DARPA TC-engagement5数据集官方工具可视化
目录
- 0. 说在前面
- 1. 相关资料
- 2. 数据集概况
- 3. Transparent Computing (TC) Data Annotation Stack (DAS)
-
- 3.1. 背景
- 3.2. 依赖环境
- 3.3. 文件结构和内容
- 3.4. 运行数据注释框架
- 3.5. 添加数据
- 3.6. 添加新数据
- 3.7. 从压缩文件添加数据
- 3.8. 为已有数据加载注释
- 3.9. Grafana使用指南
- 4. 你可能遇到的一些问题及解决方案
-
- 4.1. elasticsearch启动失败
- 4.2. 导入数据脚本运行报错
-
- 4.2.1 JAVA命令报错
- 4.2.2 JAVA报错
- 4.2.3. log4j报错
0. 说在前面
这篇文章只是在根据官方给的可视化工具和相关文档进行的机械式配置和一些错误排查,可以用来练手顺便感受下ELK技术栈。真正后续做的一些工作在这里DARPA TC-engagement5数据集解析为json格式输出到本地。欢迎大家进一步交流讨论,共同学习进步!
里面提供的可视化工具大致流程如下:
说说我目前的情况。前面大差不差,elasticsearch能看到 json 数据,但是最后一步grafana玩不懂。我找不到增加数据源的入口,或是内置了入口我不知道怎么看。
其实从上面的流程就可以看出来,别的都是开源工具辅助查看,重点就是从日志构建溯源图并以流式传输。elssticsearch是为了存数据,配合grafana为溯源图的节点编辑标签,logstash是为了捕获流式数据。
这里推荐UNICORN,作者开源了数据集和代码。里面包含了四种日志解析器和构建好的溯源图。代码在这里,数据集在这里,我自己写的论文笔记在这里。
如果你还是想走个流程感受一下,建议先看完文章再动手,因为作者的readme有点抽象。
1. 相关资料
对于数据集的介绍不再赘述,参考绿盟的文章:AISecOps:从DARPA TC项目看终端攻防
数据集地址:engagement5(是谷歌云盘,需要科学上网),或者github,里面有下载脚本(我没试过)。
如果下载存在问题,我推荐分批下载。具体来说,就是每次选中几十个压缩包(我是20个一批)作为一批下载,谷歌云盘会自动进一步压缩之后开始下载。下载下来之后再解压缩就ok了。千万别贪多,不然会出现漏包、网络原因中断等情况。
2. 数据集概况

engagement5 包含四个文件夹和三个文件,其具体内容如下:
| 文件 | 内容 |
|---|---|
| Data | 原始数据(已压缩),包含 cadets、clearscope、fivedirections、marple、strarc、theia、trace 五个部分共超300G的数据,每个部分代表了一种采集系统捕获到的审计日志 |
| Ground_Truth | TA5.1的攻击报告,详细描述了每次攻击的时间目标过程等 |
| Schema | 一个溯源图构建工具CDM(已停止更新) |
| Tools | 可视化工具ELG(elasticsearch+logstash+grafana),docker环境。内含数据解压工具importers,具体使用方法见根目录下的 README.md |
| Engagement-5-Event-Log.md | 整个过程的日志,按照日期为单位,记录了每天发生的事,如收集系统的崩溃和修复 |
| README.md | 包含了整个数据集的基本信息和可视化方法,接下来会详细介绍 |
| README.pdf | README的 pdf 版,内容同上 |
3. Transparent Computing (TC) Data Annotation Stack (DAS)
3.1. 背景
TC DAS由 “ELG” 框架实现(基于ELK技术栈),包含开源工具Elasticsearch、Logstsash和Grafana。这些工具结合在一起提供了一个完全集成的平台,用于处理大量数据,为这些数据添加上下文并提供了一种在数据来源的上下文中查看数据的方式。
3.2. 依赖环境
Docker Engine version 17.05+Docker Compose version 1.12.0+
3.3. 文件结构和内容
docker-compose.yml:一个总的配置文件,用于设置初始配置、启动、管理 DASgrafana_var_data: 用于 Docker 中的Grafana容器挂载到本地的存储路径。会保存Grafana接口使用和存储的所有数据。elasticsearch:一个目录,包含 Elasticsearch 的配置和 Docker 挂载到本地的数据存储路径。logstash:一个目录,包含 logstash 服务的基础配置以及传送数据到 Elasticsearch 的管道设置。logstash/config/logstash.yml: logstash 的基础配置文件logstash/pipeline/logstash.conf:logstash输入设置的配置文件,允许CDM数据被DAS使用。
env.grafana:grafana在运行时使用的环境变量
3.4. 运行数据注释框架
在包含docker-compose.yml的目录下运行命令
docker-compose up -d
启动并运行后,在浏览器中访问[host]:3000以查看数据可视化。如果存在运行异常,要检查这三个服务中任何一个的启动状态,可以使用服务名称运行docker-logs命令查看单个容器的运行日志,使用 -ft 可以跟踪这些服务的日志。Grafana的用户名和密码都是darpa。
3.5. 添加数据
该工具预装了来自三次主机攻击的数据。此注释数据旨在在添加自己的注释数据或导入其他注释数据之前演示此平台的功能。
3.6. 添加新数据
导入新数据是使用 Logstash 的输入插件功能实现的。Logstash提供的导入功能允许使用几乎任何格式的事件数据,并将其转换为存储在 Elasticsearch 中。我们已经预先配置了 Logstash ,以接收来自 log4j 的事件数据作为输出,同时也支持从文件中读取。
3.7. 从压缩文件添加数据
这个数据集的压缩数据下载下来是以.bin.gz结尾的,例如ta1-cadets-1-e5-official-2.bin.1.gz。
- 找到压缩文件
.bin.gz的目录 - 使用命令
./import.sh [directory] [avro file] [host] [port] -v启动/imports/from_file/目录下的import.sh文件。各参数含义如下[directory]:压缩文件的路径[avro file]:AVRO 模式的启用,用于将序列化的数据反序列化为适当的JSON格式的。这个功能由TCCDMDatum.avsc提供的,位于与脚本相同的目录中。[host]:部署 DAS 容器的主机地址[port]:Logstash 接收数据的端口,默认4721
比如:
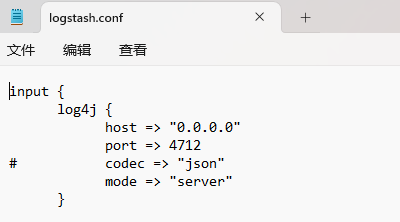
./import.sh /.../tc_data_delivery/ /.../TCCDMDatum.avsc 0.0.0.0 4712 -v
这里的[port]均应与logstash/pipeline/logstash.conf中的一致,才能确保Logstash正常接收到数据。0.0.0.0表示本服务器,如果脚本运行的机器就是部署DAS的机器,可以两处都不改。但是如果是自己电脑上解压到服务器,命令里的[host]应该为服务器IP,logstash.conf中保持不变。
3.8. 为已有数据加载注释
(这个脚本谷歌云盘已经没有了,不知道弃用了还是丢失了)
如果你当前存的是纯数据,你希望同步别人对于数据的标注,可以使用TC DAS的预先配置的API密钥从./importers/annotations/运行注释导入脚本程序来实现(需要python3):
./import_annotations.py -ga [host-1]:3000 -gb [host-2]:3000 -bk eyJrIjoiU0Z4bWdTNjBTaDFHY3oxU21CZFVoaHRWSmF6RThQTG4iLCJuIjoiS0VZIiwiaWQiOjF9 -ak eyJrIjoiU0Z4bWdTNjBTaDFHY3oxU21CZFVoaHRWSmF6RThQTG4iLCJuIjoiS0VZIiwiaWQiOjF9 --verbose
3.9. Grafana使用指南
创建注释:“Add Annotations” 面板的设计目的是便于根据Ground Truth文件输入为数据添加注释。通过浏览上面的图表,可以为屏幕上的条目添加注释。审阅注释:“Review Annotations”仪表板旨在允许用户审阅现有注释,并尝试从所提供的数据中得出有意义的结论。详细事件查看器:"Timeslice Viewer"面板显示在特定时间戳发生的所有事件的详细JSON数据。
4. 你可能遇到的一些问题及解决方案
4.1. elasticsearch启动失败
执行docker-compose up -d后,可以使用docker ps或docker stats,查看容器运行情况。如果发现意外关闭,可以使用docker logs +容器名查看运行日志。如果elasticsearch出现如下错误:\
{"type": "server", "timestamp": "2023-04-03T13:13:17,201+0000", "level": "WARN", "component": "o.e.b.ElasticsearchUncaughtExceptionHandler", "cluster.name": "docker-cluster", "node.name": "86d7fb89ee33", "message": "uncaught exception in thread [main]" , "stacktrace": ["org.elasticsearch.bootstrap.StartupException: ElasticsearchException[failed to bind service]; nested: AccessDeniedException[/usr/share/elasticsearch/data/nodes];",
是由于你文件路径没有给写入权限,而配置文件里挂载了elasticsearch的写入目录,所以需要给整个目录给权限。
例如,我的所有文件都位于app/TC_Data_Visualization_Tool下,则需要运行如下命令(-R表示所有子目录也给777权限):
chmod -R 777 /app/TC_Data_Visualization_Tool
4.2. 导入数据脚本运行报错
4.2.1 JAVA命令报错
导入数据的脚本import.sh中使用了java命令,如果你没有安装java环境,会出现如下报错:
./import.sh: 行 36: java: 未找到命令
此时随便运行一个java命令,会有如下提示:
root@ycl-ubuntu:/app/Tools/TC_Data_Visualization_Tool/importers/from_file# java -version
找不到命令 “java”,但可以通过以下软件包安装它:
apt install default-jre # version 2:1.11-72build2, or
apt install openjdk-11-jre-headless # version 11.0.18+10-0ubuntu1~22.04
apt install openjdk-17-jre-headless # version 17.0.6+10-0ubuntu1~22.04
apt install openjdk-18-jre-headless # version 18.0.2+9-2~22.04
apt install openjdk-19-jre-headless # version 19.0.2+7-0ubuntu3~22.04
apt install openjdk-8-jre-headless # version 8u362-ga-0ubuntu1~22.04
根据提示的命令随便选一个安装,我安装的是第二个。
4.2.2 JAVA报错
如果遇到如下报错:
Exception in thread "main" java.lang.NumberFormatException: For input string: "/app/TC_Data_Visualization_Tool/importers/from_file/TCCDMDatum.avsc" at java.base/java.lang.NumberFormatException.forInputString(NumberFormatException.java:65) at java.base/java.lang.Integer.parseInt(Integer.java:638) at java.base/java.lang.Integer.parseInt(Integer.java:770) at main.java.com.bbn.tc.DASImporter.handleArguments(DASImporter.java:137) at main.java.com.bbn.tc.DASImporter.main(DASImporter.java:44)
是由于文件名导致,数据集的路径不能有中文,最好空格也别要吧。改完路径之后有遇到如下错误:
Exception in thread "main" java.lang.NumberFormatException: For input string: "0.0.0.0" at java.base/java.lang.NumberFormatException.forInputString(NumberFormatException.java:65) at java.base/java.lang.Integer.parseInt(Integer.java:652) at java.base/java.lang.Integer.parseInt(Integer.java:770) at main.java.com.bbn.tc.DASImporter.handleArguments(DASImporter.java:137) at main.java.com.bbn.tc.DASImporter.main(DASImporter.java:44)
这个报错是由于将string的IP转换成int时遇到了错误,但是换成别的ip也报错。但是为什么会把IP转成INT呢?
所以我就解压了tc-das-importer-1.0-SNAPSHOT-jar-with-dependencies.jar这个java包,并反编译main.class了,定位到出错的位置如下:

这里接收了四个参数,分别是输入的文件路径、解压工具TCCDMDatum.avsc的路径、目的IP和目的端口。很明显这里的代码是要将端口转换成INT型,但是带有分隔符的IP被转换了,所以报错不是数字。那就是参数顺序出错了。因此我们再打开impost.sh看看,发现这个文件主要也是在接收参数,然后下面有这么一行命令:

这其实就是调用java包的命令,但是仔细分析可以发现,传递的参数顺序和java文件内部的处理顺序不一样。那是不是可以单独拎出来放外面执行呢?答案是肯定的。我们把这个命令复制出来,参数按照java里面的顺序给,就能正常运行了。
java -Dlog4j.debug=true -cp .:tc-das-importer-1.0-SNAPSHOT-jar-with-dependencies.jar main.java.com.bbn.tc.DASImporter /media/ycl/MyDisk/DarpaTC/Data/cadets/ /app/TC_Data_Visualization_Tool/importers/from_file/TCCDMDatum.avsc 127.0.0.1 4712 -v
这个解压的增加率很高,一个两百多兆的压缩包解压解析之后能有3-6G的json数据,所以存在elasticsearch的话对系统盘的空间要求很高。
4.2.3. log4j报错
INO DASImporter: Streaming records... log4j:WARN Detected problem with connection: java.net.SocketException: 断开的管道 (Write failed)
socket连接失败,是由于4712端口没有开放或是logstash没能成功启动导致的,由于系统差异方法不同,就不赘述了,最好把docker-compose.yml里面提到的端口都打开。