布隆过滤器,Guava实现布隆过滤器(本地内存),Redis实现布隆过滤器(分布式)
一、前言
利用布隆过滤器可以快速地解决项目中一些比较棘手的问题。如网页 URL 去重、垃圾邮件识别、大集合中重复元素的判断和缓存穿透等问题。不知道从什么时候开始,本来默默无闻的布隆过滤器一下子名声大噪,在面试中面试官问到怎么避免缓存穿透,你的第一反应可能就是布隆过滤器,缓存穿透=布隆过滤器成了标配;
二、简介
布隆过滤器(Bloom Filter)是 1970 年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
1.布隆过滤器的原理:
数据结构:
布隆过滤器它实际上是一个很长的二进制向量和一系列随机映射函数。以Redis中的布隆过滤器实现为例,Redis中的布隆过滤器底层是一个大型位数组(二进制数组)+多个无偏hash函数。
一个大型位数组(二进制数组):

多个无偏hash函数:
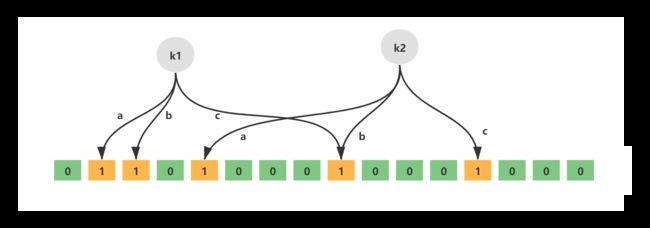
无偏hash函数就是能把元素的hash值计算的比较均匀的hash函数,能使得计算后的元素下标比较均匀的映射到位数组中。如下就是一个简单的布隆过滤器示意图,其中k1、k2代表增加的元素,a、b、c即为无偏hash函数,最下层则为二进制数组。
2.空间计算
在布隆过滤器增加元素之前,首先需要初始化布隆过滤器的空间,也就是上面说的二进制数组,除此之外还需要计算无偏hash函数的个数。布隆过滤器提供了两个参数,分别是预计加入元素的大小n,运行的错误率f。布隆过滤器中有算法根据这两个参数会计算出二进制数组的大小l,以及无偏hash函数的个数k。它们之间的关系比较简单:
错误率越低,位数组越长,控件占用较大
错误率越低,无偏hash函数越多,计算耗时较长
一个免费的在线布隆过滤器在线计算的网址:Bloom Filter Calculator (krisives.github.io)
3.操作
1)增加元素:
往布隆过滤器增加元素,添加的key需要根据k个无偏hash函数计算得到多个hash值,然后对数组长度进行取模得到数组下标的位置,然后将对应数组下标的位置的值置为1;通过k个无偏hash函数计算得到k个hash值,依次取模数组长度,得到数组索引,将计算得到的数组索引下标位置数据修改为1;
例如,key = Liziba,无偏hash函数的个数k=3,分别为hash1、hash2、hash3。三个hash函数计算后得到三个数组下标值,并将其值修改为1;
如图所示:

2)查询元素
布隆过滤器最大的用处就在于判断某样东西一定不存在或者可能存在,而这个就是查询元素的结果。其查询元素的过程如下:
-通过k个无偏hash函数计算得到k个hash值
-依次取模数组长度,得到数组索引
-判断索引处的值是否全部为1,如果全部为1则存在(这种存在可能是误判),如果存在一个0则必定不存在
关于误判,其实非常好理解,hash函数在怎么好,也无法完全避免hash冲突,也就是说可能会存在多个元素计算的hash值是相同的,那么它们取模数组长度后的到的数组索引也是相同的,这就是误判的原因。例如李子捌和李子柒的hash值取模后得到的数组索引都是1,但其实这里只有李子捌,如果此时判断李子柒在不在这里,误判就出现啦!因此布隆过滤器最大的缺点误判只要知道其判断元素是否存在的原理就很容易明白了!
布隆过滤器的优点:
- 时间复杂度低,增加和查询元素的时间复杂为O(N),(N为哈希函数的个数,通常情况比较小)
- 保密性强,布隆过滤器不存储元素本身
- 存储空间小,如果允许存在一定的误判,布隆过滤器是非常节省空间的(相比其他数据结构如Set集合)
布隆过滤器的缺点:
- 有点一定的误判率,但是可以通过调整参数来降低
- 无法获取元素本身
- 很难删除元素
使用场景:
- 解决Redis缓存穿透问题(面试重点)
- 邮件过滤,使用布隆过滤器来做邮件黑名单过滤
- 对爬虫网址进行过滤,爬过的不再爬
- 解决新闻推荐过的不再推荐(类似抖音刷过的往下滑动不再刷到)
- HBase\RocksDB\LevelDB等数据库内置布隆过滤器,用于判断数据是否存在,可以减少数据库的IO请求
三、缓存穿透
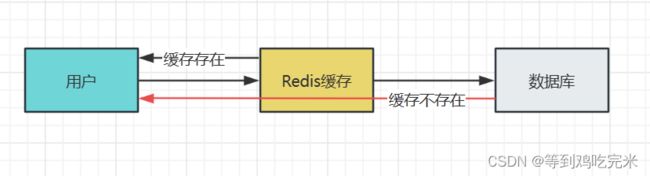
举例说明:
用户可能进行了一次条件错误的查询,这时候redis是不存在的,按照常规流程就是去数据库找了,可是这是一次错误的条件查询,数据库当然也不会存在,也不会往redis里面写值,返回给用户一个空,这样的操作一次两次还好,可是次数多了还了得,我放redis本来就是为了挡一挡,减轻数据库的压力,现在redis变成了形同虚设,每次还是去数据库查找了,这个就叫做缓存穿透;
这相当于redis不存在了,但对于这种情况还是很好解决的;例如,我们可以在redis缓存一个空字符串或者特殊字符串,比如&&,下次我们去redis中查询的时候,当取到的值是空或者&&,我们就知道这个值在数据库中是没有的,就不会在去数据库中查询;(ps:需要注意的是这里缓存不存在key的时候一定要设置过期时间,不然当数据库已经新增了这一条记录的时候,这样会导致缓存和数据库不一致的情况)
除了上面重复查询同一个不存在的值的情况,如果用户每次查询的不存在的值是不一样的呢?即使你每次都缓存特殊字符串也没用,因为它的值不一样,比如我们的数据库用户id是111,112,113,114依次递增,但是别人要攻击你,故意拿-100,-936,-545这种乱七八糟的key来查询,这时候redis和数据库这种值都是不存在的,人家每次拿的key也不一样,你就算缓存了也没用,这时候数据库的压力是相当大,比上面这种情况可怕的多,这怎么办呢,所以说我们今天的主角布隆过滤器就派上用场了;
面试题:
如何在海量元素中(例如 10 亿无序、不定长、不重复)快速判断一个元素是否存在?
我们最简单的想法就是把这么多数据放到数据结构里去,比如List、Map、Tree,一搜不就出来了吗,比如map.get(),我们假设一个元素1个字节的字段,10亿的数据大概需要 900G 的内存空间,这个对于普通的服务器来说是承受不了的;
这里我们就可以用到布隆过滤器,布隆过滤器不存储元素本身,存储空间小,如果允许存在一定的误判,布隆过滤器是非常节省空间的;
四、Guava实现布隆过滤器(本地内存)
引入jar包:
com.google.guava
guava
21.0
测试代码:
这里先往布隆过滤器里面存放100万个元素,然后分别测试100个存在的元素和9900个不存在的元素他们的正确率和误判率
//插入多少数据
private static final int insertions = 1000000;
//期望的误判率
private static double fpp = 0.02;
public static void main(String[] args) {
//初始化一个存储string数据的布隆过滤器,默认误判率是0.03
BloomFilter bf = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8), insertions, fpp);
//用于存放所有实际存在的key,用于是否存在
Set sets = new HashSet(insertions);
//用于存放所有实际存在的key,用于取出
List lists = new ArrayList(insertions);
//插入随机字符串
for (int i = 0; i < insertions; i++) {
String uuid = UUID.randomUUID().toString();
bf.put(uuid);
sets.add(uuid);
lists.add(uuid);
}
int rightNum = 0;
int wrongNum = 0;
for (int i = 0; i < 10000; i++) {
// 0-10000之间,可以被100整除的数有100个(100的倍数)
String data = i % 100 == 0 ? lists.get(i / 100) : UUID.randomUUID().toString();
//这里用了might,看上去不是很自信,所以如果布隆过滤器判断存在了,我们还要去sets中实锤
if (bf.mightContain(data)) {
if (sets.contains(data)) {
rightNum++;
continue;
}
wrongNum++;
}
}
BigDecimal percent = new BigDecimal(wrongNum).divide(new BigDecimal(9900), 2, RoundingMode.HALF_UP);
BigDecimal bingo = new BigDecimal(9900 - wrongNum).divide(new BigDecimal(9900), 2, RoundingMode.HALF_UP);
System.out.println("在100W个元素中,判断100个实际存在的元素,布隆过滤器认为存在的:" + rightNum);
System.out.println("在100W个元素中,判断9900个实际不存在的元素,误认为存在的:" + wrongNum + ",命中率:" + bingo + ",误判率:" + percent);
} 最后得出的结果:
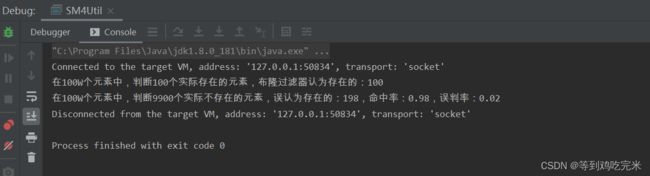
我们看到这个结果正是印证了上面的结论,这100个真实存在元素在布隆过滤器中一定存在,另外9900个不存在的元素,布隆过滤器还是判断了216个存在,这个就是误判,原因上面也说过了,所以布隆过滤器不是万能的,但是它能帮我们抵挡掉大部分不存在的数据已经很不错了,已经减轻数据库很多压力了,另外误判率0.02是在初始化布隆过滤器的时候我们自己设的,如果不设默认是0.03,我们自己设的时候千万不能设0!
五、Redis实现布隆过滤器(分布式)
代码:
/**
* 布隆过滤器核心类
*
* @param
* @author jack xu
*/
public class BloomFilterHelper {
private int numHashFunctions;
private int bitSize;
private Funnel funnel;
public BloomFilterHelper(int expectedInsertions) {
this.funnel = (Funnel) Funnels.stringFunnel(Charset.defaultCharset());
bitSize = optimalNumOfBits(expectedInsertions, 0.03);
numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, bitSize);
}
public BloomFilterHelper(Funnel funnel, int expectedInsertions, double fpp) {
this.funnel = funnel;
bitSize = optimalNumOfBits(expectedInsertions, fpp);
numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, bitSize);
}
public int[] murmurHashOffset(T value) {
int[] offset = new int[numHashFunctions];
long hash64 = Hashing.murmur3_128().hashObject(value, funnel).asLong();
int hash1 = (int) hash64;
int hash2 = (int) (hash64 >>> 32);
for (int i = 1; i <= numHashFunctions; i++) {
int nextHash = hash1 + i * hash2;
if (nextHash < 0) {
nextHash = ~nextHash;
}
offset[i - 1] = nextHash % bitSize;
}
return offset;
}
/**
* 计算bit数组长度
*/
private int optimalNumOfBits(long n, double p) {
if (p == 0) {
p = Double.MIN_VALUE;
}
return (int) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
}
/**
* 计算hash方法执行次数
*/
private int optimalNumOfHashFunctions(long n, long m) {
return Math.max(1, (int) Math.round((double) m / n * Math.log(2)));
}
} 这里在操作redis的位图bitmap,你可能只知道redis五种数据类型,string,list,hash,set,zset,没听过bitmap,但是不要紧,你可以说他是一种新的数据类型,也可以说不是,因为他的本质还是string;
/**
* redis操作布隆过滤器
*
* @param
* @author xhj
*/
public class RedisBloomFilter {
@Autowired
private RedisTemplate redisTemplate;
/**
* 删除缓存的KEY
*
* @param key KEY
*/
public void delete(String key) {
redisTemplate.delete(key);
}
/**
* 根据给定的布隆过滤器添加值,在添加一个元素的时候使用,批量添加的性能差
*
* @param bloomFilterHelper 布隆过滤器对象
* @param key KEY
* @param value 值
* @param 泛型,可以传入任何类型的value
*/
public void add(BloomFilterHelper bloomFilterHelper, String key, T value) {
int[] offset = bloomFilterHelper.murmurHashOffset(value);
for (int i : offset) {
redisTemplate.opsForValue().setBit(key, i, true);
}
}
/**
* 根据给定的布隆过滤器添加值,在添加一批元素的时候使用,批量添加的性能好,使用pipeline方式(如果是集群下,请使用优化后RedisPipeline的操作)
*
* @param bloomFilterHelper 布隆过滤器对象
* @param key KEY
* @param valueList 值,列表
* @param 泛型,可以传入任何类型的value
*/
public void addList(BloomFilterHelper bloomFilterHelper, String key, List valueList) {
redisTemplate.executePipelined(new RedisCallback() {
@Override
public Long doInRedis(RedisConnection connection) throws DataAccessException {
connection.openPipeline();
for (T value : valueList) {
int[] offset = bloomFilterHelper.murmurHashOffset(value);
for (int i : offset) {
connection.setBit(key.getBytes(), i, true);
}
}
return null;
}
});
}
/**
* 根据给定的布隆过滤器判断值是否存在
*
* @param bloomFilterHelper 布隆过滤器对象
* @param key KEY
* @param value 值
* @param 泛型,可以传入任何类型的value
* @return 是否存在
*/
public boolean contains(BloomFilterHelper bloomFilterHelper, String key, T value) {
int[] offset = bloomFilterHelper.murmurHashOffset(value);
for (int i : offset) {
if (!redisTemplate.opsForValue().getBit(key, i)) {
return false;
}
}
return true;
}
} 测试类:
public static void main(String[] args) {
RedisBloomFilter redisBloomFilter = new RedisBloomFilter();
int expectedInsertions = 1000;
double fpp = 0.1;
redisBloomFilter.delete("bloom");
BloomFilterHelper bloomFilterHelper = new BloomFilterHelper<>(Funnels.stringFunnel(Charset.defaultCharset()), expectedInsertions, fpp);
int j = 0;
// 添加100个元素
List valueList = new ArrayList<>();
for (int i = 0; i < 100; i++) {
valueList.add(i + "");
}
long beginTime = System.currentTimeMillis();
redisBloomFilter.addList(bloomFilterHelper, "bloom", valueList);
long costMs = System.currentTimeMillis() - beginTime;
log.info("布隆过滤器添加{}个值,耗时:{}ms", 100, costMs);
for (int i = 0; i < 1000; i++) {
boolean result = redisBloomFilter.contains(bloomFilterHelper, "bloom", i + "");
if (!result) {
j++;
}
}
log.info("漏掉了{}个,验证结果耗时:{}ms", j, System.currentTimeMillis() - beginTime);
} 注意这里用的是addList,它的底层是pipelining管道,而add方法的底层是一个个for循环的setBit,这样的速度效率是很慢的,但是他能有返回值,知道是否插入成功,而pipelining是不知道的,所以具体选择用哪一种方法看你的业务场景,以及需要插入的速度决定;
六、布隆过滤器工作位置
第一步是将数据库所有的数据加载到布隆过滤器;
第二步当有请求来的时候先去布隆过滤器查询,如果bf说没有;
第三步直接返回。如果bf说有,在往下走之前的流程;
