NLP——机器翻译中的Transformer
文章目录
-
-
- 框架
- 简介
- Transformer结构
- Encoder
- Decoder
- Scaled Dot-Product Attention
- Multi-Head Attention
- Layer Normalization
- Mask
- Positional Embedding
- Position-wise Feed-Forward Network
- Transformer优点
-
框架

简介
Transformer就是一个升级版的Seq2Seq,也是由Encoder和Decoder组成。Transformer抛弃了以往深度学习任 务使用的CNN和RNN,整个网络结构完全是由Attention机制组成,更准确地说是由Self-Attention和Feed Forward Neural Network组成。由于Transformer的Attention(Self-Attention机制)将序列中的任意两个位置之间的距离缩小为一个常量,所以和RNN顺序结构相比具有更好的并行性,更符合现有的GPU框架,和CNN相比,具有直接的长距离依赖。Transformer模型被广泛应用于NLP领域,例如机器翻译,问答系统,文本摘要以及语音识别等。

Transformer结构
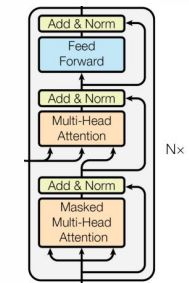
和经典的Seq2Seq模型一样,Transformer模型也采用了Encoder-Decoder结构。框架图的左半边用Nx框出来 的,就代表一层Encoder,Transformer一共有6层这样的结构。右半边用Nx框出来的则代表一层Decoder,同样也有6层。输入序列首先会转换为词嵌入向量,再与位置编码向量相加后可作为Multi-Head Attention模块的输入, 该模块的输出再与输入相加后将投入层级归一化函数,得出的输出再馈送到全连接层后可得出编码器模块的输出。这样相同的6个编码器模块可构成整个编码器架构。解码模块首先同样构建一个自注意力模块,然后再结合编码器的输出实现Multi-Head Attention,最后送入全连接网络并输出预测词概率。
Encoder
Transformer的Encoder由6层相同的层组成,每一层分别由两部分组成:
• 第一部分是multi-head self-attention
• 第二部分是position-wise feed-forward network,是一个全连接层 两个部分,都有一个残差连接(residual connection),然后接一个Layer Normalization

Decoder
Transformer的Decoder也是由6层相同的层组成,每一层分别由三部分组成:
• 第一部分是multi-head self-attention
• 第二部分是multi-head context-attention
• 第三部分是position-wise feed-forward network,是一个全连接层
和Encoder一样,上面三个部分,都有一个残差连接(residual connection),然后接一个Layer Normalization。 和self-attention不同的context-attention,其实就是普通的attention(Encoder和Decoder之间)。
Scaled Dot-Product Attention的结构图如下所示。 首先说下Q、K、V分别代表什么:
1)在Encoder的Self-Attention中,Q、K、V都来自同一个地方,它们是上一层Encoder的输 出。对于第一层Encoder,它们就是word embedding和positional encoding相加得到的输入。
2)在Decoder的Self-Attention中,Q、K、V也是来自于同一地方,它们是上一层Decoder的 输出。对于第一层Decoder,同样也是word embedding和positional encoding相加得到的输 入。但是对于decoder,我们不希望它能获得下一个time step(即将来的信息,不想让它 看到它要预测的信息),因此我们需要进行sequence masking。
3)在Encoder-Decoder attention中,Q来自于Decoder的上一层的输出,K和V来自于Encoder 的输出,K和V是一样的。
4)Q、K、V的维度都是一样的,分别用dQ、dK、dV来表示。

Scaled Dot-Product Attention
Step1:输入X,通过3个线性转换把X转换为Q、K、V。如下图,两个单词Thinking,Machines通过嵌入变换会得到两个[1x4]的向量X1,X2。分别与Wq,Wk,Wv三个[4x3]矩阵做点乘得到6个[1x3]向量{q1,q2},{k1,k2},{v1,v2}

Step2:向量{q1,k1}做点乘得到得分Score 112,{q1,k2}做点乘得到得分Score 96
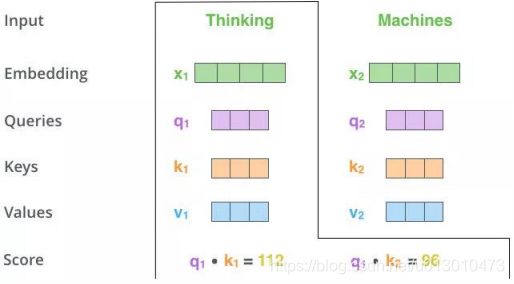
Step3:对该得分就行规范,除以8.这样做的目的是为了使得梯度更稳定。之后对得分[14,12]做softmax得到比例[0.88,0.12]

Step4:用得分比例[0.88,0.12]乘以[v1,v2]值(Values)得到一个加权后的值。将这些值加起来得到z1。
Ps.用Q,K去计算一个thinking与thinking,machines的权重,用权重乘以thinking,machines的V得到加权后的thinking,machines的V,最后求和得到针对各个单词的输入Z。

Multi-Head Attention
理解了Scaled Dot-Product Attention,Multi-Head Attention也很容易理解。Transformer论 文提到将Q、K、V通过一个线性映射之后,分成h份,对每一份进行Scaled Dot-Product Attention效果更好。然后,把各个部分的结果合并起来,再次经过线性映射,得到最终的 输出。这就是所谓的Multi-Head Attention。这里的超参数h就是heads的数量,默认是8。 上面说的分成h份是在dQ、dK和dV的维度上进行切分。因此进入到Scaled Dot-Product Attention的dK实际上等于DK/h。 Multi-head attention的公式如下:
![]()
其中,
![]()
dmodel=512,h=8,所以在Scaled Dot-Product Attention里面的
![]()
所谓Multi-Head,就是多做几次同样的事情,同时参数不共享,然后把结果拼接(类似于 卷积神经网络中用不同的卷积核来提取特征)。

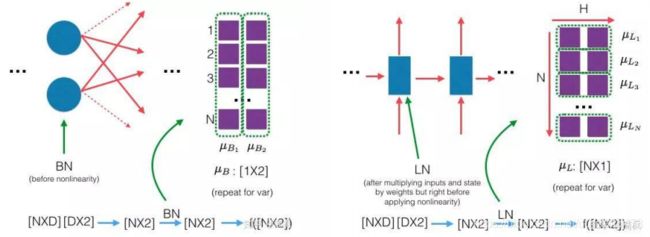
Layer Normalization
Normalization有很多种,但是它们都有一个共同的目的,那就是把输入转化成均值为0 方差为1的数据。在把数据送入激活函数之前进行Normalization,可以避免输入数据落在激 活函数的饱和区。Layer Normalization和Batch Normalization的区别如下图:
Batch Normalization的具体做法就是对每一小批数据,在批这个方向上做归一化,公式如下:
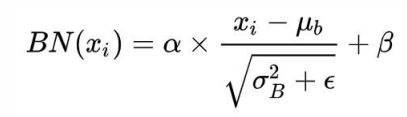
Layer Normalization是在每一个样本上计算均值和方差,而不是Batch Normalization那种在批方向计算均值和方差,公式如下:
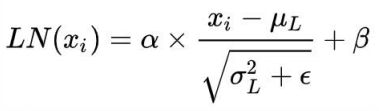
Mask
Mask表示掩码,它对某些值进行掩盖,使其在参数更新时不产生效果。Transformer模型里 面涉及两种Mask,分别是padding mask和sequence mask,其中padding mask在所有的Scaled Dot- Product Attention里面都需要用到,而sequence mask只有在Decoder的Self-Attention里面用到。 Padding Mask:因为每个批次输入序列长度是不一样的,所以我们需要对输入序列进行补齐。具 体来说,就是在给较短的序列后面填充0。由于这些填充的位置其实是没什么意义的,所以 Attention机制不应该把注意力放在这些位置上,需要进行一些处理。具体做法就是把这些位置 的值加上一个非常大的负数(负无穷),这样的话,经过softmax,这些位置的概率就会接近0。 Sequence Mask:为了使得Decoder不能看到未来的信息,也就是对于一个序列,在t时刻,解码 器输出应该只能依赖于t时刻之前的输出,而不能依赖t之后的输出,因此就需要通过Sequence Mask把t之后的信息给隐藏起来。具体做法是产生一个上三角矩阵,上三角的值全为0,下三角 的值全为1,对角线也是1。把这个矩阵作用在每一个序列上,就可以达到目的。
Positional Embedding
到目前为止,Transformer结构还没有提取序列顺序的信息,这个信息对于序列而言非常重要,如果缺失 了这个信息,可能我们的结果就是:所有的词语都对了,但是无法组成有意义的语句(此时的Transformer就 相当于一个词袋模型)。为了解决这个问题,Transformer的作者使用了Positional Embedding:对序列中的词 语出现的位置进行编码。 在实现的时候使用正余弦函数。公式如下:
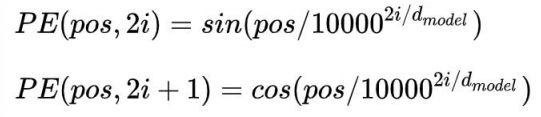
其中,pos是指词语在序列中的位置。可以看出,在偶数位置,使用正弦编码,在奇数位置,使用余弦 编码。从编码公式中可以看出,给定词语的pos,我们可以把它编码成一个dmodel的向量。也就是说,位置 编码的每一个维度对应正弦曲线,波长构成了从2π到10000X2π的等比数列。
上面的位置编码是绝对位置编码。但是词语的相对位置也非常重要。这就是论文为什么使用三角函数的 原因。正弦函数能够表达相对位置信息,主要数据依据是以下两个公式:
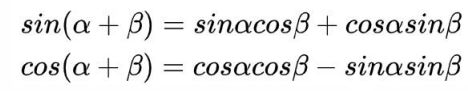
上面的公式说明,对于词汇之间的位置偏移k,PE(pos+k)可以表示成PE(pos)和PE(k)组合的形式, 相当于有了可以表达相对位置的能力。
Position-wise Feed-Forward Network
这是一个全连接网络,包含两个线性变换和一个非线性函数(实际上就是ReLU)。公式如下:

这个线性变换在不同的位置都表现地一样,并且在不同的层之间使用不同的参数。具体实现上用到了两 个一维卷积。其实FFN很简单,就是对一个输入序列(x0,x1,x2,……,xT),对每个xi都进行一次channel的 重组:512——>2048——>512,可以理解为对每个xi进行两次线性映射,也可以理解为对整个序列做一个 1*1的卷积。
Transformer优点
1.并行计算,提高训练速度
Transformer用attention代替了原本的RNN;而RNN在训练的时候,当前step的计算要依赖于上一 个step的hidden state的,也就是说这是一个sequential procedure,每次计算都要等之前的计算完成才能展开。而Transformer不用RNN,所有的计算都可以并行进行,从而提高训练速度。
2.建立直接的长距离依赖
原本的RNN,如果第一帧要和第十帧建立依赖,那么第一帧的数据要依次经过第二三四五…九帧传给第十帧,进而产生二者的计算。而在这个传递的过程中,可能第一帧的数据已经产生了 biased,因此这个交互的速度和准确性都没有保障。而在Transformer中,由于有self attention的存在,任意两帧之间都有直接的交互,从而建立了直接的依赖,无论二者距离多远。
3.捕捉层级化信息
构建多层神经网络
4.引入指代信息等丰富上下文信息
Self-attention,Multi-head attention