AIGC:【LLM(五)】——Faiss:高效的大规模相似度检索库
文章目录
-
- 一.简介
-
- 1.1 什么是Faiss
- 1.2 Faiss的安装
- 二.Faiss检索流程
-
- 2.1 构建向量库
- 2.2 构建索引
- 2.3 top-k检索
- 三.Faiss构建索引的多种方式
-
- 3.1 Flat :暴力检索
- 3.2 IVFx Flat :倒排暴力检索
- 3.3 IVFxPQy 倒排乘积量化
- 3.4 LSH 局部敏感哈希
- 3.5 HNSWx
一.简介
1.1 什么是Faiss
Faiss的全称是Facebook AI Similarity Search,是Facebook的AI团队针对大规模相似度检索问题开发的一个工具,使用C++编写,有python接口,对10亿量级的索引可以做到毫秒级检索的性能。
简单来说,Faiss的工作就是把我们自己的候选向量集封装成一个index数据库,它可以加速我们检索相似向量top-K的过程,其中有些索引还支持GPU构建。
1.2 Faiss的安装
## cpu版
$ conda install -c pytorch faiss-cpu
## gpu版
$ conda install -c pytorch faiss-gpu
二.Faiss检索流程
2.1 构建向量库
这一部分就是将我们已有的数据转成向量库。
import numpy as np
d = 64 # 向量维度
nb = 100000 # index向量库的数据量
nq = 10000 # 待检索query的数目
np.random.seed(1234)
xb = np.random.random((nb, d)).astype('float32')
xb[:, 0] += np.arange(nb) / 1000. # index向量库的向量
xq = np.random.random((nq, d)).astype('float32')
xq[:, 0] += np.arange(nq) / 1000. # 待检索的query向量
2.2 构建索引
用faiss 构建index,并将向量添加到index中。这里我们选用暴力检索的方法FlatL2,L2代表构建的index采用的相似度度量方法为L2范数,即欧氏距离。
import faiss
index = faiss.IndexFlatL2(d)
print(index.is_trained) # 输出为True,代表该类index不需要训练,只需要add向量进去即可
index.add(xb) # 将向量库中的向量加入到index中
print(index.ntotal) # 输出index中包含的向量总数,为100000
2.3 top-k检索
检索与query最相似的top-k。
k = 4 # topK的K值
D, I = index.search(xq, k)# xq为待检索向量,返回的I为每个待检索query最相似TopK的索引list,D为其对应的距离
print(I[:5])
print(D[-5:])
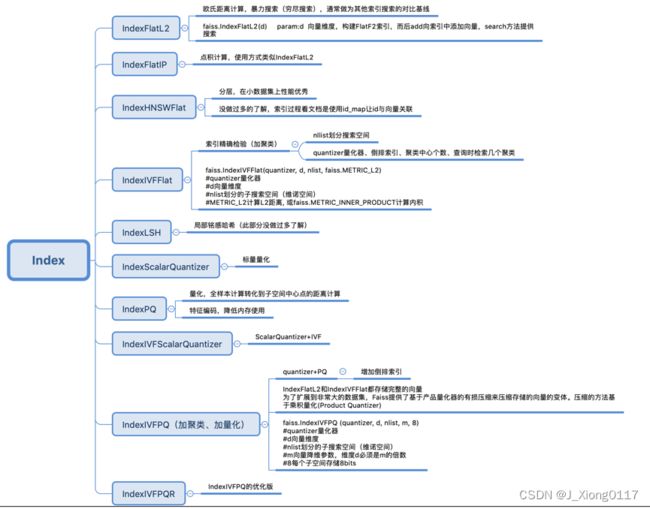
三.Faiss构建索引的多种方式
构建index方法和传参方法可以为:
dim, measure = 64, faiss.METRIC_L2
param = 'Flat'
index = faiss.index_factory(dim, param, measure)
- dim为向量维数
- 最重要的是param参数,它是传入index的参数,代表需要构建什么类型的索引;
- measure为度量方法,目前支持两种,欧氏距离和inner product,即内积。因此,要计算余弦相似度,只需要将vecs归一化后,使用内积度量即可。
此外,Faiss官方支持八种度量方式,分别是:
1)METRIC_INNER_PRODUCT(内积)
2)METRIC_L1(曼哈顿距离)
3)METRIC_L2(欧氏距离)
4)METRIC_Linf(无穷范数)
5)METRIC_Lp(p范数)
6)METRIC_BrayCurtis(BC相异度)
7)METRIC_Canberra(兰氏距离/堪培拉距离)
8)METRIC_JensenShannon(JS散度)
3.1 Flat :暴力检索
- 优点:该方法是Faiss所有index中最准确的,召回率最高的方法,没有之一;
- 缺点:速度慢,占内存大。
- 使用情况:向量候选集很少,在50万以内,并且内存不紧张。
- Ps:虽然都是暴力检索,faiss的暴力检索速度比一般程序猿自己写的暴力检索要快上不少,所以并不代表其无用武之地,建议有暴力检索需求的同学还是用下faiss。
- 构建方法:
dim, measure = 64, faiss.METRIC_L2
param = 'Flat'
index = faiss.index_factory(dim, param, measure)
index.is_trained # 输出为True
index.add(xb) # 向index中添加向量
3.2 IVFx Flat :倒排暴力检索
- 优点:IVF主要利用倒排的思想,在文档检索场景下的倒排技术是指,一个kw后面挂上很多个包含该词的doc,由于kw数量远远小于doc,因此会大大减少了检索的时间。在向量中如何使用倒排呢?可以拿出每个聚类中心下的向量ID,每个中心ID后面挂上一堆非中心向量,每次查询向量的时候找到最近的几个中心ID,分别搜索这几个中心下的非中心向量。通过减小搜索范围,提升搜索效率。
- 缺点:速度也还不是很快。
- 使用情况:相比Flat会大大增加检索的速度,建议百万级别向量可以使用。
- 参数:IVFx中的x是k-means聚类中心的个数
- 构建方法:
dim, measure = 64, faiss.METRIC_L2
param = 'IVF100,Flat' # 代表k-means聚类中心为100,
index = faiss.index_factory(dim, param, measure)
print(index.is_trained) # 此时输出为False,因为倒排索引需要训练k-means,
index.train(xb) # 因此需要先训练index,再add向量
index.add(xb)
3.3 IVFxPQy 倒排乘积量化
- 优点:工业界大量使用此方法,各项指标都均可以接受,利用乘积量化的方法,改进了IVF的k-means,将一个向量的维度切成x段,每段分别进行k-means再检索。
- 缺点:集百家之长,自然也集百家之短
- 使用情况:一般来说,各方面没啥特殊的极端要求的话,最推荐使用该方法!
- 参数:IVFx,PQy,其中的x和y同上
- 构建方法:
dim, measure = 64, faiss.METRIC_L2
param = 'IVF100,PQ16'
index = faiss.index_factory(dim, param, measure)
print(index.is_trained) # 此时输出为False,因为倒排索引需要训练k-means,
index.train(xb) # 因此需要先训练index,再add向量 index.add(xb)
index.add(xb)
3.4 LSH 局部敏感哈希
- 原理:哈希对大家再熟悉不过,向量也可以采用哈希来加速查找,我们这里说的哈希指的是局部敏感哈希(Locality Sensitive Hashing,LSH),不同于传统哈希尽量不产生碰撞,局部敏感哈希依赖碰撞来查找近邻。高维空间的两点若距离很近,那么设计一种哈希函数对这两点进行哈希计算后分桶,使得他们哈希分桶值有很大的概率是一样的,若两点之间的距离较远,则他们哈希分桶值相同的概率会很小。
- 优点:训练非常快,支持分批导入,index占内存很小,检索也比较快
- 缺点:召回率非常拉垮。
- 使用情况:候选向量库非常大,离线检索,内存资源比较稀缺的情况
- 构建方法:
dim, measure = 64, faiss.METRIC_L2
param = 'LSH'
index = faiss.index_factory(dim, param, measure)
print(index.is_trained) # 此时输出为True
index.train(xb)
index.add(xb)
3.5 HNSWx
- 优点:该方法为基于图检索的改进方法,检索速度极快,10亿级别秒出检索结果,而且召回率几乎可以媲美Flat,最高能达到惊人的97%。检索的时间复杂度为loglogn,几乎可以无视候选向量的量级了。并且支持分批导入,极其适合线上任务,毫秒级别体验。
- 缺点:构建索引极慢,占用内存极大(是Faiss中最大的,大于原向量占用的内存大小)
- 参数:HNSWx中的x为构建图时每个点最多连接多少个节点,x越大,构图越复杂,查询越精确,当然构建index时间也就越慢,x取4~64中的任何一个整数。
- 使用情况:不在乎内存,并且有充裕的时间来构建index
- 构建方法:
dim, measure = 64, faiss.METRIC_L2
param = 'HNSW64'
index = faiss.index_factory(dim, param, measure)
print(index.is_trained) # 此时输出为True
index.add(xb)