cf21: [FixedArray] in OldSpace
- map = 0x2ddfb2d02309 <Map(HOLEY_ELEMENTS)>
- length: 1 0: 0x2ddf8db91611 <String[1]: x>
Handler Table (size = 16)
我们忽略大部分输出,专注于实际的字节码。
这是每个字节码的意思,每一行:
LdaSmi [1]

Star r0
接下来,Star r0 将当前在累加器中的值 1 存储在寄存器 r0 中。

LdaNamedProperty a0, [0], [4]
LdaNamedProperty 将 a0 的命名属性加载到累加器中。ai 指向 incrementX() 的第 i 个参数。在这个例子中,我们在 a0 上查找一个命名属性,这是 incrementX() 的第一个参数。该属性名由常量 0 确定。LdaNamedProperty 使用 0 在单独的表中查找名称:
- length: 1
0: 0x2ddf8db91611 <String[1]: x>
可以看到,0 映射到了 x。因此这行字节码的意思是加载 obj.x。
那么值为 4 的操作数是干什么的呢? 它是函数 incrementX() 的反馈向量的索引。反馈向量包含用于性能优化的 runtime 信息。
现在寄存器看起来是这样的:

Add r0, [6]
最后一条指令将 r0 加到累加器,结果是 43。 6 是反馈向量的另一个索引。

Return 返回累加器中的值。返回语句是函数 incrementX() 的结束。此时 incrementX() 的调用者可以在累加器中获得值 43,并可以进一步处理此值。
V8 引擎为啥这么快?
由于 JavaScript 弱语言的特性(一个变量可以赋值不同的数据类型),同时很弹性,允许我们在任何时候在对象上新增或是删除属性和方法等, JavaScript 语言非常动态,我们可以想象会大大增加编译引擎的难度,尽管十分困难,但却难不倒 V8 引擎,v8 引擎运用了好几项技术达到加速的目的:
内联(Inlining):
内联特性是一切优化的基础,对于良好的性能至关重要,所谓的内联就是如果某一个函数内部调用其它的函数,编译器直接会将函数中的执行内容,替换函数方法。如下图所示:
如何理解呢?看如下代码
function add(a, b) {
return a + b;
}
function calculateTwoPlusFive() {
var sum;
for (var i = 0; i <= 1000000000; i++) {
sum = add(2 + 5);
}
}
var start = new Date();
calculateTwoPlusFive();
var end = new Date();
var timeTaken = end.valueOf() - start.valueOf();
console.log("Took " + timeTaken + "ms");
由于内联属性特性,在编译前,代码将会被优化成
function add(a, b) {
return a + b;
}
function calculateTwoPlusFive() {
var sum;
for (var i = 0; i <= 1000000000; i++) {
sum = 2 + 5;
}
}
var start = new Date();
calculateTwoPlusFive();
var end = new Date();
var timeTaken = end.valueOf() - start.valueOf();
console.log("Took " + timeTaken + "ms");
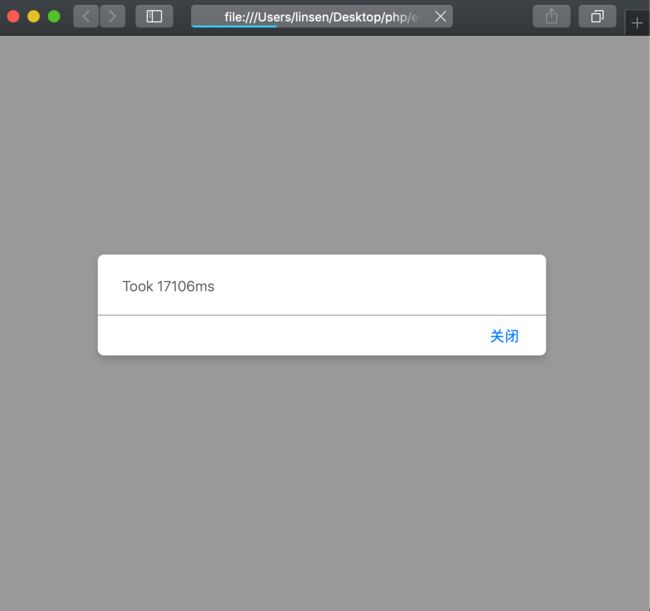
如果没有内联属性的特性,你能想想运行的有多慢吗?把第一段 JS 代码嵌入 HTML 文件里,我们用不同的浏览器打开(硬件环境:i7,16G 内存,mac 系统),用 safari 打开如下图所示,17 秒:
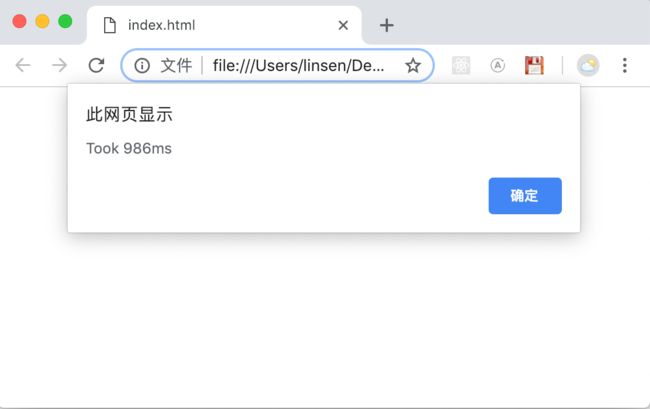
如果用 Chrome 打开,还不到 1 秒,快了 16 秒!
隐藏类(Hidden class):
例如 C++/Java 这种静态类型语言的每一个变量,都有一个唯一确定的类型。因为有类型信息,一个对象包含哪些成员和这些成员在对象中的偏移量等信息,编译阶段就可确定,执行时 CPU 只需要用对象首地址 —— 在 C++中是 this 指针,加上成员在对象内部的偏移量即可访问内部成员。这些访问指令在编译阶段就生成了。
但对于 JavaScript 这种动态语言,变量在运行时可以随时由不同类型的对象赋值,并且对象本身可以随时添加删除成员。访问对象属性需要的信息完全由运行时决定。为了实现按照索引的方式访问成员,V8“悄悄地”给运行中的对象分了类,在这个过程中产生了一种 V8 内部的数据结构,即隐藏类。隐藏类本身是一个对象。
考虑以下代码:
function Point(x, y) {
this.x = x;
this.y = y;
}
var p1 = new Point(1, 2);
如果 new Point(1, 2)被调用,v8 引擎就会创建一个引隐藏的类 C0,如下图所示:
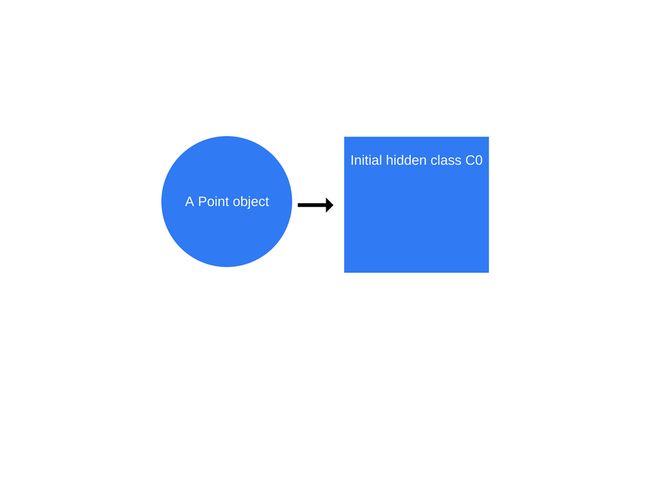
由于 Point 没有定于任何属性,因此C0为空
一旦this.x = x被执行,v8 引擎就会创建一个名为“C1”的第二个隐藏类。基于“c0”,“c1”描述了可以找到属性 X 的内存中的位置(相当指针)。在这种情况下,隐藏类则会从 C0 切换到 C1,如下图所示:

每次向对象添加新的属性时,旧的隐藏类会通过路径转换切换到新的隐藏类。由于转换的重要性,因为引擎允许以相同的方式创建对象来共享隐藏类。如果两个对象共享一个隐藏类的话,并且向两个对象添加相同的属性,转换过程中将确保这两个对象使用相同的隐藏类和附带所有的代码优化。
当执行 this.y = y,将会创建一个 C2 的隐藏类,则隐藏类更改为 C2。
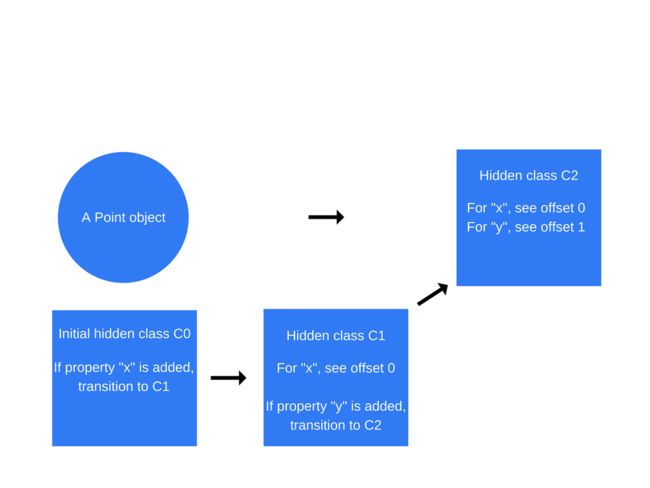
隐藏类的转换的性能,取决于属性添加的顺序,如果添加顺序的不同,效果则不同,如以下代码:
function Point(x, y) {
this.x = x;
this.y = y;
}
var p1 = new Point(1, 2);
p1.a = 5;
p1.b = 6;
var p2 = new Point(3, 4);
p2.b = 7;
p2.a = 8;
你可能以为 P1、p2 使用相同的隐藏类和转换,其实不然。对于 P1 对象而言,隐藏类先 a 再 b,对于 p2 而言,隐藏类则先 b 后 a,最终会产生不同的隐藏类,增加编译的运算开销,这种情况下,应该以相同的顺序动态的修改对象属性,以便可以复用隐藏类。
内联缓存(Inline caching)
- 正常访问对象属性的过程是:首先获取隐藏类的地址,然后根据属性名查找偏移值,然后计算该属性的地址。虽然相比以往在整个执行环境中查找减小了很大的工作量,但依然比较耗时。能不能将之前查询的结果缓存起来,供再次访问呢?当然是可行的,这就是内嵌缓存。
- 内嵌缓存的大致思路就是将初次查找的隐藏类和偏移值保存起来,当下次查找的时候,先比较当前对象是否是之前的隐藏类,如果是的话,直接使用之前的缓存结果,减少再次查找表的时间。当然,如果一个对象有多个属性,那么缓存失误的概率就会提高,因为某个属性的类型变化之后,对象的隐藏类也会变化,就与之前的缓存不一致,需要重新使用以前的方式查找哈希表。
内存管理
内存的管理组要由分配和回收两个部分构成。V8 的内存划分如下:
- Zone:管理小块内存。其先自己申请一块内存,然后管理和分配一些小内存,当一块小内存被分配之后,不能被 Zone 回收,只能一次性回收 Zone 分配的所有小内存。当一个过程需要很多内存,Zone 将需要分配大量的内存,却又不能及时回收,会导致内存不足情况。
- 堆:管理 JavaScript 使用的数据、生成的代码、哈希表等。为方便实现垃圾回收,堆被分为三个部分:
1.年轻分代:为新创建的对象分配内存空间,经常需要进行垃圾回收。为方便年轻分代中的内容回收,可再将年轻分代分为两半,一半用来分配,另一半在回收时负责将之前还需要保留的对象复制过来。
2.年老分代:根据需要将年老的对象、指针、代码等数据保存起来,较少地进行垃圾回收。
3.大对象:为那些需要使用较多内存对象分配内存,当然同样可能包含数据和代码等分配的内存,一个页面只分配一个对象。
垃圾回收
V8 使用了分代和大数据的内存分配,在回收内存时使用精简整理的算法标记未引用的对象,然后消除没有标记的对象,最后整理和压缩那些还未保存的对象,即可完成垃圾回收。
为了控制 GC 成本并使执行更加稳定, V8 使用增量标记, 而不是遍历整个堆,它试图标记每个可能的对象,它只遍历一部分堆,然后恢复正常的代码执行。下一次 GC 将继续从之前的遍历停止的位置开始。这允许在正常执行期间非常短的暂停。如前所述,扫描阶段由单独的线程处理。
优化回退
V8 为了进一步提升 JavaScript 代码的执行效率,编译器直接生成更高效的机器码。程序在运行时,V8 会采集 JavaScript 代码运行数据。当 V8 发现某函数执行频繁(内联函数机制),就将其标记为热点函数。针对热点函数,V8 的策略较为乐观,倾向于认为此函数比较稳定,类型已经确定,于是编译器,生成更高效的机器码。后面的运行中,万一遇到类型变化,V8 采取将 JavaScript 函数回退到优化前的编译成机器字节码。如以下代码:
function add(a, b) {
return a + b;
}
for (var i = 0; i < 10000; ++i) {
add(i, i);
}
add("a", "b"); //千万别这么做!
再来看下面的一个例子:
// 片段 1
var person = {
add: function(a, b) {
return a + b;
}
};
obj.name = "li";
// 片段 2
var person = {
add: function(a, b) {
return a + b;
},
name: "li"
};
以上代码实现的功能相同,都是定义了一个对象,这个对象具有一个属性 name 和一个方法 add()。但使用片段 2 的方式效率更高。片段 1 给对象 obj 添加了一个属性 name,这会造成隐藏类的派生。**给对象动态地添加和删除属性都会派生新的隐藏类。**假如对象的 add 函数已经被优化,生成了更高效的代码,则因为添加或删除属性,这个改变后的对象无法使用优化后的代码。
从例子中我们可以看出
函数内部的参数类型越确定,V8 越能够生成优化后的代码。
结束语
好了,本篇的内容终于完了,说了这么多,你是否真正的理解了,我们如何迎合编译器的嗜好编写更优化的代码呢?
对象属性的顺序:始终以相同的顺序实例化对象属性, 以便可以共享隐藏类和随后优化的代码。
动态属性:在实例化后向对象添加属性将强制隐藏类更改, 并任何为先前隐藏类优化的方法变慢. 所以, 使用在构造函数中分配对象的所有属性来代替。
方法:重复执行相同方法的代码将比只执行一次的代码(由于内联缓存)运行得快。
数组:避免键不是增量数字的稀疏数组. 稀疏数组是一个哈希表. 这种阵列中的元素访问消耗较高. 另外, 尽量避免预分配大型数组, 最好按需分配, 自动增加. 最后, 不要删除数组中的元素, 它使键稀疏。
接下来小编将和大家继续分享作用域的内容,敬请期待…