新冠时空分析——Global evidence of expressed sentiment alterations during the COVID-19 pandemic
Title: Global evidence of expressed sentiment alterations during the COVID-19 pandemic
新冠病毒大流行期间情绪表达变化的全球证据
Abstract: The COVID-19 pandemic has created unprecedented burdens on people’s physical health and subjective well-being. While countries worldwide have developed platforms to track the evolution of COVID-19 infections and deaths, frequent global measurements of affective states to gauge the emotional impacts of pandemic and related policy interventions remain scarce. Using 654 million geotagged social media posts in over 100 countries, covering 74% of world population, coupled with state-of-the-art natural language processing techniques, we develop a global dataset of expressed sentiment indices to track national- and subnational-level affective states on a daily basis. We present two motivating applications using data from the first wave of COVID-19 (from 1 January to 31 May 2020). First, using regression discontinuity design, we provide consistent evidence that COVID-19 outbreaks caused steep declines in expressed sentiment globally, followed by asymmetric, slower recoveries. Second, applying synthetic control methods, we find moderate to no effects of lockdown policies on expressed sentiment, with large heterogeneity across countries. This study shows how social media data, when coupled with machine learning techniques, can provide real-time measurements of affective states.
新冠大流行给人们的身体健康和主观幸福带来了前所未有的负担。虽然全世界各国都开发了跟踪新冠病感染和死亡演化的平台,但全球经常对情感状态进行测量,以衡量大流行和相关政策干预的情感影响仍然很少。我们使用100多个国家的6.54亿个地理标记社交媒体帖子,覆盖全球74%的人口,再加上最先进的自然语言处理技术,开发了一个全球情感表达指数数据集,用于每日跟踪国家和国家以下各级的情感状态。我们利用2019冠状病毒疾病第一波(2020年1月1日至5月31日)的数据,提出了两个激励性应用。首先,使用回归不连续设计,我们提供了一致的证据,证明2019冠状病毒疾病的爆发导致全球表达的情绪急剧下降,然后是不对称的缓慢恢复。其次,运用综合控制方法,我们发现封锁政策对表达的情绪有中度或无影响,各国之间存在很大的异质性。这项研究表明,社交媒体数据与机器学习技术相结合,可以提供情感状态的实时测量。
Here we build a global dataset that tracks expressed sentiment at the national and subnational (state/province) levels with high temporal and spatial granularity using anonymized and aggregated data from the two largest social media microblogging platforms (Twitter and Weibo (the Chinese equivalent of Twitter)). The data contain more than 600 million geotagged social media posts on all topics published by 10.56 million individuals during the first wave of the COVID-19 pandemic (from 1 January to 31 May 2020) (Fig. 1). Since the sample of COVID-19-related discussions might not be a good representation of the affective state of the general population and could be polluted by political campaigns, we exclude tweets directly related to COVID-19 when building out the main sentiment indices. We then apply the state-of-the-art Bidirectional Encoder Representations from Transformers (BERT) NLP technique to compute daily sentiment measures in over 100 countries standardized across 65 languages (Methods). Unlike dictionary-based sentiment analysis such as Linguistic Inquiry and Word Count (LIWC)26, deep-learning-based BERT algorithms allow word representations to be enriched with contextual information and enable multilingual computations.
在这里,我们构建了一个全球数据集,利用来自两大社交媒体微博平台(推特和微博(中国推特的等价物))的匿名和聚合数据,跟踪国家和国家以下各级(州/省)表达的情感,具有高时间和空间粒度。这些数据包含超过6亿条带有地理标签的社交媒体帖子,涉及1056万人在新冠肺炎第一波大流行期间(2020年1月1日至5月31日)发布的所有主题(图1)。由于与新冠肺炎相关的讨论样本可能无法很好地代表普通人群的情感状态,并且可能会受到政治运动的污染,因此在构建主要情绪指数时,我们排除了与新冠肺炎直接相关的推文。然后,我们应用来自Transformers(BERT) NLP技术的最先进的双向编码器表示法来计算100多个国家的日常情绪测量,这些国家标准化了65种语言(方法)。与基于词典的情感分析(如语言查询和字数统计(LIWC)26)不同,基于深度学习的BERT算法允许用上下文信息丰富单词表示,并支持多语言计算。
On the basis of our measures of expressed sentiment and under the assumption that the existing evidence on the correlation between sentiment and affective well-being is valid, we conduct two inter-related empirical exercises to evaluate the global affective impacts of the COVID-19 pandemic and policy responses. The first exercise estimates the overall expressed sentiment alterations associated with COVID-19. We employ reduced-form econometric methods to measure the sentiment drops related to the advent of COVID-19 human to-human transmission and estimate the recovery time needed for sentiment to return to the baseline levels. Our second exercise applies synthetic control methods (SCM) to explore how social-media-based sentiment measures can be used by countries and international organizations to evaluate alterations in affective states after policy interventions or events, using lockdown policies as an example. To facilitate comparisons across countries, our estimates of sentiment alteration are all measured in the unit of a country’s own magnitude of sentiment variation (that is, the standard deviation of sentiment time series before COVID-19). We describe our approach in more detail in the Methods.
根据我们对情绪表达的测量,并假设情绪与情感幸福感之间的相关性的现有证据有效,我们进行了两次相互关联的实证研究,以评估新冠大流行的全球影响和政策应对。第一项研究估计了与新冠疫情相关的总体情绪变化。我们采用简化形式的经济计量方法方法来衡量与新冠疫情人与人传播相关的情绪下降,并估计情绪恢复到基线水平所需的恢复时间。我们的第二个练习应用综合控制方法(SCM),以锁定政策为例,探索国家和国际组织如何使用基于社交媒体的情绪测量来评估政策干预或事件后情感状态的变化。为了便于各国之间的比较,我们对情绪变化的估计都是以一个国家自己的情绪变化幅度为单位来衡量的(即,新冠疫情之前情绪时间序列的标准偏差)。我们在方法中更详细地描述了我们的方法。
Methods
Data.
Social media data.
We collected social media data from two large microblogging platforms, Twitter and Weibo (the Chinese equivalent of Twitter). The data cover the fve months from 1 January 2020 (when COVID-19 spread was essentially restricted to China’s Wuhan region) to 31 May 2020 (when most countries had recovered from their first COVID-19 wave). Only geolocated social media posts, for which users consented to share their location information, are of interest to our analysis. In the study period, 654 million geotagged Twitter and Weibo posts were collected globally (Fig. 1a).
Twitter is a global platform where users share content, or ‘tweets’, with their followers. As of 2019, Twitter had 330 million monthly active users. Users can give consent to share their location information by enabling background GPS collection or by tagging a location in their tweet. These geolocated tweets are encoded with latitude and longitude coordinates. We employed reverse-geocoding techniques to extract country information from geolocations. Twitter changed its geotagging approach in 2019 to enhance privacy protection. However, because our analysis is conducted at the national or subnational level, this change in approach does not affect the state/country assignment of the individual. As Twitter’s counterpart in China, Weibo (Sina microblog) is one of the top social networking platforms, with 462 million monthly active users in 2020. The geotagged Weibo posts are a subsample of all Weibo posts for which users consented to share their location information. This location information is based on the user’s exact latitude and longitude when releasing the Weibo post from a smartphone or a computer. We filtered out the institutional accounts (including big ‘Vs’ (the most influential celebrities) in Weibo) and used only the individual’s original posts.
To measure people’s general emotional well-being rather than specific emotions towards COVID-19 itself, we excluded all COVID-19-related posts on the basis of an exhaustive list of COVID-19-related terms (Supplementary Fig. 19). During the implementation, we translated the COVID-19-related terms into the 30 most common languages to account for multilingual content. Posts where any one of these text patterns matched with the content were flagged as COVID-19 related.
社交媒体数据 我们从两大微博平台,推特和微博(推特的中文等价物)收集社交媒体数据。数据涵盖了从2020年1月1日(当时2019冠状病毒疾病传播基本上仅限于中国武汉地区)到2020年5月31日(当时大多数国家已从第一次2019冠状病毒疾病疫情中恢复)。我们的分析只对用户同意分享其位置信息的地理定位社交媒体帖子感兴趣。在研究期间,全球收集了6.54亿条地理标记的推特和微博帖子(图1a)。
推特是一个全球平台,用户可以在这里与追随者共享内容或“推特”。截至2019年,推特每月有3.3亿活跃用户。用户可以通过启用背景GPS采集或在推文中标记位置来同意共享其位置信息。这些地理定位推文用经纬度坐标编码。我们采用反向地理编码技术从地理位置中提取国家信息。2019年,推特改变了其地理标记方法,以加强隐私保护。然而,由于我们的分析是在国家或国家以下各级进行的,这种方法的变化不会影响个人的国家/国家分配。作为推特在中国的对手,新浪微博是顶级社交网络平台之一,到2020年,每月活跃用户数达到4.62亿。地理标记的微博帖子是所有微博帖子的子样本,用户同意分享他们的位置信息。该位置信息基于用户在智能手机或计算机上发布微博时的准确纬度和经度。我们过滤掉了机构账户(包括微博上最有影响力的名人),只使用了个人的原创帖子。
为了衡量人们对2019冠状病毒疾病本身的总体情绪幸福感,而不是具体情绪,我们根据一份详尽的2019冠状病毒疾病相关术语列表排除了所有与2019冠状病毒疾病相关的帖子(补充图19)。在实施过程中,我们将2019冠状病毒疾病相关术语翻译成30种最常见的语言,以说明多语言内容。其中任何一个文本模式与内容匹配的帖子被标记为2019冠状病毒疾病相关。
Lockdown policy data. We collected and evaluated country-level lockdown policy data from two sources. The first was the Oxford Coronavirus Government Response Tracker (OxCGRT), and the second was the WHO Public Health and Social Measures (PHSM, https://www.who.int/emergencies/diseases/novel-coronavirus-2019/phsm). The former records 17 different government responses, including 8 related to containment and movement restrictions. Each government response is coded for response stringency (response-specific) and scope (‘targeted’ versus ‘general’). The latter joins seven policy databases together (including the OxCGRT) to provide a common taxonomy and comprehensive policy outlook at the national and subnational levels.
We consider the WHO PHSM to be comprehensive of all COVID-19 policy announcements because this dataset aggregates the efforts of seven separate COVID-19 policy databases. However, upon manual review of this dataset, we decided that its encoding of policy announcements into stringencies and measures was not sufficiently accurate for use as our final start and end order database. Instead, we used the WHO PHSM dataset to cross-validate the OxCGRT dataset by comparing all OxCGRT policy start dates, levels of enforcement and scopes with the WHO PHSM dataset’s announcements. When there was a discrepancy between the two datasets, we updated the OxCGRT dataset with the manually reviewed announcement from the WHO PHSM dataset.
封锁政策数据 我们从两个来源收集并评估了国家层面的封锁政策数据。第一个是牛津冠状病毒政府反应跟踪系统(OxCGRT),第二个是世界卫生组织公共卫生和社会措施(PHSM,https://www.who.int/emergencies/diseases/novel-coronavirus-2019/phsm). 前者记录了17种不同的政府回应,包括8种与遏制和行动限制有关的回应。每个政府响应都针对响应严格性(响应特定)和范围进行编码(“目标”与“一般”)。后者将七个政策数据库(包括OxCGRT)连接在一起,以在国家和国家以下各级提供共同的分类和全面的政策展望。
我们认为世界卫生组织PHSM全面涵盖了所有2019冠状病毒疾病政策公告,因为该数据集汇集了七个独立的2019冠状病毒疾病政策数据库的努力。然而,在手动审查该数据集后,我们认为其将政策公告编码为紧急情况和措施的准确性不足以用作我们的最终开始和结束顺序数据库。相反,我们使用世界卫生组织PHSM数据集,通过将所有OxCGRT政策开始日期、执行水平和范围与世界卫生组织PHSM数据集的公告进行比较,对OxCGRT数据集进行交叉验证。当两个数据集之间存在差异时,我们使用世界卫生组织PHSM数据集手动审查的公告更新了OxCGRT数据集。
Epidemiological data. The COVID-19 epidemiological data were collected from the COVID-19 dashboard by the Center for Systems Science and Engineering at Johns Hopkins University (https://coronavirus.jhu.edu/map.html).
流行病学数据 2019冠状病毒疾病流行病学数据由约翰霍普金斯大学系统科学与工程中心从2019冠状病毒疾病仪表盘收集、(https://coronavirus.jhu.edu/map.html).
Human mobility data. In 2020, Google provided a comprehensive COVID-19 Community Mobility Report (https://www.google.com/covid19/mobility/) showing the changes in mobility patterns in 135 countries from 15 February to 27 July 2020. The report displays the relative strengths of mobility indices in six different aspects (retail and recreation, grocery and pharmacy, parks, transit stations, workplaces, and residential) based on the baseline values, which are calculated by taking the median value of visits and length of stay in each type of place during five weeks before the COVID-19 pandemic.
人员流动数据 2020年,谷歌提供了一份全面的2019冠状病毒疾病社区流动性报告(https://www.google.com/covid19/mobility/)显示了2020年2月15日至7月27日期间135个国家流动模式的变化。该报告根据基线值显示了流动指数在六个不同方面(零售和娱乐、杂货店和药店、公园、中转站、工作场所和住宅)的相对优势,基线值是通过计算2019冠状病毒疾病大流行前五周内每种类型场所的访视中值和停留时间来计算的。
Country-level indices. We collected a rich set of country-level indices to assist with the heterogeneity analysis of sentiment drop globally. The base years are different for each index due to differences in the most recent data availability. First, we collected a set of development indices. We collected gross domestic product per capita (2018), urbanization rate (2019) and unemployment rate (2019) from the World Bank; these are the commonly used indicators to represent a country’s development status. We also collected the 2017 Socio-demographic Index, a comparative summary socio-demographic metric synthesizing per capita income, educational attainment and fertility rate, which is commonly used to explain the disparities in countries’ burdens of disease. Second, we collected two indices related to a country’s management capacity: government efficiency index (2018) from the World Bank and the 2015 Global Health Security Index (https://www.ghsindex.org/). Government efficiency is a comprehensive measure of public sectors’ performance and has been proven to predict a country’s capacity to control the COVID-19 pandemic. The Global Health Security Index is the first comprehensive assessment of health security at the global scale. Finally, we collected culture-related indices from Awad et al… The key culture variable of interest is cultural tightness, which measures the tightness of social norms and was found to explain a country’s capacity to manage the COVID-19 pandemic. The cultural indices in this dataset also include individualism, religiousness and relational mobility (that is, the fluidity with which people can develop new relationships).
*国家一级指数。*我们收集了一组丰富的国家级指数,以帮助进行全球情绪下降的异质性分析。由于最新数据可用性的差异,每个指数的基准年都不同。首先,我们收集了一组发展指数。我们从世界银行收集了人均国内生产总值(2018年)、城市化率(2019年)和失业率(2019年);这些是代表一个国家发展状况的常用指标。我们还收集了2017年社会人口指数,这是一个综合人均收入、教育程度和生育率的比较摘要社会人口指标,通常用于解释各国疾病负担的差异。其次,我们收集了两个与国家管理能力相关的指标:世界银行的政府效率指数(2018年)和2015年全球卫生安全指数(https://www.ghsindex.org/). 政府效率是衡量公共部门绩效的综合指标,已被证明可以预测一个国家控制2019冠状病毒疾病疫情的能力。全球健康安全指数是第一个在全球范围内全面评估健康安全的指数。最后,我们收集了Awad等人的文化相关指数。关注的关键文化变量是文化紧密性,它衡量社会规范的紧密性,并被发现可以解释一个国家管理2019冠状病毒疾病大流行的能力。该数据集中的文化指数还包括个人主义、宗教性和关系流动性(即人们可以发展新关系的流动性)。
Sentiment analysis.
We employed NLP sentiment imputation algorithms to analyse the million daily social media posts that make up our dataset. Different types of NLP methods have been used for sentiment classification of textual data in the existing literature. Dictionary-based approaches match the words that make up each text entry to sentiment-specific lists (or dictionaries). LIWC and the Hedonometer project offer two such dictionaries and have often been used in social media research. More recently, sentiment classification of text data has been successfully implemented using neural networks such as transformers or convolutional neural networks. These methods create high-dimensional representations of the text entries, usually based on pre-trained word vectors. For this study, we used a transformer that has achieved state-of-the-art results in text classification: BERT. Unlike traditional word2vec text representation models, BERT creates dynamic word representations informed locally by the neighbouring context. Our global study uses a pre-trained Multilingual BERT model, which creates representations broadly consistent across different languages. Sentence-BERT provides an additional document-level embedding. On the basis of Siamese-coupled neural networks, this model produces semantically meaningful representations of sentences that can be compared among themselves in the embedding space. For our study, we created these high-dimensional representations for every social media entry in our dataset.
We trained a simple logistic-regression classifier on the first 100 principal component analysis dimensions of the Sentence-BERT social media post embeddings. The training data we used are a set of 1,600,000 tweets labelled as positive or negative. Since representations are consistent across languages, we were able to train our sentiment classifier in English and predict sentiment in the 104 languages supported by Multilingual BERT, which covers 65 identifiable languages in Twitter and Weibo. We evaluate the performance of this model in Supplementary Note 1 and find a classification accuracy of 0.84 for English content and 0.75 on average in other languages (see the details in Supplementary Table 1). We further compared the sentiment from our BERT-based algorithm with sentiment indices from the dictionary-based LIWC method using English tweets, and the results show high consistency (Supplementary Fig. 1). To enhance the transparency of our algorithm, we display how people changed their use of emotional words (defined by the LIWC English dictionary) accompanied with the decline in our sentiment index at the onset of the COVID-19 pandemic in Supplementary Note 3. We averaged each social media post sentiment score daily at the national and subnational levels (for example, state or province; the largest subnational administrative unit of a country). To avoid oversampling individuals who post the most on social media, we first aggregated our sentiment data to the individual–date level and then averaged the individual sentiments on each day to the subnational (state/province) or national level. Moreover, we used the one-class classification approach to detect and exclude Twitter bots.
我们使用自然语言处理情感插补算法来分析构成我们数据集的每天数百万条社交媒体帖子。现有文献中使用了不同类型的自然语言处理方法对文本数据进行情感分类。基于词典的方法将构成每个文本条目的单词与情感特定列表(或词典)相匹配。LIWC和享乐计项目提供了两个这样的词典,并且经常用于社交媒体研究。最近,文本数据的情感分类已使用神经网络(如变压器或卷积神经网络)成功实现。这些方法通常基于预先训练的词向量创建文本条目的高维表示。在本研究中,我们使用了一个在文本分类中取得最先进成果的转换器:BERT。与传统的word2vec文本表示模型不同,BERT创建由相邻上下文局部通知的动态单词表示。我们的全球研究使用预先训练的多语言BERT模型,该模型创建了在不同语言之间广泛一致的表示。句子BERT提供了额外的文档级嵌入。基于暹罗耦合神经网络,该模型生成句子的语义有意义表示,可以在嵌入空间51中相互比较。在我们的研究中,我们为数据集中的每个社交媒体条目创建了这些高维表示。
我们在社交媒体后嵌入句子的前100个主成分分析维度上训练了一个简单的逻辑回归分类器。我们使用的训练数据是一组1600000条推文,标记为正或负。由于表示在不同语言之间是一致的,我们能够用英语训练我们的情感分类器,并在多语言BERT支持的104种语言中预测情感,这涵盖了推特和微博中的65种可识别语言。我们在补充注释1中评估了该模型的性能,发现英语内容的分类精度为0.84,其他语言的平均分类精度为0.75(详见补充表1)。我们进一步比较了基于BERT算法的情感与基于词典的LIWC方法使用英语推文的情感指数,结果表明具有高度一致性(补充图1)。为了提高我们算法的透明度,我们在补充注释3中展示了人们在2019冠状病毒疾病大流行开始时如何改变情感词的使用(由LIWC英语词典定义),同时情绪指数下降。我们每天在国家和国家以下各级(例如,州或省;一个国家最大的国家以下行政单位)平均每个社交媒体帖子情绪分数。为了避免对在社交媒体上发布最多的个人进行过度抽样,我们首先将情绪数据聚合到个人-日期级别,然后将每天的个人情绪平均到国家以下(州/省)或国家级别。此外,我们使用单类分类方法来检测和排除推特机器人。
Sentiment alterations during the COVID-19 pandemic.
Modelling of sentiment dynamics. To measure the ability of sentiment recovery and each country’s recovery status, we adopted the following procedures:
(1) Select countries. We only kept countries in which tweets were generated by more than 100 active users a day from 1 January to 31 May 2020, to ensure that extreme observations and insufcient data do not severely impact a country’s sentiment index.
(2) Detrend. To extract the overall sentiment trend out of daily sentiment fuctuations, we implemented seasonal trend decomposition using a locally estimated scatterplot smoothing algorithm with seven days as a feeding parameter for temporal cycles to remove seven-day periodical patterns from the raw data and average the fuctuations (Supplementary Fig. 9). The seven-day period captures weekly circular patterns and is further confrmed when applying the Fourier transformation algorithm to detect temporal cycles of sentiment.
(3) Identify drop-date and min-date. Drop-date is defned as the day when a country’s sentiment started to be afected by COVID-19, while min-date is when a country reached its minimum sentiment. Tough most countries have only one sentiment nadir caused by COVID-19, a few countries have sentiment drops due to other events coinciding with the COVID-19 period. To locate the period related to COVID-19, we introduced T-max, the date on which the share of COVID-19-related tweets reached the maximum proportion among all tweets. To get sentiment min-date, we searched for the date on which a country’s sentiment reached its minimum value within 30 days of the country’s T-max. For sentiment drop-date, we searched for the date on which the share of COVID-19-related tweets reached 20% of the maximum share achieved on T-max. Tis is the moment when people started to pay attention to COVID-19 topics within a country. Te results from the cumulative sum test on a country’s sentiment curve confrmed that this is the approximate time point when a country’s sentiment started to decline.
情绪动力学建模。为了衡量情绪恢复的能力和每个国家的恢复状态,我们采用了以下程序:
(1) 选择国家。从2020年1月1日到5月31日,我们只保留每天有100多名活跃用户发布推文的国家,以确保极端观察和虚假数据不会严重影响一个国家的情绪指数。
(2) Detrend。为了从日常情绪函数中提取整体情绪趋势,我们使用局部估计的散点图平滑算法进行季节趋势分解,将7天作为时间周期的输入参数,从原始数据中删除7天的周期性模式,并对函数进行平均(补充图9)。七天周期捕捉每周循环模式,并在应用傅立叶变换算法检测情绪的时间周期时得到进一步证实。
(3) 确定投放日期和最小日期。下降日期被定义为一个国家的情绪开始受到2019冠状病毒疾病影响的日期,而最小日期是一个国家达到其最低情绪的日期。大多数国家只有一个由2019冠状病毒疾病引起的情绪低谷,少数国家由于与2019冠状病毒疾病时期重合的其他事件而情绪下降。为了确定与2019冠状病毒疾病相关的时期,我们引入了T-max,即2019冠状病毒疾病相关推文的份额在所有推文中达到最大比例的日期。为了获得情绪最小日期,我们搜索了一个国家的情绪在该国T-max的30天内达到其最低值的日期。对于情绪下降日期,我们搜索了与2019冠状病毒疾病相关的推特的份额达到T-max上实现的最大份额的20%的日期。这是一个国家内人们开始关注2019冠状病毒疾病主题的时刻。对一国情绪曲线的累积和检验结果证实,这是一国情绪开始下降的近似时间点。
Sentiment drops. To estimate the effect of COVID-19 on sentiment drop, we exploited the ‘donut regression discontinuity’ design at the timing threshold of min-date, t, by removing the confounding days between drop-date and min-date and measuring the sentiment discontinuity from the level before drop-date to that after min-date (Supplementary Fig. 11). We use time (daily) as the running variable, and the estimate for sentiment shock (τRD) we use is:
情绪下降。为了估计2019冠状病毒疾病对情绪下降的影响,我们在最小日期t的时间阈值下利用了“甜甜圈回归不连续性”设计,方法是去除下降日期和最小日期之间的混杂天数,并测量情绪不连续性,从下降日期之前的水平到最小日期之后的水平(补充图11)。我们使用时间(每天)作为运行变量,我们使用的情绪冲击(τRD)估计为:

In the equation, E is the expectation value. This RDD is equivalent to segmented regressions used for interrupted time series analysis in public health research. This quasi-experimental design is particularly useful in cases where an abrupt event causes all units to be treated, and there are potential confounding time trends pre- and post-treatment. To calculate the sentiment limit on both sides of the running variable, we used local linear regression to fit the sentiment curve on each side of the threshold t. Local linear instead of higher-order polynomial fit is recommended by previous literature. Fitting the general trends pre- and post-interruption can prevent one day with extreme sentiment values to substantially bias the magnitude of sentiment drop. In practice, we estimated the equation for each country separately with administration (province or state level) sentiment time series as input:
在方程中,E是期望值。该RDD相当于公共卫生研究中用于中断时间序列分析的分段回归。这种准实验设计在突发事件导致所有单元都被处理的情况下特别有用,并且在处理前后存在潜在的混淆时间趋势。为了计算运行变量两侧的情绪极限,我们使用局部线性回归拟合阈值t两侧的情绪曲线。以前的文献建议使用局部线性拟合代替高阶多项式拟合。拟合中断前后的总体趋势可以防止一天出现极端情绪值,从而严重影响情绪下降的幅度。在实践中,我们以行政(省级或州级)情绪时间序列作为输入,分别估计每个国家的方程:

In the equation, ysit is the average sentiment index for province/state s in country i on date t, COVIDit is a binary variable equal to 1 when the time is after the country’s sentiment nadir and 0 otherwise, and rel_datesit is the date measured in days from the minimum sentiment date t. The terms γ1rel_datesit and γ2rel_datesit×COVIDit absorb the smooth relationship of sentiment trend within the bandwidth surrounding t. We used a bandwidth of 28 days on each side and the triangular kernel as our base specification. As robustness checks, we also tested the results for the uniform kernel as well as for different bandwidths, which yields similar results (Supplementary Table 6 and Supplementary Fig. 7). In all cases, we weighed the regression by the number of tweets so that larger provinces/states have higher weights. We added day-of-week fixed effects (δDOW) and state fixed effects (ηs) to control for weekly cyclical and time-invariant state-specific confounding factors; εsit is the error term. β is our coefficient of interest, the magnitude of which is divided by the standard deviation of sentiment pre-COVID-19 (that is, before the sentiment drop-date of each country) to make the results more comparable across countries. The standard errors are clustered within province/state to account for sentiment correlation.
在等式中,ysit是国家i中省/州s在日期t的平均情绪指数,当时间在国家情绪最低点之后时,COVIDit是一个二元变量,等于1,否则等于0,rel_datesit是从最低情绪日期t开始以天为单位测量的日期。术语γ1rel_datesit和γ2rel_datesit×COVIDit吸收了t周围带宽内情绪趋势的平滑关系。我们在每侧使用了28天的带宽,并将三角形内核作为我们的基本规范。作为稳健性检查,我们还测试了均匀核以及不同带宽的结果,这产生了类似的结果(补充表6和补充图7)。在所有情况下,我们根据推文数量对回归进行加权,以便较大的省份/州具有更高的权重。我们添加了周固定效应(δDOW)和状态固定效应(ηs),以控制周周期性和时不变的状态特定混杂因素;εsit是误差项。β是我们的兴趣系数,其大小除以2019冠状病毒疾病前情绪的标准差(即每个国家的情绪下降日期之前),以使结果在各国之间更具可比性。标准误差在省/州内聚集,以解释情绪相关性。
Sentiment recovery. To characterize the recovery of each country, we established two indices: recovery half-life and recovery status. Recovery half-life represents a country’s recovery speed, while recovery status represents to what degree a country’s sentiment had recovered at the end of May 2020. Following Fan et al., we parametrized the sentiment recovery process through an exponential model and estimated the parameters u, v and γ with nonlinear least squares. More specifically, we regress the daily sentiment value f(x) on x, which captures the number of days since the country achieved the minimum level of sentiment using the following exponential function:
*情绪恢复。*为了描述每个国家的恢复情况,我们建立了两个指数:恢复半衰期和恢复状态。复苏半衰期代表一个国家的复苏速度,而复苏状态代表一个国家的情绪在2020年5月底恢复到何种程度。根据Fan等人,我们通过指数模型对情绪恢复过程进行参数化,并使用非线性最小二乘法估计参数u、v和γ。更具体地说,我们在x上回归每日情绪值f(x),该值捕捉了自该国使用以下指数函数达到最低情绪水平以来的天数:
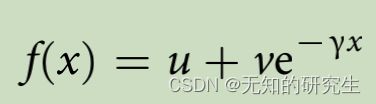
To ensure that the sentiment we measured was free from impacts of the Black Lives Matter campaigns, we set 25 May 2020 (that is, when the George Floyd event took place) as the end date of our sentiment analysis. We removed all countries with abnormal sentiment fluctuations on which the parameter calibration algorithm could not converge within 1,000 steps during the fitting process to ensure quality.
We then identified the two recovery indices using the fitted exponential model. To find the recovery half-life, we searched for the date on the fitted curve where the sentiment recovered 50% of the distance between a country’s sentiment nadir and its final sentiment on 25 May. To further understand the recovery status, we compared a country’s sentiment status on 25 May with the baseline level before the sentiment drop-date and defined it with pre-COVID-19 sentiment standard deviation as a unit to ensure comparability across countries (for example, −1 indicates recovering to a status 1 s.d. below the baseline sentiment).
为了确保我们测量的情绪不受黑人生活事件活动的影响,我们将2020年5月25日(即乔治·弗洛伊德事件发生时)定为情绪分析的结束日期。我们删除了所有情绪波动异常的国家,这些国家的参数校准算法在拟合过程中无法在1000步内收敛,以确保质量。
然后,我们使用拟合指数模型确定了两个恢复指数。为了找到恢复半衰期,我们搜索了拟合曲线上的日期,其中情绪恢复了一个国家情绪最低点与其5月25日最终情绪之间距离的50%。为了进一步了解恢复状态,我们将一个国家5月25日的情绪状态与情绪下降日期之前的基线水平进行了比较,并以2019冠状病毒疾病之前的情绪标准差为单位进行定义,以确保各国之间的可比性(例如,−1表示恢复到低于基线情绪1 s.d.的状态)。
Impacts of lockdowns on expressed sentiment.
When defining lockdowns, we refer to the “stay-at-home requirements” policy category of OxCGRT60. A country is defined as a lockdown country if it has national-level requirements on not leaving the house except essential trips (that is, levels 2 and 3 of the C6 policy category in OxCGRT). Our cross-validation process was summarized in the ‘Data’ section. The lockdown dates compare with the sentiment drop, and min dates are summarized in Supplementary Fig. 14.
在定义锁定时,我们参考OxCGRT60的“居家要求”政策类别。如果一个国家在国家层面上要求除必要的旅行外不得外出(即《牛津综合关税公约》中C6政策类别的2级和3级),则该国被定义为封锁国。“数据”部分总结了我们的交叉验证过程。锁定日期与情绪下降相比,最小日期总结在补充图14中。
Here we applied SCM to estimate sentiment alterations after lockdown interventions for each country separately. In the case that no single country alone provided a good comparison for the lockdown country of interest (that is, violating the parallel trend assumptions required for difference-in-differences or event studies), we constructed a combination of non-lockdown countries as a synthetic control group to best resemble the characteristics of the treated country before its lockdown. We then compared the sentiment of a treated country on days after the lockdown with the weighted average sentiment of the control countries at the same period to estimate the treatment effect. The weights assigned to each control country were calculated such that the simulated synthetic control best resembles the treated country of interest in the pre-lockdown period. Mathematically, the distance between the vector of pre-specified characteristics of the treated country and that of the weighted average controls is minimized before the lockdown time.
在这里,我们应用SCM分别估计每个国家封锁干预后的情绪变化。在没有一个国家单独为封锁国家提供良好比较的情况下(即,违反差异或事件研究中差异所需的平行趋势假设),我们将非锁定国家的组合构建为一个综合对照组,以最接近被治疗国锁定前的特征。然后,我们将被治疗国家在锁定后几天的情绪与同期对照国家的加权平均情绪进行比较,以估计治疗效果。计算分配给每个控制国家的权重,以使模拟的综合控制最类似于锁定前时期处理的关注国家。从数学上讲,在锁定时间之前,被治疗国家的预先指定特征向量与加权平均控制向量之间的距离最小化。
The validity of synthetic control relies heavily on the countries included in the ‘donor pool’ and the observable characteristics that the weights of synthetic control are built on. We allowed the ‘late adopters’ of lockdown policies to serve as controls for the ‘early adopters’ to increase the similarity between the treatment country and its donor pool. This approach does not change the results for late adopters and those early adopters for which appropriate comparisons can be constructed from the never adopters (for example, northern European countries rely heavily on Sweden as control); but it can provide a better simulation of the comparison scenario of early adopters with no comparable countries that never implemented lockdown policies. We only explored one-week post-lockdown in the SCM analysis so that late adopters implemented more than seven days after a specific treated country could be matched to enhance comparability between a treatment country and its synthetic control country. Meanwhile, we excluded countries with many subnational-level lockdowns, including the United States, China, Nigeria, Brazil and Germany. We also included four layers of socio-economic and pandemic-related variables in the covariates to ensure that higher weights were assigned to similar countries. Details about the variables included as covariates and the associated robustness checks are presented in Supplementary Note 4.
综合控制的有效性在很大程度上取决于“捐助者库”中包括的国家以及综合控制权重所基于的可观察特征。我们允许封锁政策的“晚期采用者”作为“早期采用者”的控制,以增加治疗国与其捐赠库之间的相似性。这种方法不会改变晚期采用者和早期采用者的结果,对于早期采用者,可以与从未采用者进行适当的比较(例如,北欧国家严重依赖瑞典作为对照);但它可以更好地模拟早期采用者的比较场景,因为没有可比的国家从未实施过封锁政策。我们在供应链管理分析中只探讨了锁定后一周的情况,以便在特定治疗国家匹配后七天以上实施延迟采用者,以增强治疗国家与其综合控制国家之间的可比性。同时,我们排除了许多国家以下级别封锁的国家,包括美国、中国、尼日利亚、巴西和德国。我们还将社会经济和流行病相关变量的四个层次纳入协变量,以确保将更高的权重分配给类似国家。关于作为协变量包含的变量以及相关稳健性检查的详细信息,见补充注释4。
For the identification of SCM to be causal, we need to assume that the choice of which unit will be treated is random conditional on the choice of the donor pool, the observable variables included as predictors and the unobserved factors that can be captured by the pre-treatment path of the outcome variable. It is hard to test this assumption directly, and COVID-19 policies might generate anticipation effects and spillover effects for some countries; care is thus warranted for interpreting these estimates as causal.
为了确定SCM的因果关系,我们需要假设将治疗哪个单位的选择是随机的,取决于供体库的选择、作为预测因子的可观察变量以及可通过结果变量的预处理路径捕获的未观察因素。很难直接检验这一假设,2019冠状病毒疾病政策可能会对一些国家产生预期效应和溢出效应;因此,有必要谨慎地将这些估计解释为因果关系。
Results
Expressed sentiment alterations during the COVID-19 pandemic. The advent of COVID-19 was followed by a sizable drop in global expressed sentiment (Fig. 1b), especially after the World Health Organization (WHO) declared COVID-19 a global pandemic on 11 March 2020. Figure 2a highlights the universality of the sentiment change associated with the COVID-19 pandemic: all countries in our sample sequentially suffered sentiment alterations around the beginning of the pandemic, with varying magnitudes and durations. Sentiment gradually recovered after the shock, showing a similar trend with survey measurements of risk perception (for example, COVID-19 Snapshot Monitoring conducted in Germany). To measure the patterns of sentiment alterations created by COVID-19, we develop two global indices (Methods, ‘Modelling of sentiment dynamics’): sentiment drop and recovery half-life.
*在2019冠状病毒疾病期间表达的情绪变化。*随着2019冠状病毒疾病的出现,全球表达的情绪大幅下降(图1b),特别是在世界卫生组织(WHO)于2020年3月11日宣布2019冠状病毒疾病为全球泛病毒之后。图2a强调了与2019冠状病毒疾病大流行相关的情绪变化的普遍性:我们样本中的所有国家在大流行开始前后相继经历了情绪变化,具有不同的量级和持续时间。情绪在冲击后逐渐恢复,在风险感知的调查测量中显示出类似的趋势(例如,在德国进行的2019冠状病毒疾病快照监测)。为了测量2019冠状病毒疾病引起的情绪变化模式,我们开发了两个全局指数(方法,“情绪动力学建模”):情绪下降和恢复半衰期。
We define the sentiment drop as a country’s sentiment decline from the level before COVID-19 to its lowest value during the first wave of COVID-19. To estimate it, we separately fitted a sentiment trend before the date sentiment started to decline and after the date it reached its lowest value using local linear regressions; we then applied regression discontinuity design (RDD) to quantify the gap (see Methods, ‘Sentiment drops’, for the details). RDD is a quasi-experimental design commonly adopted to measure the impacts of abrupt and exogenous events, which allows us to separate the structural shock from daily fluctuations in sentiment. We measured the magnitude of a country’s sentiment drop relative to the standard deviation of the country’s sentiment before COVID-19 (that is, before the detected date of sentiment decline) for comparability across countries. We find that the sentiment impact of the COVID-19 pandemic is negative for all countries, with the average drop equivalent to 0.85s.d. (P<0.001; 95% confidence interval (CI), (0.60, 1.10); Fig. 2b). The sentiment changes are statistically significant at the 5% level for the vast majority (91.5%) of the countries and present large heterogeneity across countries (see Supplementary Table 5 and Supplementary Fig. 12 for the country-specific results). The largest sentiment drops took place in Australia (coefficient=−3.308; P<0.001; 95% CI, (−3.656, −2.960)), Spain (coefficient=−2.927; P<0.001; 95% CI, (−3.204, −2.650)), the United Kingdom (coefficient=−2.354; P<0.001; 95% CI, (−2.521, −2.186)) and Colombia (coefficient=−2.112; P<0.001; 95% CI, (−2.326, −1.899)), while Botswana, Tunisia, Oman, Bahrain and Greece had effect sizes smaller than −0.15s.d.
我们将情绪下降定义为一个国家的情绪从2019冠状病毒疾病之前的水平下降到2019冠状病毒疾病第一波期间的最低值。为了估计它,我们使用局部线性回归分别拟合了情绪开始下降之前的感知趋势和情绪达到最低值之后的感知趋势;然后,我们应用回归不连续设计(RDD)来量化差距(有关详细信息,请参阅方法“情绪下降”)。RDD是一种准实验设计,通常用于测量突发和外源事件的影响,它使我们能够从情绪的日常波动中分离出结构性冲击。我们测量了一个国家的情绪下降幅度相对于2019冠状病毒疾病之前(即检测到情绪下降日期之前)该国情绪的标准差,以衡量各国的可比性。我们发现,2019冠状病毒疾病大流行对所有国家的情绪影响都是负面的,平均下降相当于0.85s.d(情绪冲击)(P<0.001;95%置信区间,(0.60,1.10);图2b)。绝大多数国家(91.5%)的情绪变化在5%的水平上具有统计学意义,并且各国之间存在很大的异质性(具体国家的结果见补充表5和补充图12)。情绪下降幅度最大的是澳大利亚(coeffi cient)=−3.308; P<0.001;95%置信区间(−3.656, −2.960)),西班牙(系数)=−2.927; P<0.001;95%置信区间(−3.204, −2.650)),英国(系数)=−2.354; P<0.001;95%置信区间(−2.521, −2.186))和哥伦比亚(系数=−2.112; P<0.001;95%置信区间(−2.326, −1.899)),而博茨瓦纳、突尼斯、阿曼、巴林和希腊的影响规模小于−0.15s.d。
To contextualize our results, we first examined the average sentiment variations over the course of a week before COVID-19. We find that people have a higher expressed sentiment on weekends (Supplementary Fig. 13). The average difference in sentiment between Sunday and Monday (that is, the unhappiest day) was 0.18 s.d. across countries, which has a similar magnitude with findings in previous work. The effect size of COVID-19 (that is, 0.85 s.d. across the globe) is more than 4.7 times as large as this weekly sentiment drop from Sunday to Monday. In addition, according to a previous study, the difference in sentiment between days with maximum temperatures above 40 °C and days with the most comfortable maximum temperatures of 21–24 °C is 0.21 s.d. (25% of our estimated sentiment drop during COVID-19); nearby hurricanes cause a reduction in expressed sentiment of around 0.4–0.7 s.d. (47–82% of our estimated sentiment drop during COVID-19). This suggests that the acute impact of COVID-19 on sentiment is potentially more pronounced than that of extreme hot temperatures and climate disasters.
为了结合我们的结果,我们首先检查了2019冠状病毒疾病之前一周内的平均感觉变化。我们发现,人们在周末表达的情绪更高(补充图13)。各国周日和周一(即最不快乐的一天)之间的平均情绪差异为0.18 s.d.,与之前工作中的发现类似。COVID-19 的影响大小(即全球 0.85 s.d.)是周日至周一每周情绪下降的 4.7 倍以上。此外,根据之前的一项研究,最高温度超过40°C的日子与最高温度21–24°C的日子之间的情绪差异为0.21 s.d.(2019冠状病毒疾病期间我们估计情绪下降的25%);附近的飓风导致表达的情绪减少约0.4-0.7s.d.(我们估计的情绪在2019冠状病毒疾病期间下降了47-82%)。这表明,2019冠状病毒疾病对情绪的急性影响可能比极端高温和气候灾害更为显著。
Besides the onset of sentiment drop, we estimate how long it took for people’s expressed sentiment to recover. Our second index, sentiment recovery half-life, measures the days it took for a country to recover from the lowest sentiment to half of its stationary state of recovered sentiment (that is, the convergence value in the calibrated sentiment recovery model). It is important to mention that the recovery time not only reflects the emotional resilience towards the pandemic itself. This measure should be interpreted as a combined effect of pandemic severity and regulatory policies, and it may be influenced by other events happening around the first wave of the pandemic within each country. Following best practices proposed by previous studies, we characterize the sentiment recovery process of each country in our sample as an exponential function starting from its minimum sentiment using equation (3) (Methods, ‘Sentiment recovery’, and Supplementary Fig. 10). The estimated indices show that the recovery half-life varies substantially across countries (Fig. 2c), ranging from 1.2 days (Israel) to 29.0 days (Turkey). Meanwhile, the new stationary state of recovered sentiment until 31 May 2020 also varies across countries: as shown in Fig. 2c, 18% of countries had sentiment recovered to a lower level (below −1.00 s.d.), 35% of countries recovered to the normal value (between −1.00 s.d. and 1.00 s.d.) and 46% of countries recovered to a higher level (above 1.00 s.d.). These results suggest a longer-term alteration in expressed sentiment in countries that show large discrepancies between their recovered sentiment and their average sentiment before COVID-19.
除了情绪下降的开始,我们估计人们表达的情绪需要多长时间才能恢复。我们的第二个指数,情绪恢复半衰期,衡量一个国家从最低情绪恢复到其恢复情绪的原始状态的一半所需的天数(即校准情绪恢复模型中的收敛值)。值得一提的是,恢复时间不仅反映了对疫情本身的情绪恢复能力。这一措施应被解释为大流行严重程度和监管政策的综合影响,并可能受到每个国家大流行第一波前后发生的其他事件的影响。根据先前研究提出的最佳实践,我们将样本中每个国家的情绪恢复过程描述为指数函数,从其最小情绪开始,使用等式(3)(方法“情绪恢复”和补充图10)。估计指数表明,各国的恢复半衰期差异很大(图2c),从1.2天(以色列)到29.0天(土耳其)。同时,截至2020年5月31日,情绪恢复的新平稳状态也因国家而异:如图2c所示,18%的国家的情绪恢复到较低水平(低于−1.00 s.d.),35%的国家恢复到正常值(介于−46%的国家恢复到更高水平(高于1.00标准差)。这些结果表明,在2019冠状病毒疾病之前恢复的情绪与平均情绪之间存在较大差异的国家,表达的情绪发生了长期变化。
Finally, we explore how the magnitude of sentiment alterations by country (sentiment drop and recovery half-life) correlates with countries’ pandemic severity, governance and cultural traits (see Methods, ‘Data’, for the full list of variables collected for testing). These results are intended to motivate exploration for future studies, as our country-level correlation analysis cannot pin down the causal mechanisms. The results show that countries with more confirmed COVID-19 cases experienced a larger sentiment drop (Supplementary Fig. 8a; Pearson correlation, ρ=0.250; P=0.007; 95% CI, (0.070, 0.414)). Moreover, we find that the governance efficiency index from the World Bank, a comprehensive measure of public sectors’ performance proven to predict a country’s capacity to control the COVID-19 pandemic33, is positively correlated with fast recovery (Supplementary Fig. 8b; ρ=−0.259; P=0.011; 95% CI, (−0.437, −0.061)). Beyond objective characteristics, cultures usually play an important role in how people perceive and react to collective threats. Previous studies have shown how nations with loose cultures (that is, having lenient norms and punishments for deviance) had more difficulty coordinating in the face of the pandemic. Consistently, we find a positive correlation between cultural looseness and sentiment drops (Supplementary Fig. 8c; ρ=0.447; P=0.001; 95% CI, (0.187, 0.649)). We also conduct correlation tests for other dimensions (such as a country’s development stage, health security and other cultural constructs from previous studies35), and none of them pass the 5% significance threshold after family-wise adjustment for multiple hypothesis testing (Supplementary Table 2).
最后,我们探讨了各国情绪变化的程度(情绪下降和恢复半衰期)如何与各国的大流行严重程度、治理和文化特征相关(有关为测试收集的完整变量列表,请参阅方法“数据”)。这些结果旨在激发对未来研究的探索,因为我们国家层面的相关性分析无法确定因果机制。结果表明,确诊2019冠状病毒疾病病例较多的国家经历了较大的情绪下降(补充图8a;皮尔逊相关,ρ=0.250;P=0.007;95%置信区间,(0.070,0.414))。此外,我们发现世界银行的治理效率指数与快速恢复呈正相关(补充图8b;ρ=−0.259; P=0.011;95%置信区间(−0.437, −0.061)). 除了客观特征外,文化通常在人们如何感知和应对集体威胁方面发挥重要作用。之前的研究表明,文化松散的国家(即对越轨行为有宽容的规范和惩罚)在面对大流行病时更难协调。一致地,我们发现文化松散和情绪下降之间存在正相关(补充图8c;ρ=0.447;P=0.001;95%置信区间,(0.187,0.649))。我们还对其他维度(如一个国家的发展阶段、健康安全和以前研究中的其他文化结构35)进行了相关测试,在对多假设测试进行家庭调整后,没有一个维度通过5%的显著性阈值(补充表2)。
Impacts of lockdowns on expressed sentiment. Given the absence of a vaccine during the first wave of the pandemic, many governments implemented a series of non-pharmaceutical interventions to contain the spread of the virus, with lockdowns being the most stringent ones. Lockdowns aim at minimizing physical contact among citizens, which deprives individuals of their freedom to undertake a wide range of daily activities and creates financial risks linked to job loss. Nevertheless, lockdowns could also generate a sense of security regarding virus control and curb public concern about the pandemic. Given these circumstances, the direction and magnitude of sentiment change after lockdowns are likely to be context-specific, depending on the timing of implementation and public attitudes towards the policy.
*封锁对表达情绪的影响。*鉴于在大流行的第一波期间没有疫苗,许多政府实施了一系列非药物干预措施来遏制病毒的传播,其中最严格的是封锁。封锁旨在最大限度地减少公民之间的身体接触,这剥夺了个人进行广泛日常活动的自由,并造成与失业有关的财务风险。尽管如此,封锁也可能产生一种关于病毒控制的安全感,并抑制公众对大流行的担忧。鉴于这些情况,封锁后情绪变化的方向和幅度可能因具体情况而异,具体取决于实施时间和公众对政策的态度。
The critical empirical challenge is that governments tend to impose lockdown measures in response to uncontrolled virus surges, challenging the construction of proper comparisons for the lockdown countries. Researchers can easily fall into the trap of comparing countries severely struck by COVID-19 and having a worsening sentiment trend with countries in a better situation, thus leading to false conclusions that lockdown itself worsens sentiment. Here we apply SCM to construct suitable comparisons for each lockdown country. SCM allows comparisons of a treated country’s sentiment after lockdown with the weighted average sentiment constructed from a pool of control countries that have no or late lockdown. Weights are assigned according to the similarity of the control countries with the lockdown countries of interest in pre-lockdown sentiment, pandemic severity and development indicators (Methods, ‘Impacts of lockdowns on expressed sentiment’).
关键的经验挑战是,政府往往采取封锁措施,以应对不受控制的病毒激增,这对建立封锁国家的适当比较提出了挑战。研究人员很容易陷入将受 COVID-19 严重打击的国家和情绪恶化的国家与情况较好的国家进行比较的陷阱,从而导致错误的结论,即封锁本身会使情绪恶化。在这里,我们应用SCM为每个封锁国家构建合适的比较。SCM允许将被处理国家在锁定后的情绪与从没有或延迟锁定的控制国家池中构建的加权平均年龄情绪进行比较。权重根据控制国与封锁前情绪、大流行严重性和发展指标(方法“封锁对表达情绪的影响”)相关封锁国的相似性分配。
We find that, on average, lockdown policies are followed by a small and positive sentiment change when comparing the average sentiment change across all locked-down countries with that of their synthetic controls in the first week of their implementation (Fig. 3a). Of the 52 countries that have over 500 daily geotagged social media posts, that implemented nationwide stay-at-home orders and for which we can construct valid synthetic controls, 34 (65%) show a positive sentiment impact of lockdown policy, and 18 (35%) display a negative effect (Fig. 3b; the country-specific results of lockdowns are summarized in Supplementary Tables 7 and 8). The sentiment change is rather subtle compared with the reduction in mobility in the first week after lockdown policies are implemented, estimated using the same empirical strategy (Supplementary Fig. 15a). In contrast, as expected, we find overwhelmingly (89% of countries) negative effects of lockdown on mobility in the first week post-lockdown (Supplementary Fig. 15b), suggesting that our method is effective in picking up the changes following lockdown.
我们发现,当将所有被封锁国家的平均情绪变化与其实施第一周的综合控制措施的平均情绪变化进行比较时,平均而言,封锁政策之后是一个小而积极的情绪变化(图3a)。在每天有超过 500 条地理标记社交媒体帖子的 52 个国家/地区中,实施了全国范围内的居家令,我们可以为其构建有效的综合控制措施,其中 34 个(65%)显示出封锁政策对情绪的积极影响,18 个( 35%)显示出负面影响(图 3b;补充表 7 和 8 中总结了针对特定国家/地区的封锁结果)。与实施封锁政策后第一周的流动性下降相比,情绪变化相当微妙,使用相同的经验策略进行估计(补充图15a)。相反,正如预期的那样,我们发现绝大多数(89%的国家)封锁对封锁后第一周的流动性产生了负面影响(补充图15b),这表明我们的方法在发现封锁后的变化方面是有效的。
Although the sentiment change after lockdown is small in magnitude for most countries, we do see notable dispersion in effect size, ranging from −1 s.d. to +1.2 s.d. Statistical inferences constructed through permutation tests also show countries having both significantly positive and negative effects (Supplementary Note 5). We find suggestive evidence that for countries having significantly negative sentiment change post-lockdown (Supplementary Fig. 4a), the negative effect is concentrated in the unhappiest (the bottom sentiment quartile) social media posts within a country, compared with the happiest ones (the top sentiment quartile) (Supplementary Fig. 4b,c). These results suggest that lockdown policies could have disproportionate emotional impacts on the unhappiest people. Due to the macro nature of this study, the distributional effects will need future research to validate.
虽然对大多数国家来说,封锁后的情绪变化在很大程度上很小,但我们确实看到了效应大小的显著差异,从−1 s.d.到+1.2 s.d。通过排列测试构建的统计推断也表明,国家具有显著的积极和消极影响(补充说明5)。我们发现了具有启发性的证据,即对于在锁定后情绪发生显著负面变化的国家(补充图4a),负面影响集中在一个国家内最不快乐(情绪最底层的四分位)的社交媒体帖子上,而最快乐的(情绪最顶层的四分位)(补充图4b,c)。这些结果表明,封锁政策可能会对最不幸福的人产生不成比例的情感影响。由于本研究的宏观性质,分配效应需要进一步研究来验证。
Discussion
Timely monitoring of the affective aspect of subjective well-being is essential for public policy design and management. Survey methods usually have limited samples within developing economies and require considerable time to execute, leading to a lack of generalizability and time delay when faced with catastrophes. Using high-frequency social media data and state-of-the-art NLP algorithms, we construct a comprehensive database of expressed sentiment covering over 100 countries worldwide (74% of the world population). Our method applies a state-of-the-art sentiment metric using lexical expressions of social media data to measure the changes in emotional states, which is validated to correlate with traditional survey measures of subjective well-being (see Supplementary Note 2 for expanded discussions on this topic).
及时监测主观幸福感的情感方面对于公共政策设计和管理至关重要。调查方法通常在发展中的经济中具有有限的样本,需要相当长的时间来执行,导致在面临灾难时缺乏普遍性和时间延迟。利用高频社交媒体数据和最先进的自然语言处理算法,我们构建了一个涵盖全球100多个国家(占世界人口74%)的情感表达综合数据库。我们的方法采用了最先进的感知指标,使用社交媒体数据的词汇表达来测量情绪状态的变化,这已被验证与主观幸福感的传统调查指标相关(有关此主题的详细讨论,请参阅补充说明2)。
Leveraging this database, we provide empirical evidence at the global scale of the alterations in expressed sentiment associated with COVID-19. We find a remarkable consistency in the way COVID-19 induced sentiment alterations across countries. Though taking place at different time points, almost all countries showed an abrupt and statistically significant sentiment decline around the beginning of the COVID-19 pandemic, followed by an asymmetric and slower recovery. Despite the similarity in the shapes of sentiment response curves, sentiment drops were larger in countries having more confirmed COVID-19 cases or looser cultures, while the recovery was faster for countries with efficient governments.
利用该数据库,我们在全球范围内提供了与2019冠状病毒疾病相关的情绪表达变化的实证证据。我们发现2019冠状病毒疾病引起各国情绪变化的方式具有显著的一致性。虽然发生在不同的时间点,但几乎所有国家在2019冠状病毒疾病大流行开始前后都表现出突然的、统计上显著的情绪下降,随后出现不对称的、缓慢的恢复。尽管感知反应曲线的形状相似,但在确诊2019冠状病毒疾病病例较多或文化较松散的国家,情绪下降幅度较大,而在政府效率较高的国家,情绪恢复较快。
We also display how this global sentiment database can be used to model sentiment changes after lockdown policies. Though severe emotional costs of lockdown policies are widely assumed, we found little evidence supporting this hypothesis (at least in the short term), when comparing countries that had implemented lockdown policies with their synthetic controls. This seemingly surprising result does not indicate that the social and financial risks created by lockdowns are trivial; instead, it suggests that for countries with severe pandemic situations, letting the virus spread without imposing stringent anti-contagion policies would lead to similar or even larger emotional distress.
我们还展示了如何使用该全球情绪数据库来模拟锁定政策后的情绪变化。虽然人们普遍认为封锁政策会产生严重的情感成本,但在将实施封锁政策的国家与其综合控制措施进行比较时,我们发现几乎没有证据支持这一假设(至少在短期内)。这一看似出人意料的结果并不表明封锁造成的社会和金融风险微不足道;相反,它表明,对于疫情严重的国家,在不实施严格的抗传染政策的情况下让病毒传播,将导致类似甚至更大的情绪困扰。
Several previous studies have also documented complex emotional responses towards lockdown, and studies showing a negative association between lockdown and sentiment usually have not removed the impacts of the pandemic itself from lockdown measurements (see Supplementary Note 7 for a literature summary). Our analysis implies that lockdown policies do not necessarily entail a trade-off between physical health and emotional well-being—at least not for the average population of a country. It is worth noting that COVID-19 policy is not a clean setting for causal identification, since the anticipation effect before lockdown interventions and the spillover effects in sentiment across treated and control countries could bias our estimates. In addition, we do see substantial dispersion in sentiment change after lockdown across countries. Understanding the specific, contextual factors that produce these variations in effect sizes is an important avenue for future work.
之前的几项研究也记录了对锁定的复杂情绪反应,研究表明锁定和情绪之间存在负相关,通常没有从锁定测量中消除大流行本身的影响(文献综述见补充注释7)。我们的分析表明,封锁政策并不必然需要在身体健康和情绪健康之间进行权衡,至少对一个国家的平均人口来说不是这样。值得注意的是,2019冠状病毒疾病政策并不是一个明确的因果识别环境,因为锁定干预前的预期效应以及治疗国和对照国之间情绪的溢出效应可能会影响我们的估计。此外,我们确实看到,在各国实行封锁后,情绪发生了实质性的分散变化。了解产生这些效应大小变化的具体背景因素是未来工作的重要途径。
Social media sentiment analysis provides complementary merits to those of survey measures for subjective well-being surveillance, but it has several limitations. First, the internet and social media penetration rates vary across countries and across different income and age groups within countries. Our analysis can only be used to understand the patterns of those who use Twitter or Weibo to communicate and lacks explanatory power for the least developed regions and elderly populations. Second, although social media expressed sentiment correlates with the affective aspects of subjective well-being, it cannot reliably measure the life satisfaction dimension of subjective well-being. Due to the limitations in representativeness and measurement, social media sentiment analysis should serve as a complement rather than a substitute for self-reported measures of subjective well-being. And more research is needed to understand the relationship between NLP-based sentiment and survey-based well-being in developing countries. Third, as sentiment analysis using digital trace is still a nascent research area, we do not have enough evidence to judge whether our expressed sentiment measurements can be used to diagnose clinically meaningful mental disorders. More psychometric validations with self-reported mental health status will be required to understand to what extent expressed sentiment on social media can be used in psychiatric epidemiology. Fourth, our study mainly focuses on sentiment changes for the average population of social media users within a country and how country-level characteristics and policies moderate the effect. While these measures are meaningful at a macro level to understand global heterogeneity, we cannot measure the moderating effects of individual-level socio-demographics, beliefs and preferences, which limits our capacity to speak to disparities and potential tailored interventions for particular population subgroups. The technological progress in demographic inference tools based on social media data41 could enable further heterogeneity analysis at the individual or subgroup level, which could be an important research direction for future studies. Finally, our study covers only the first wave of the COVID-19 pandemic, and there are countries still recovering from their first waves. Rather than directly extrapolating our empirical results to inform future pandemic strategies, we recommend careful evaluations using our method and extended datasets for future waves. Our data and methodology intend to provide a useful tool for tracking emotional well-being. This tool can support timely monitoring and decision-making by international and national policymakers.
社交媒体情绪分析为主观幸福感监测的调查措施提供了补充,但它有一些局限性。首先,互联网和社交媒体的普及率因国家和国家内不同的收入和年龄组而异。我们的分析只能用来了解那些使用推特或微博进行交流的人的模式,对最不发达地区和老年人口缺乏解释力。其次,虽然社交媒体表达的情绪与主观幸福感的情感方面相关,但它不能可靠地衡量主观幸福感的生活满意度维度。由于代表性和测量的局限性,社交媒体情绪分析应该作为补充而不是替代主观幸福感的自我报告测量。需要更多的研究来了解发展中国家基于 NLP 的情绪与基于调查的幸福感之间的关系。第三,由于使用数字追踪的情感分析仍然是一个新兴的研究领域,我们没有足够的证据来判断我们表达的情感测量是否可用于诊断具有临床意义的精神障碍。需要对自我报告的心理健康状况进行更多的心理指标验证,以了解社交媒体上表达的情绪在多大程度上可用于精神病学流行病学。第四,我们的研究主要关注一个国家内社交媒体用户平均年龄人口的情绪变化,以及国家层面的特征和政策如何调节这种影响。虽然这些措施在宏观层面对理解全球异质性很有意义,但我们无法衡量个人层面的社会人口、信仰和偏好的调节作用,这限制了我们谈论差异和潜在的量身定制干预措施的能力对于特定的人口亚组。基于社交媒体数据的人口统计推断工具的技术进步可以在个人或亚组层面进行进一步的异质性分析,这可能是未来研究的重要研究方向。最后,我们的研究仅涵盖了 COVID-19 大流行的第一波,有些国家仍在从第一波中恢复。我们建议使用我们的方法和扩展数据集对未来的浪潮进行仔细评估,而不是直接推断我们的经验结果来为未来的大流行策略提供信息。我们的数据和方法旨在为跟踪情绪健康提供有用的工具。该工具可以支持国际和国家决策者的及时监测和决策。