stargan v2 代码学习记录
一、Generator
(1) lamda python
lambda函数也叫匿名函数,即,函数没有具体的名称。
lambda和普通的函数相比,就是省去了函数名称而已,同时这样的匿名函数,又不能共享在别的地方调用。
其实说的没错,lambda在Python这种动态的语言中确实没有起到什么惊天动地的作用,因为有很多别的方法能够代替lambda。
1. 使用Python写一些执行脚本时,使用lambda可以省去定义函数的过程,让代码更加精简。
2. 对于一些抽象的,不会别的地方再复用的函数,有时候给函数起个名字也是个难题,使用lambda不需要考虑命名的问题。
3. 使用lambda在某些时候让代码更容易理解。
lambda语句中,冒号前是参数,可以有多个,用逗号隔开,冒号右边的返回值。lambda语句构建的其实是一个函数对象
(2)random.random()用于生成一个0到1的随机符点数: 0 <= n < 1.0
(3)ImageFolder假设所有的文件按文件夹保存,每个文件夹下存储同一个类别的图片,文件夹名为类名,既默认你的数据集已经自觉按照要分配的类型分成了不同的文件夹,一种类型的文件夹下面只存放一种类型的图片。
这篇博客写得很详细
还有这篇,这篇
(3)source:dataset: female17943 + male 10057 = 28000
(4) _make_balanced_sampler
np.bincount()
图文结合,形象,在这里用作数0和1的数量,也就是,female和male的图片张数,也就是17943和10057
这是class_counts


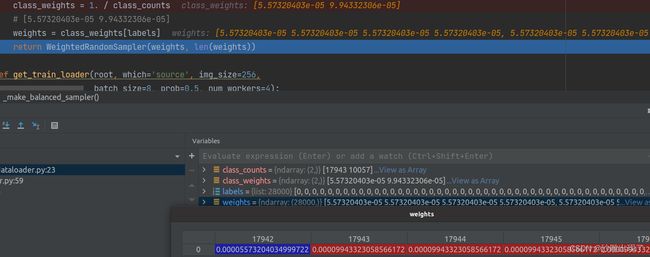 weights (list)每张图片的比重,要么5.57320403e-05,要么9.94332306e-05
weights (list)每张图片的比重,要么5.57320403e-05,要么9.94332306e-05
作用:关键看WeightRandomSampler函数,样本不均衡情况下带权重随机采样:大概意思就是本来数量上占最少的样本,给他的数量取个倒数作为权重,那么越小的权重越大,采样的时候就按照这个权重来取,就可以达到样本均衡了。具体看这个链接
(5)register_buffer
PyTorch中定义模型时,有时候会遇到self.register_buffer('name', Tensor)的操作,该方法的作用是定义一组参数,该组参数的特别之处在于:模型训练时不会更新(即调用 optimizer.step() 后该组参数不会变化,只可人为地改变它们的值),但是保存模型时,该组参数又作为模型参数不可或缺的一部分被保存。
(6) tensor.repeat() 看这一篇就够了
Pytorch Tensor.repeat()的简单用法_xiongxyowo的博客-CSDN博客
(7) 对于hpf的一些测试
import torch
filter = torch.tensor([[-1, -1, -1],
[-1, 8., -1],
[-1, -1, -1]])/1
a = filter.unsqueeze(0) #按照第0维度扩展,也就是行扩展
b = filter.unsqueeze(0).unsqueeze(1)
c = filter.unsqueeze(0).unsqueeze(1).repeat(3, 1, 1, 1)
print("origin:", filter)
print("a: {}, a.shape = {}".format(a, a.shape))
print("b: {}, b.shape = {}".format(b, b.shape))
print("c: {}, c.shape = {}".format(c, c.shape))origin: tensor([[-1., -1., -1.],
[-1., 8., -1.],
[-1., -1., -1.]])
a: tensor([[[-1., -1., -1.],
[-1., 8., -1.],
[-1., -1., -1.]]]), a.shape = torch.Size([1, 3, 3])
b: tensor([[[[-1., -1., -1.],
[-1., 8., -1.],
[-1., -1., -1.]]]]), b.shape = torch.Size([1, 1, 3, 3])
c: tensor([[[[-1., -1., -1.],
[-1., 8., -1.],
[-1., -1., -1.]]],
[[[-1., -1., -1.],
[-1., 8., -1.],
[-1., -1., -1.]]],
[[[-1., -1., -1.],
[-1., 8., -1.],
[-1., -1., -1.]]]]), c.shape = torch.Size([3, 1, 3, 3])
Process finished with exit code 0
可以这样理解:nn.Conved是2D卷积层,而F.conv2d是2D卷积操作。
import torch
from torch.nn import functional as F
"""手动定义卷积核(weight)和偏置"""
w = torch.rand(16, 3, 5, 5) # 16种3通道的5乘5卷积核
b = torch.rand(16) # 和卷积核种类数保持一致(不同通道共用一个bias)
"""定义输入样本"""
x = torch.randn(1, 3, 28, 28) # 1张3通道的28乘28的图像
"""2D卷积得到输出"""
out = F.conv2d(x, w, b, stride=1, padding=1) # 步长为1,外加1圈padding,即上下左右各补了1圈的0,
print(out.shape)
out = F.conv2d(x, w, b, stride=2, padding=2) # 步长为2,外加2圈padding
print(out.shape)
out = F.conv2d(x, w) # 步长为1,默认不padding, 不够的舍弃,所以对于28*28的图片来说,算完之后变成了24*24
print(out.shape)
numpy与tensor之间的转换
view,squeeze,unsqueeze,
import torch
import torch.nn.functional as F
import torch.nn as nn
import cv2 as cv
from torchvision import transforms
from PIL import Image
import numpy as np
from matplotlib import pyplot as plt
class HighPass(nn.Module):
def __init__(self, w_hpf, device):
super(HighPass, self).__init__()
self.register_buffer('filter',
torch.tensor([[-1, -1, -1],
[-1, 8., -1],
[-1, -1, -1]]) / w_hpf)
def forward(self, x):
filter = self.filter.unsqueeze(0).unsqueeze(1).repeat(x.size(1), 1, 1, 1)
return F.conv2d(x, filter, padding=1, groups=x.size(1))
img_numpy = cv.imread('/home/zsq/D/stargan-v2-master/assets/representative/celeba_hq/ref/female/015248.jpg')
#[1024, 1024, 3] HWC BGR
img2 = cv.resize(img_numpy, (256, 256))
cv.imwrite("img2.jpg", img2)
img2 = torch.tensor(img2).float()
#[256, 256, 3]
img2 = img2.permute(2, 1, 0)
img2 = img2.unsqueeze(0)
hpf = HighPass(1,'gpu')
img3 = hpf(img2)
img3 = img3.squeeze(0).permute(2, 1, 0).numpy()
print(img3.shape)
cv.imwrite("img3.jpg", img3)

由此可见HighPass是一个边缘提取网络
F.interpolate——数组采样操作
换句话说就是科学合理地改变数组的尺寸大小,尽量保持数据完整。
在计算机视觉中,interpolate函数常用于图像的放大(即上采样操作)。比如在细粒度识别领域中,注意力图有时候会对特征图进行裁剪操作,将有用的部分裁剪出来,裁剪后的图像往往尺寸小于原始特征图,这时候如果强制转换成原始图像大小,往往是无效的,会丢掉部分有用的信息。所以这时候就需要用到interpolate函数对其进行上采样操作,在保证图像信息不丢失的情况下,放大图像,从而放大图像的细节,有利于进一步的特征提取工作。
二、MappingNetwork
(1)注意 out = [ ] out += layer 与 out += [layer] 的区别
(2)torch.stack()的用法torch.stack()的官方解释,详解以及例子_xinjieyuan的博客-CSDN博客_torch.stack()
torch.stack()的使用_朝花&夕拾-CSDN博客_torch.stack()
np.stack()函数详解 ==>堆叠 【类似于torch.stack()】_马鹏森的博客-CSDN博客
(3)深拷贝:我们寻常意义的复制就是深复制,即将被复制对象完全再复制一遍作为独立的新个体单独存在。所以改变原有被复制对象不会对已经复制出来的新对象产生影响。
三、Solver
(1)Munch 继承了字典
python munch包的使用(可以将字典替换为这个包)_小兜全糖(Cx)的博客-CSDN博客_munch python
(2)当传入字典形式的参数时,就要使用**kwargs。
(3)如果要判断两个类型是否相同推荐使用 isinstance()。
(4)Path().rglob()可以递归地遍历文件
fnames = list(chain(*[list(Path(dname).rglob('*.' + ext))
for ext in ['png', 'jpg', 'jpeg', 'JPG']]))四、dataloader
(1) 关于魔术方法,__next__
① 魔术方法就是一个类中的方法,和普通方法唯一的不同是普通方法需要调用,而魔术方法是在特定时刻自动触发。
② 这些魔术方法的名字特定,不能更改,但是入口参数的名字可以自己命名。
面向对象(三)|python类的魔术方法 - 知乎
- dataloader本质是一个可迭代对象,使用iter()访问,不能使用next()访问;
- 使用iter(dataloader)返回的是一个迭代器,然后可以使用next访问;
- 也可以使用`for inputs, labels in dataloaders`进行可迭代对象的访问;
(2)ImageFolder
对应source的dataset函数使用torchvision.datasets.ImageFolder产生。数据集CelebA HQ的文件夹包括female 和male 两个folder,folder下为对应的文件,因而该dataset函数返回为(x,y)对应取出来的图像以及其对应的domain标签。
(3)class torchvision.transforms.ToTensor
把shape=(H x W x C) 的像素值为 [0, 255] 的 PIL.Image 和 numpy.ndarray
转换成shape=(C x H x W)的像素值范围为[0.0, 1.0]的 torch.FloatTensor。
(4)代码里边的next(loader)那边的debug的时候出错误,看不懂什么意思
五、数据加载
(1)source => 把所有图片按照transforms改变,然后放在ImageFolder里
(2)reference => 在每个域中:第一个是顺序的图片名,第二个是打乱的图片名字,labels对应域
return img, img2, label(3)均衡采样,使样本变得均衡,最后制作成数据集
def _make_balanced_sampler(labels):
class_counts = np.bincount(labels)
class_weights = 1. / class_counts
weights = class_weights[labels]
return WeightedRandomSampler(weights, len(weights))六、train代码
(1)fill_value 就是给定一个值fill_value和一个size,创建一个矩阵元素全为fill_value的大小为size的tensor
(2)logits就是最终的全连接层的输出,而非其本意。通常神经网络中都是先有logits,而后通过sigmoid函数或者softmax函数得到概率 的,所以大部分情况下都无需用到logit函数的表达式。